

【搜索客社区日报】第1999期 (2025-03-10)
https://blog.csdn.net/2301_808 ... 04715
2、活动回顾 - 第7期 搜索客 Meetup 线上直播活动圆满结束,附视频回放
https://elasticsearch.cn/article/15398
3、DeepSeekの食用指南:在腾讯云LKE厨房里,我们把AI炖成了一锅会写彩虹屁的佛跳墙
https://blog.csdn.net/2301_808 ... 10524
4、Elasticsearch 如何实现按特定时间档次和相关度排序的定制查询?
https://mp.weixin.qq.com/s/oboqrfKTvfhJDiTyA_3B_A
5、实测 Manus:DeepSeek 之后,AI 又点了一把火
https://blog.csdn.net/csdnnews ... .5927
编辑:Muse
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/2301_808 ... 04715
2、活动回顾 - 第7期 搜索客 Meetup 线上直播活动圆满结束,附视频回放
https://elasticsearch.cn/article/15398
3、DeepSeekの食用指南:在腾讯云LKE厨房里,我们把AI炖成了一锅会写彩虹屁的佛跳墙
https://blog.csdn.net/2301_808 ... 10524
4、Elasticsearch 如何实现按特定时间档次和相关度排序的定制查询?
https://mp.weixin.qq.com/s/oboqrfKTvfhJDiTyA_3B_A
5、实测 Manus:DeepSeek 之后,AI 又点了一把火
https://blog.csdn.net/csdnnews ... .5927
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2001期 (2025-03-12)
https://blog.csdn.net/UbuntuTo ... 76560
2. Elasticsearch:过滤 HNSW 搜索,快速模式
https://blog.csdn.net/UbuntuTo ... 19180
3. 选择正确的AI Agent框架:LangGraph vs CrewAI vs OpenAI Swarm
https://zhuanlan.zhihu.com/p/18555531485
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 76560
2. Elasticsearch:过滤 HNSW 搜索,快速模式
https://blog.csdn.net/UbuntuTo ... 19180
3. 选择正确的AI Agent框架:LangGraph vs CrewAI vs OpenAI Swarm
https://zhuanlan.zhihu.com/p/18555531485
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2000期 (2025-03-11)
1. ELK实时监控的最佳实践(需要梯子)
https://medium.com/%40jeromede ... f0469
2. 用Rag释放商业潜能(需要梯子)
https://medium.com/%40anirudhs ... 211b8
3. 拿足球数据集来给大家讲讲ES、AI结合(需要梯子)
https://medium.com/%40rahul.fi ... cb940
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. ELK实时监控的最佳实践(需要梯子)
https://medium.com/%40jeromede ... f0469
2. 用Rag释放商业潜能(需要梯子)
https://medium.com/%40anirudhs ... 211b8
3. 拿足球数据集来给大家讲讲ES、AI结合(需要梯子)
https://medium.com/%40rahul.fi ... cb940
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
活动回顾 - 第7期 搜索客 Meetup 线上直播活动圆满结束,附 PPT 下载与视频回放
2025 年 03 月 07 日,由搜索客社区和极限科技(INFINI Labs)联合举办的第 7 期线上 Meetup 技术交流直播活动圆满结束。本期 Meetup 直播活动吸引了超过 700+ 技术爱好者观看参与,活动主要介绍了极限科技新推出并正在研发的开源智能搜索产品 Coco AI 的技术特点和应用场景,并探讨了如何通过 AI 等技术提高企业内部协作的效率和智能化程度。

本期 Meetup 活动回顾
本期 Meetup 活动的分享嘉宾是 极限科技(INFINI Labs)创始人和 CEO 曾勇老师(Medcl) ,Medcl 在搜索技术领域有着丰富的经验和深厚的积累,致力于下一代搜索引擎和智能 AI 搜索领域相关技术的研究。他为大家带来了主题为 《开源智能搜索与知识库管理 - Coco AI》 精彩分享。

Medcl 首先介绍了极限科技的成立背景和主要业务。极限科技成立于 2021 年底,致力于为企业提供国产化的搜索工具和产品。其中,Coco AI 是极限科技最近推出的一款开源智能搜索产品,旨在为用户提供更加便捷、高效的搜索体验。

Medcl 详细介绍了 Coco AI 的产品架构和功能特点。Coco AI 采用分布式架构,支持多种数据源连接和异构数据的整合。同时,它还集成了 AI 技术,能够实现智能问答、意图识别等功能,帮助用户更加高效地获取所需信息。
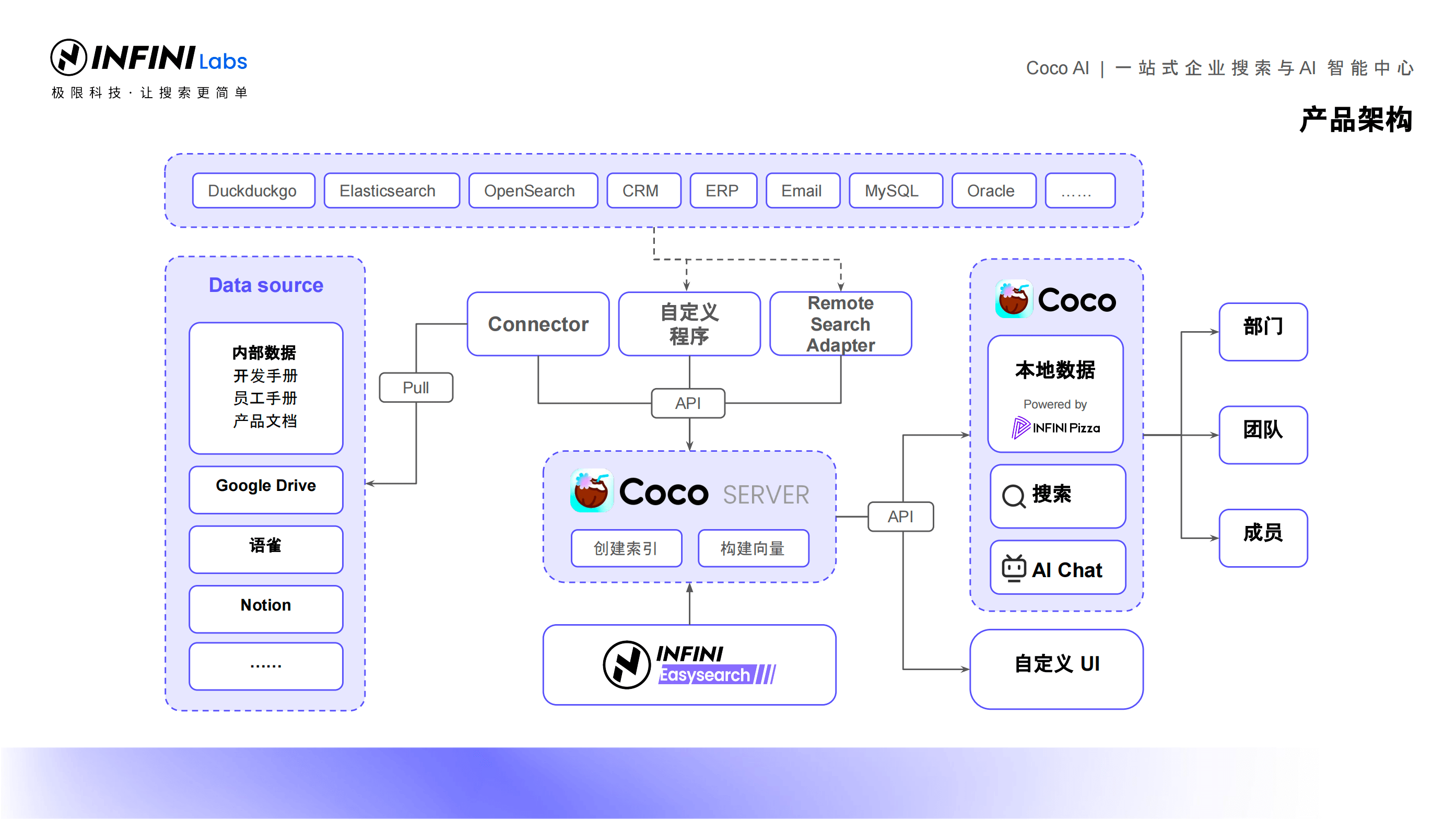
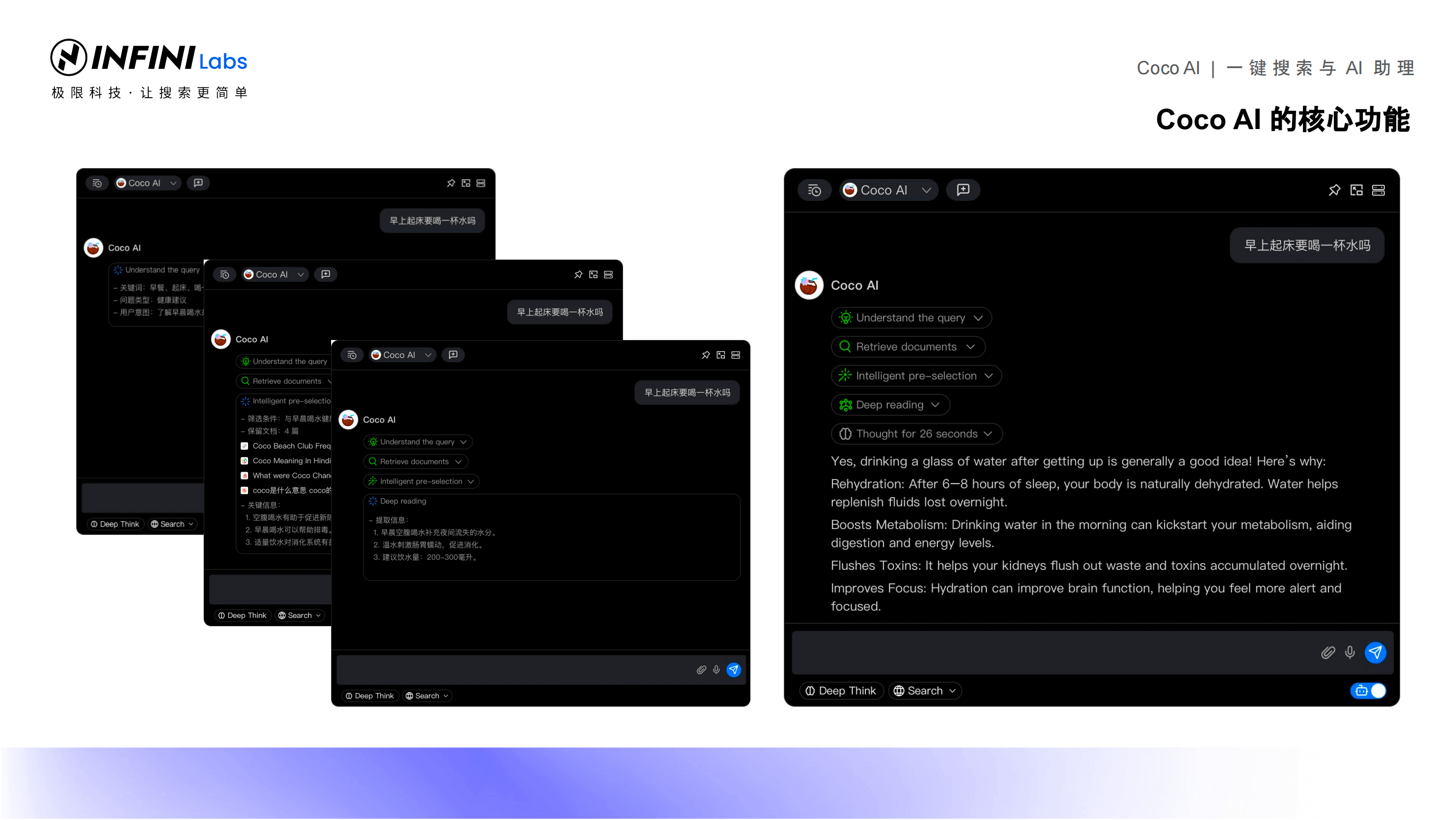
在 Medcl 的演示中,我们看到了 Coco AI 的实际应用效果。通过简单的配置和操作,用户可以轻松地连接各种数据源,并实现快速检索和智能问答。同时,Coco AI 还支持多种操作系统和设备,为用户提供了更加便捷的使用体验。
在活动的互动环节中,观众们积极提问,Medcl 耐心解答了关于 Coco AI 的技术细节和应用场景等问题。下面摘取部分问答:
问 1:Coco AI 的架构图中有提到 Pizza,Pizza 是向量数据库吗?
答:Pizza 是极限科技即将推出的下一代搜索引擎,既包含全文检索的能力,也包含向量检索能力。问 2: Coco AI App 的 windows 版本啥时候开放下载体验?
答:已开放下载,下载地址:https://coco.rs/,欢迎体验和反馈!问 3: 幻觉问题有解决方案吗,试了很多款 RAG 开源项目,还有云服务,都没有特别好的方式
答:大模型幻觉问题可通过多阶段处理和提示词设计优化:先快速识别意图并筛选信息,再提取可靠资料,最后用高精度模型生成答案,耗时较长但准确性高;同时提示模型在依据不足时回答“缺少信息”,避免无意义输出。这种分层处理方式有效减少幻觉问题,提升可靠性。问 4: Coco 怎么做数据源的更新的 🤔
答:Coco AI 的数据源更新方式灵活多样:1.定期更新,通过 Connect 定期按频率更新数据;2.主动推送,支持业务方主动推送数据或结合消息通知,实现部分更新;3.接口支持,提供接口接收推送数据,实时检索更新,适应多种数据场景。问 5: Coco 的数据源是否计划支持飞书云文档?
答:飞书云文档我们本身是有计划的,因为飞书云文档我们也有在用的我们。支持起来的话也很快。
同时,在整个直播过程中,主持人进行了多轮激动人心的抽奖活动,为参会小伙伴带来了额外的惊喜。
最后感谢大家的参与和支持,让我们共同期待下一次 搜索客 Meetup 活动带来更多的精彩内容!
本期 Meetup 的 PPT 下载
本期 PPT 下载的链接:https://searchkit.cn/slides/331
本期 Meetup 视频回放
扫码关注极限实验室视频号查看直播回放,或者扫码关注极限实验室 B 站 账号,可查看本期 Meetup 活动视频。我们也会在视频号、B 站持续更新最新技术视频,欢迎通过点赞、投币,收藏,三连来支持我们。

Meetup 活动讲师招募

搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!

Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
关于 搜索客(SearchKit)社区
搜索客社区由 Elasticsearch 中文社区进行全新的品牌升级,以新的 Slogan:“搜索人自己的社区” 为宣言。汇集搜索领域最新动态、精选干货文章、精华讨论、文档资料、翻译与版本发布等,为广大搜索领域从业者提供更为丰富便捷的学习和交流平台。社区官网:https://searchkit.cn 。
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
2025 年 03 月 07 日,由搜索客社区和极限科技(INFINI Labs)联合举办的第 7 期线上 Meetup 技术交流直播活动圆满结束。本期 Meetup 直播活动吸引了超过 700+ 技术爱好者观看参与,活动主要介绍了极限科技新推出并正在研发的开源智能搜索产品 Coco AI 的技术特点和应用场景,并探讨了如何通过 AI 等技术提高企业内部协作的效率和智能化程度。
本期 Meetup 活动回顾
本期 Meetup 活动的分享嘉宾是 极限科技(INFINI Labs)创始人和 CEO 曾勇老师(Medcl) ,Medcl 在搜索技术领域有着丰富的经验和深厚的积累,致力于下一代搜索引擎和智能 AI 搜索领域相关技术的研究。他为大家带来了主题为 《开源智能搜索与知识库管理 - Coco AI》 精彩分享。
Medcl 首先介绍了极限科技的成立背景和主要业务。极限科技成立于 2021 年底,致力于为企业提供国产化的搜索工具和产品。其中,Coco AI 是极限科技最近推出的一款开源智能搜索产品,旨在为用户提供更加便捷、高效的搜索体验。
Medcl 详细介绍了 Coco AI 的产品架构和功能特点。Coco AI 采用分布式架构,支持多种数据源连接和异构数据的整合。同时,它还集成了 AI 技术,能够实现智能问答、意图识别等功能,帮助用户更加高效地获取所需信息。
在 Medcl 的演示中,我们看到了 Coco AI 的实际应用效果。通过简单的配置和操作,用户可以轻松地连接各种数据源,并实现快速检索和智能问答。同时,Coco AI 还支持多种操作系统和设备,为用户提供了更加便捷的使用体验。
在活动的互动环节中,观众们积极提问,Medcl 耐心解答了关于 Coco AI 的技术细节和应用场景等问题。下面摘取部分问答:
问 1:Coco AI 的架构图中有提到 Pizza,Pizza 是向量数据库吗?
答:Pizza 是极限科技即将推出的下一代搜索引擎,既包含全文检索的能力,也包含向量检索能力。问 2: Coco AI App 的 windows 版本啥时候开放下载体验?
答:已开放下载,下载地址:https://coco.rs/,欢迎体验和反馈!问 3: 幻觉问题有解决方案吗,试了很多款 RAG 开源项目,还有云服务,都没有特别好的方式
答:大模型幻觉问题可通过多阶段处理和提示词设计优化:先快速识别意图并筛选信息,再提取可靠资料,最后用高精度模型生成答案,耗时较长但准确性高;同时提示模型在依据不足时回答“缺少信息”,避免无意义输出。这种分层处理方式有效减少幻觉问题,提升可靠性。问 4: Coco 怎么做数据源的更新的 🤔
答:Coco AI 的数据源更新方式灵活多样:1.定期更新,通过 Connect 定期按频率更新数据;2.主动推送,支持业务方主动推送数据或结合消息通知,实现部分更新;3.接口支持,提供接口接收推送数据,实时检索更新,适应多种数据场景。问 5: Coco 的数据源是否计划支持飞书云文档?
答:飞书云文档我们本身是有计划的,因为飞书云文档我们也有在用的我们。支持起来的话也很快。
同时,在整个直播过程中,主持人进行了多轮激动人心的抽奖活动,为参会小伙伴带来了额外的惊喜。
最后感谢大家的参与和支持,让我们共同期待下一次 搜索客 Meetup 活动带来更多的精彩内容!
本期 Meetup 的 PPT 下载
本期 PPT 下载的链接:https://searchkit.cn/slides/331
本期 Meetup 视频回放
扫码关注极限实验室视频号查看直播回放,或者扫码关注极限实验室 B 站 账号,可查看本期 Meetup 活动视频。我们也会在视频号、B 站持续更新最新技术视频,欢迎通过点赞、投币,收藏,三连来支持我们。
Meetup 活动讲师招募
搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!
Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
关于 搜索客(SearchKit)社区
搜索客社区由 Elasticsearch 中文社区进行全新的品牌升级,以新的 Slogan:“搜索人自己的社区” 为宣言。汇集搜索领域最新动态、精选干货文章、精华讨论、文档资料、翻译与版本发布等,为广大搜索领域从业者提供更为丰富便捷的学习和交流平台。社区官网:https://searchkit.cn 。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »如何使用 DataX 连接 Easysearch
DataX
DataX 是阿里开源的一款离线数据同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
本篇主要介绍 DataX 如何将数据写入到 Easysearch,对于各种数据源的连接不会做深入的探讨,感兴趣的小伙伴可以访问 DataX 的 Github 仓库查看详情。
下载与安装
DataX 无需安装,下载后解压即可使用。
系统需求:
- JDK 1.8 及以上
- Python2 或 3
创建任务配置文件
每个数据同步的操作可称为一个任务,任务的配置文件定义了数据源(reader)、数据目的(writer) ,以及任务的设置信息,如并发数、速度控制等。DataX 集成了如此多的数据源,如果靠纯手工编写任务配置显然不现实。官方也出了个命令可以根据指定的数据源和数据目的帮助大家生成任务配置。
python datax.py -r {YOUR_READER} -w {YOUR_WRITER}测试配置文件
此次演示使用 streamreader 和 elasticsearchwriter 作为数据源和数据目的,任务配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10000,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
},
{
"type": "string",
"value": "hello,你好,Easysearch"
}
]
}
},
"writer": {
"name": "elasticsearchwriter",
"parameter": {
"endpoint": "http://localhost:9200",
"accessId": "admin",
"accessKey": "1ef0c661d8562aaa06be",
"index": "yf-test",
"column": [
{ "name": "no", "type": "long" },
{ "name": "content", "type": "keyword" },
{ "name": "content2", "type": "keyword" }
]
}
}
}
],
"setting": {
"speed": {
"channel": 50
}
}
}
}streamreader 是一个从内存读取数据的插件, 它主要用来快速生成期望的数据并对写入插件进行测试。
我们用 streamreader 构造了 10000 个文档,文档含三个字段,任务启动了 50 个 channel 进行数据发送,结果就是共计发送 50w 个文档。
elasticssearchwriter 指定了 Easysearch 的连接信息:
- endpoint: Easysearch 的地址和端口
- accessId: 用户名
- accessKey: 密码
- index: 写入索引名
- column: 对 reader 发来数据的 schema 定义
- batchsize: 默认 1000
这次我们 Easysearch 开启的 http 服务,因为 DataX 的 elasticsearchwriter 无法跳过证书验证。对于必须使用 https 的场景,可使用 INFINI Gateway 代理 ES 服务,提供 http 通道给离线数据同步专用。
⚠️ 注意:
不同的 reader、writer 对 sliceRecordCount 和 channel 会有不同的行为。
Easysearch
本次测试使用的 Easysearch 版本是 1.9.0,需要注意是 Easysearch 要开启兼容性参数:
elasticsearch.api_compatibility: true否则创建索引报错退出。(实际索引创建成功了但是 mapping 信息是空的)

运行任务
编辑好任务配置文件后,下一步就是执行任务。
python3 datax.py yf-test.json
写入数据时索引不存在,Datax 根据 schema 定义创建了索引。

OK 任务执行完毕,写入 50w 个文档耗时 10 秒。
如果有其他问题欢迎与我联系。

DataX
DataX 是阿里开源的一款离线数据同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
本篇主要介绍 DataX 如何将数据写入到 Easysearch,对于各种数据源的连接不会做深入的探讨,感兴趣的小伙伴可以访问 DataX 的 Github 仓库查看详情。
下载与安装
DataX 无需安装,下载后解压即可使用。
系统需求:
- JDK 1.8 及以上
- Python2 或 3
创建任务配置文件
每个数据同步的操作可称为一个任务,任务的配置文件定义了数据源(reader)、数据目的(writer) ,以及任务的设置信息,如并发数、速度控制等。DataX 集成了如此多的数据源,如果靠纯手工编写任务配置显然不现实。官方也出了个命令可以根据指定的数据源和数据目的帮助大家生成任务配置。
python datax.py -r {YOUR_READER} -w {YOUR_WRITER}测试配置文件
此次演示使用 streamreader 和 elasticsearchwriter 作为数据源和数据目的,任务配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10000,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
},
{
"type": "string",
"value": "hello,你好,Easysearch"
}
]
}
},
"writer": {
"name": "elasticsearchwriter",
"parameter": {
"endpoint": "http://localhost:9200",
"accessId": "admin",
"accessKey": "1ef0c661d8562aaa06be",
"index": "yf-test",
"column": [
{ "name": "no", "type": "long" },
{ "name": "content", "type": "keyword" },
{ "name": "content2", "type": "keyword" }
]
}
}
}
],
"setting": {
"speed": {
"channel": 50
}
}
}
}streamreader 是一个从内存读取数据的插件, 它主要用来快速生成期望的数据并对写入插件进行测试。
我们用 streamreader 构造了 10000 个文档,文档含三个字段,任务启动了 50 个 channel 进行数据发送,结果就是共计发送 50w 个文档。
elasticssearchwriter 指定了 Easysearch 的连接信息:
- endpoint: Easysearch 的地址和端口
- accessId: 用户名
- accessKey: 密码
- index: 写入索引名
- column: 对 reader 发来数据的 schema 定义
- batchsize: 默认 1000
这次我们 Easysearch 开启的 http 服务,因为 DataX 的 elasticsearchwriter 无法跳过证书验证。对于必须使用 https 的场景,可使用 INFINI Gateway 代理 ES 服务,提供 http 通道给离线数据同步专用。
⚠️ 注意:
不同的 reader、writer 对 sliceRecordCount 和 channel 会有不同的行为。
Easysearch
本次测试使用的 Easysearch 版本是 1.9.0,需要注意是 Easysearch 要开启兼容性参数:
elasticsearch.api_compatibility: true否则创建索引报错退出。(实际索引创建成功了但是 mapping 信息是空的)
运行任务
编辑好任务配置文件后,下一步就是执行任务。
python3 datax.py yf-test.json
写入数据时索引不存在,Datax 根据 schema 定义创建了索引。
OK 任务执行完毕,写入 50w 个文档耗时 10 秒。
如果有其他问题欢迎与我联系。
【搜索客社区日报】第1998期 (2025-03-07)
https://mp.weixin.qq.com/s/eS45qqzXs9WzXmWMurNwvQ
2.实测 Manus:首个真干活 AI,中国造(附50个用例 + 拆解)
https://mp.weixin.qq.com/s/P47F8KE7SPRdUpODcnKKhQ
3.Manus工作原理揭秘:解构下一代AI Agent的多智能体架构
https://mp.weixin.qq.com/s/Hr5Ljp7BMsYA0CqU1YI1CA
4.INFINI Labs 产品更新 | Easysearch 增加异步搜索等新特性
https://infinilabs.cn/blog/2025/release-20250228/
5.Easysearch 节点磁盘不足应对方法
https://infinilabs.cn/blog/202 ... odes/
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/eS45qqzXs9WzXmWMurNwvQ
2.实测 Manus:首个真干活 AI,中国造(附50个用例 + 拆解)
https://mp.weixin.qq.com/s/P47F8KE7SPRdUpODcnKKhQ
3.Manus工作原理揭秘:解构下一代AI Agent的多智能体架构
https://mp.weixin.qq.com/s/Hr5Ljp7BMsYA0CqU1YI1CA
4.INFINI Labs 产品更新 | Easysearch 增加异步搜索等新特性
https://infinilabs.cn/blog/2025/release-20250228/
5.Easysearch 节点磁盘不足应对方法
https://infinilabs.cn/blog/202 ... odes/
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
使用 INFINI Gateway 保护 Elasticsearch 集群之阻断不合理的查询
本文将探讨如何使用 INFINI Gateway 阻止不合理的查询发送到 Elasticsearch,此方法同样适用于 Opensearch 和 Easysearch 。
在以往处理 Elasticsearch OOM(内存溢出)问题的经验中,我们发现许多案例是由于查询操作导致节点出现 OOM 的情况。经过调查,这些案例主要分为两类:一类是由于查询吞吐量超出了集群的处理能力,另一类则是在执行某些不合理的查询时触发了 OOM。
具体来说:
- 查询吞吐量过高:当查询请求的频率或复杂度超过了集群的处理能力时,可能会导致节点内存耗尽,从而引发 OOM。
- 执行不合理查询:某些特殊类型的查询(例如涉及大量嵌套、深度分页或复杂的聚合操作)可能需要大量的内存资源,在执行过程中也可能导致 OOM。
通过识别并优化这些查询模式,可以有效减少 OOM 事件的发生。针对查询吞吐量过高的情况,可以参考之前的文章来管理查询吞吐。接下来的内容将介绍如何阻挡不合理查询,保护集群稳定。
不合理查询
不合理查询是指那些消耗过多系统资源(如 CPU、内存)、设计复杂、执行时间过长或需要大量计算资源的查询。这类查询不仅会导致高负载和资源耗尽,影响整个集群的稳定性和响应速度,还可能对用户体验产生负面影响。
典型的不合理查询包括但不限于:
- 嵌套聚合查询
- 使用复杂的正则表达式进行模糊匹配
- 深度分页查询(如 from: 10000, size: 10)
- 脚本查询(Script Query)
- 大规模嵌套聚合查询
为了防止这些查询对 Elasticsearch 集群造成影响,我们可以使用 INFINI Gateway 对这些查询进行阻断。
请求上下文
INFINI Gateway 运行环境中有非常多的信息可被利用,而请求上下文就是访问这些信息的入口。如请求来源、请求体信息等,都可使用关键字 _ctx 作为前缀访问相应的上下文信息。
HTTP 请求内置的 _ctx 上下文对象主要包括如下:

更多的上下文信息请访问文档。
context_filter
Context Filter 是 INFINI Gateway 提供的一种在线过滤器,能够根据请求上下文来过滤流量。通过定义一组匹配规则,可以灵活地对流量进行筛选。该过滤器支持多种匹配模式,包括:
- 前缀匹配
- 后缀匹配
- 模糊匹配
- 正则匹配
对于匹配到的请求,可以直接阻断(拒绝)并返回自定义的消息。因此,关键点就是要明确不合理请求的关键字信息。
使用步骤
- 确定关键字信息:确定特殊查询请求中的关键特征或关键字。
- 配置匹配规则:在 context_filter 中定义相应的匹配规则,选择合适的匹配模式(如前缀、后缀、模糊或正则匹配)。
- 阻断请求:一旦匹配到这些关键字,INFINI Gateway 将自动阻断请求并返回指定的消息。
更多详细内容,请参阅相关 文档。
举个例子
阻止 wildcard 查询(模糊匹配查询),我们先看一个 wildcard 查询的样子。
GET yf-test-1shard/_search
{
"query": {
"wildcard": {
"path.keyword": {
"value": "/a*"
}
}
}
}上面的查询,会查询 path 字段,所有以 /a 开头的文档。

第一步:我们可确定关键字是 wildcard,为了进一步限制是 wildcard 查询里的情况,我们可将关键字确定为 wildcard":,因为有时候查询 url 里会有 expand_wildcards 字样。
第二步:编辑 INFINI Gateway 默认配置文件,增加 context_filter 匹配规则。
- name: default_flow
filter:
- context_filter:
context: _ctx.request.to_string
message: "Request blocked. Reason: Forbidden. Please contact the administrator at 010-111111."
status: 403
action: deny
must_not:
contain:
- 'wildcard":'通过上面的修改,我们在 INFINI Gatway 的默认处理流程开头添加了 context_filter 过滤器,阻止查询请求种带关键字 wildcard": 的查询,并返回消息"Request blocked. Reason: Forbidden. Please contact the administrator at 010-111111."
第三步,测试 wildcard 请求能否被阻断。

可以看到,INFINI Gateway 成功阻止了 wildcard 查询,并返回了我们定义的信息。通过此方法,我们可以阻断高消耗类查询被发送到 ES 集群,避免引发集群性能问题。对业务上合理的需求,我们可以进一步沟通,确定合理的方案。
关于极限网关(INFINI Gateway)

INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
开源地址:https://github.com/infinilabs/gateway,如有相关问题或建议,欢迎提交 PR 或 Issue !
作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
本文将探讨如何使用 INFINI Gateway 阻止不合理的查询发送到 Elasticsearch,此方法同样适用于 Opensearch 和 Easysearch 。
在以往处理 Elasticsearch OOM(内存溢出)问题的经验中,我们发现许多案例是由于查询操作导致节点出现 OOM 的情况。经过调查,这些案例主要分为两类:一类是由于查询吞吐量超出了集群的处理能力,另一类则是在执行某些不合理的查询时触发了 OOM。
具体来说:
- 查询吞吐量过高:当查询请求的频率或复杂度超过了集群的处理能力时,可能会导致节点内存耗尽,从而引发 OOM。
- 执行不合理查询:某些特殊类型的查询(例如涉及大量嵌套、深度分页或复杂的聚合操作)可能需要大量的内存资源,在执行过程中也可能导致 OOM。
通过识别并优化这些查询模式,可以有效减少 OOM 事件的发生。针对查询吞吐量过高的情况,可以参考之前的文章来管理查询吞吐。接下来的内容将介绍如何阻挡不合理查询,保护集群稳定。
不合理查询
不合理查询是指那些消耗过多系统资源(如 CPU、内存)、设计复杂、执行时间过长或需要大量计算资源的查询。这类查询不仅会导致高负载和资源耗尽,影响整个集群的稳定性和响应速度,还可能对用户体验产生负面影响。
典型的不合理查询包括但不限于:
- 嵌套聚合查询
- 使用复杂的正则表达式进行模糊匹配
- 深度分页查询(如 from: 10000, size: 10)
- 脚本查询(Script Query)
- 大规模嵌套聚合查询
为了防止这些查询对 Elasticsearch 集群造成影响,我们可以使用 INFINI Gateway 对这些查询进行阻断。
请求上下文
INFINI Gateway 运行环境中有非常多的信息可被利用,而请求上下文就是访问这些信息的入口。如请求来源、请求体信息等,都可使用关键字 _ctx 作为前缀访问相应的上下文信息。
HTTP 请求内置的 _ctx 上下文对象主要包括如下:
更多的上下文信息请访问文档。
context_filter
Context Filter 是 INFINI Gateway 提供的一种在线过滤器,能够根据请求上下文来过滤流量。通过定义一组匹配规则,可以灵活地对流量进行筛选。该过滤器支持多种匹配模式,包括:
- 前缀匹配
- 后缀匹配
- 模糊匹配
- 正则匹配
对于匹配到的请求,可以直接阻断(拒绝)并返回自定义的消息。因此,关键点就是要明确不合理请求的关键字信息。
使用步骤
- 确定关键字信息:确定特殊查询请求中的关键特征或关键字。
- 配置匹配规则:在 context_filter 中定义相应的匹配规则,选择合适的匹配模式(如前缀、后缀、模糊或正则匹配)。
- 阻断请求:一旦匹配到这些关键字,INFINI Gateway 将自动阻断请求并返回指定的消息。
更多详细内容,请参阅相关 文档。
举个例子
阻止 wildcard 查询(模糊匹配查询),我们先看一个 wildcard 查询的样子。
GET yf-test-1shard/_search
{
"query": {
"wildcard": {
"path.keyword": {
"value": "/a*"
}
}
}
}上面的查询,会查询 path 字段,所有以 /a 开头的文档。
第一步:我们可确定关键字是 wildcard,为了进一步限制是 wildcard 查询里的情况,我们可将关键字确定为 wildcard":,因为有时候查询 url 里会有 expand_wildcards 字样。
第二步:编辑 INFINI Gateway 默认配置文件,增加 context_filter 匹配规则。
- name: default_flow
filter:
- context_filter:
context: _ctx.request.to_string
message: "Request blocked. Reason: Forbidden. Please contact the administrator at 010-111111."
status: 403
action: deny
must_not:
contain:
- 'wildcard":'通过上面的修改,我们在 INFINI Gatway 的默认处理流程开头添加了 context_filter 过滤器,阻止查询请求种带关键字 wildcard": 的查询,并返回消息"Request blocked. Reason: Forbidden. Please contact the administrator at 010-111111."
第三步,测试 wildcard 请求能否被阻断。
可以看到,INFINI Gateway 成功阻止了 wildcard 查询,并返回了我们定义的信息。通过此方法,我们可以阻断高消耗类查询被发送到 ES 集群,避免引发集群性能问题。对业务上合理的需求,我们可以进一步沟通,确定合理的方案。
关于极限网关(INFINI Gateway)
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
开源地址:https://github.com/infinilabs/gateway,如有相关问题或建议,欢迎提交 PR 或 Issue !
收起阅读 »作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
Easysearch 写入限速实战
有给 ES 系统导入过数据的小伙伴都知道,给一个正在执行查询的 ES 集群导入数据,可能会影响查询的响应时间。如果导入的数据量还比较大,那请将“可能”两个字去掉。这种操作通常被限定在业务低谷期执行,如果一定要立即操作,则必须非常小心控制写入速度,避免影响到业务查询。
INFINI Easysearch 从 1.8.0 版本开始引入了写入限速功能,靠引擎自身能力对写入速度进行限制。不仅听着简单,实际用起来一点也不麻烦,我们赶紧实战一把。
测试环境
INFINI Easyssearch 1.9.0,单节点集群。
测试方法
loadgen 压测 bulk 写入,每个请求写 1000 个文档,每次测试固定写入 500w 个文档。
./loadgen-linux-amd64 -config ../config/write-yf-test.yml -d 3000 -l 5000请求示例
{"index": {"_index": "yf-test-1shard","_id": "$[[uuid]]"}}
{"ip": "127.0.0.1", "time": "$[[now_utc_lite]]", "method": "GET","path": "/abc", "http_ver": "1.1", "status_code": "200","body_bytes": "3498","agent": "curl","agent_ver": "7.71.1"}测试基线
单节点不限速写入测试
压测单个索引,3 主,0 副,写入速度 3.8w docs/s

压测单个索引,1 主,0 副,写入速度 2.5w docs/s

同时压测两个索引,写入速度分别是 3w docs/s 和 1.8w docs/s

节点级别限速
基于引擎层实现的限速功能,支持动态开启。比如我想将节点每秒写入的文档数,限制在 10000 个每秒,直接这样设置:
PUT _cluster/settings
{
"transient": {
"cluster.throttle.node.write": true
"cluster.throttle.node.write.max_requests": 10000,
"cluster.throttle.node.write.action": "retry"
}
}压测单个索引,1 主,0 副,写入速度 1w docs/s

压测单个索引,3 主,0 副,写入速度 1w docs/s

由于是限制整个节点的速度,不论索引分片如何,节点的写入上限被限制在了 10000 个文档每秒。节点上的所有分片共享节点的写入限额。
同时压测两个索引,整个节点写入速度还是 10000 个文档每秒。由于我的压测程序对两个索引的写入量是一样的,所以两个索引各占一半。实际上如果两个索引写入压力不一样,就会有高低。

节点级限速适合对节点写入极限比较清楚的条件下,想在节点层面保障集群稳定,不想细分到具体索引的场景。
索引级别限速
索引级的限速可以针对特定索引进行写入限速,避免响其他索引的读写。在之前的不限速测试中,同时写入两个索引的情况下,yf-test-3shard 能达到每秒近 3w docs/s 的写入速度,另一个索引 yf-test-1shard 能达到每秒近 1.8w docs/s 的写入速度。
接下来,我们只对 yf-test-3shard 进行限速。在索引的设置里配置相应的限流阈值:
PUT yf-test-3shard/_settings
{
"index.throttle.write.max_requests": 2000,
"index.throttle.write.action": "retry",
"index.throttle.write.enable": true
}限速设置在索引设置里查看到。

设置完限速后同时压测两个索引,yf-test-3shard 索引被限制在了 2000 docs/s 的速度,yf-test-1shard 则有更多的资源写入,达到了 2.3w docs/s 的写入速度,比之前不限速的时候稍高。

通过索引级限速功能,我们成功地限制了索引 yf-test-3shard 的写入速度,索引 yf-test-1shard 的写入并未受到影响。
分片级别限速
分片级限流功能,可限定单个分片允许最大写入速度。它不针对哪个索引,而是针对所有分片。比如我想限制每个分片每秒最多写 2000 个文档。
PUT _cluster/settings
{
"transient": {
"cluster.throttle.shard.write": true,
"cluster.throttle.shard.write.max_requests": 2000,
"cluster.throttle.shard.write.action": "retry"
}
}压测单个索引,1 主,0 副
1 个分片,写入速度 2000 个文档每秒。

压测单个索引,3 主,0 副
3 个分片,写入速度 6000 个文档每秒。

不论是哪个索引,全都限定一个分片 2000 的写入速度。我想这种限速比较适合一个集群中有高低配置混搭主机的场景,高配机器性能强悍,磁盘空间也大,分布的分片也多;低配主机性能和磁盘容量都有限,分布的分片数较少。你们说呢?
注意事项
节点级别限流是针对所有 DataNode。
分片级别限流只计算从协调节点分发到数据节点主分片的 bulk 请求。
节点级别和分片级别限流不冲突,可以同时启用。
限流功能不会限制系统索引流量,只针对业务索引。
有给 ES 系统导入过数据的小伙伴都知道,给一个正在执行查询的 ES 集群导入数据,可能会影响查询的响应时间。如果导入的数据量还比较大,那请将“可能”两个字去掉。这种操作通常被限定在业务低谷期执行,如果一定要立即操作,则必须非常小心控制写入速度,避免影响到业务查询。
INFINI Easysearch 从 1.8.0 版本开始引入了写入限速功能,靠引擎自身能力对写入速度进行限制。不仅听着简单,实际用起来一点也不麻烦,我们赶紧实战一把。
测试环境
INFINI Easyssearch 1.9.0,单节点集群。
测试方法
loadgen 压测 bulk 写入,每个请求写 1000 个文档,每次测试固定写入 500w 个文档。
./loadgen-linux-amd64 -config ../config/write-yf-test.yml -d 3000 -l 5000请求示例
{"index": {"_index": "yf-test-1shard","_id": "$[[uuid]]"}}
{"ip": "127.0.0.1", "time": "$[[now_utc_lite]]", "method": "GET","path": "/abc", "http_ver": "1.1", "status_code": "200","body_bytes": "3498","agent": "curl","agent_ver": "7.71.1"}测试基线
单节点不限速写入测试
压测单个索引,3 主,0 副,写入速度 3.8w docs/s
压测单个索引,1 主,0 副,写入速度 2.5w docs/s
同时压测两个索引,写入速度分别是 3w docs/s 和 1.8w docs/s
节点级别限速
基于引擎层实现的限速功能,支持动态开启。比如我想将节点每秒写入的文档数,限制在 10000 个每秒,直接这样设置:
PUT _cluster/settings
{
"transient": {
"cluster.throttle.node.write": true
"cluster.throttle.node.write.max_requests": 10000,
"cluster.throttle.node.write.action": "retry"
}
}压测单个索引,1 主,0 副,写入速度 1w docs/s
压测单个索引,3 主,0 副,写入速度 1w docs/s
由于是限制整个节点的速度,不论索引分片如何,节点的写入上限被限制在了 10000 个文档每秒。节点上的所有分片共享节点的写入限额。
同时压测两个索引,整个节点写入速度还是 10000 个文档每秒。由于我的压测程序对两个索引的写入量是一样的,所以两个索引各占一半。实际上如果两个索引写入压力不一样,就会有高低。
节点级限速适合对节点写入极限比较清楚的条件下,想在节点层面保障集群稳定,不想细分到具体索引的场景。
索引级别限速
索引级的限速可以针对特定索引进行写入限速,避免响其他索引的读写。在之前的不限速测试中,同时写入两个索引的情况下,yf-test-3shard 能达到每秒近 3w docs/s 的写入速度,另一个索引 yf-test-1shard 能达到每秒近 1.8w docs/s 的写入速度。
接下来,我们只对 yf-test-3shard 进行限速。在索引的设置里配置相应的限流阈值:
PUT yf-test-3shard/_settings
{
"index.throttle.write.max_requests": 2000,
"index.throttle.write.action": "retry",
"index.throttle.write.enable": true
}限速设置在索引设置里查看到。
设置完限速后同时压测两个索引,yf-test-3shard 索引被限制在了 2000 docs/s 的速度,yf-test-1shard 则有更多的资源写入,达到了 2.3w docs/s 的写入速度,比之前不限速的时候稍高。
通过索引级限速功能,我们成功地限制了索引 yf-test-3shard 的写入速度,索引 yf-test-1shard 的写入并未受到影响。
分片级别限速
分片级限流功能,可限定单个分片允许最大写入速度。它不针对哪个索引,而是针对所有分片。比如我想限制每个分片每秒最多写 2000 个文档。
PUT _cluster/settings
{
"transient": {
"cluster.throttle.shard.write": true,
"cluster.throttle.shard.write.max_requests": 2000,
"cluster.throttle.shard.write.action": "retry"
}
}压测单个索引,1 主,0 副
1 个分片,写入速度 2000 个文档每秒。
压测单个索引,3 主,0 副
3 个分片,写入速度 6000 个文档每秒。
不论是哪个索引,全都限定一个分片 2000 的写入速度。我想这种限速比较适合一个集群中有高低配置混搭主机的场景,高配机器性能强悍,磁盘空间也大,分布的分片也多;低配主机性能和磁盘容量都有限,分布的分片数较少。你们说呢?
注意事项
节点级别限流是针对所有 DataNode。
分片级别限流只计算从协调节点分发到数据节点主分片的 bulk 请求。
节点级别和分片级别限流不冲突,可以同时启用。
限流功能不会限制系统索引流量,只针对业务索引。
收起阅读 »【搜索客社区日报】第1997期 (2025-03-06)
https://mp.weixin.qq.com/s/1Cz7oQbVkPMam3eoKQWz0w
2.DeepSearcher深度解读:Agentic RAG的出现,传统RAG的黄昏
https://mp.weixin.qq.com/s/N-oPDmkb3EKqB2IM_reO1A
3.LangGraph全新4大预构建Agents框架登场
https://mp.weixin.qq.com/s/4WU-c9hYWwvEZLvC91coVw
4.超越Cursor的AI编码利器 - Windsurf编码代理实战教程
https://www.bilibili.com/video/BV1KHPJeNEgx
5.开源大模型食用指南
https://github.com/datawhalechina/self-llm
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/1Cz7oQbVkPMam3eoKQWz0w
2.DeepSearcher深度解读:Agentic RAG的出现,传统RAG的黄昏
https://mp.weixin.qq.com/s/N-oPDmkb3EKqB2IM_reO1A
3.LangGraph全新4大预构建Agents框架登场
https://mp.weixin.qq.com/s/4WU-c9hYWwvEZLvC91coVw
4.超越Cursor的AI编码利器 - Windsurf编码代理实战教程
https://www.bilibili.com/video/BV1KHPJeNEgx
5.开源大模型食用指南
https://github.com/datawhalechina/self-llm
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1996期 (2025-03-05)
https://cloud.tencent.com.cn/d ... 97467
2.解读向量索引
https://cloud.tencent.com.cn/d ... 64186
3.幻方:萤火高速读写文件系统(3FS)概述
https://mp.weixin.qq.com/s/qKRioV45IbOq91XDsUEIcg
编辑:kin122
更多资讯:http://news.searchkit.cn
https://cloud.tencent.com.cn/d ... 97467
2.解读向量索引
https://cloud.tencent.com.cn/d ... 64186
3.幻方:萤火高速读写文件系统(3FS)概述
https://mp.weixin.qq.com/s/qKRioV45IbOq91XDsUEIcg
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1995期 (2025-03-04)
https://medium.com/%40mehmetca ... 3477e
2. 聊聊我所知道的ES全文检索(需要梯子)
https://ngnthilakshan.medium.c ... e525b
3. 客官,K8S里来一套EFK吗?(需要梯子)
https://medium.com/devops-dev/ ... 37468
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40mehmetca ... 3477e
2. 聊聊我所知道的ES全文检索(需要梯子)
https://ngnthilakshan.medium.c ... e525b
3. 客官,K8S里来一套EFK吗?(需要梯子)
https://medium.com/devops-dev/ ... 37468
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1994期 (2025-03-03)
https://infinilabs.cn/blog/2025/setprocessor-bug/
2. Easysearch 新功能: IK 字段级别词典
https://infinilabs.cn/blog/202 ... arys/
3. Easysearch 磁盘水位线注意事项
https://infinilabs.cn/blog/202 ... tips/
4. Elasticsearch 中 _count 和 _stats 文档数量不一致的困惑与解决方案
https://mp.weixin.qq.com/s/8Ux7PDCoP2NMjvV6ikMxqA
5. 深度学习五大模型:CNN、Transformer、BERT、RNN、GAN详细解析
https://blog.csdn.net/2301_811 ... 27624
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/2025/setprocessor-bug/
2. Easysearch 新功能: IK 字段级别词典
https://infinilabs.cn/blog/202 ... arys/
3. Easysearch 磁盘水位线注意事项
https://infinilabs.cn/blog/202 ... tips/
4. Elasticsearch 中 _count 和 _stats 文档数量不一致的困惑与解决方案
https://mp.weixin.qq.com/s/8Ux7PDCoP2NMjvV6ikMxqA
5. 深度学习五大模型:CNN、Transformer、BERT、RNN、GAN详细解析
https://blog.csdn.net/2301_811 ... 27624
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
INFINI Labs 产品更新 | Easysearch 增加异步搜索等新特性

INFINI Labs 产品更新发布!此次更新,Easysearch 增加了新的功能和数据类型,包括 wildcard 数据类型、Point in time 搜索 API、异步搜索 API、数值和日期字段的 doc-values 搜索支持,Console 新增了日志查询功能。
INFINI Easysearch v1.11.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
- 新增 wildcard 数据类型
- 新增 Point in time 搜索 API
- 新增异步搜索 API
- 数值字段添加 doc-values 搜索支持
- 日期字段添加 doc-values 搜索支持
- 新增 IK 分词器自定义词典使用文档
优化改进
- 优化 Lucene flush 的 segment 大小,减少 I/O 开销
INFINI Console v1.29.0
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验:
http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
功能更新
- 监控(集群、节点)新增日志查询

问题修复
- 修复指标数据为空时的查询错误
- 修复初始化结束步骤中主机显示为错误的问题
- 修复数据探索中获取字段值建议的错误
- 修复告警消息热图数据显示错误的问题
- 修复开发工具 _sql 查询支撑 Elasticsearch 6.x 版本
- 修复审计日志默认排序翻页之后丢失的问题
- 修复 Mapping 冲突问题
优化改进
- 优化下发给 Agent 的配置,增加集群名称
- 优化柱状图和时间选择器的 UI
- 集群,节点,索引健康状态变更支持查看日志
- 增强 LDAP 身份验证的日志记录
- 优化监控报表里拷贝指标请求的 UI
- 删除索引提示增加集群信息
INFINI Gateway v1.29.0
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
问题修复
- 同步更新 Framework v1.1.3 修复的一些已知问题
INFINI Agent v1.29.0
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
问题修复
- 同步更新 Framework v1.1.3 修复的一些已知问题
INFINI Loadgen v1.29.0
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
问题修复
- 同步更新 Framework v1.1.3 修复的一些已知问题
INFINI Framework v1.1.3
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
功能更新
- 允许注册在应用程序设置之前执行的函数(#84)
- 添加用于安全处理 JSON 的工具(#85)
问题修复
- 修复了无生产者的消费者分段问题(#89)
- 在代理未启用时禁用默认代理(#91)
优化改进
- 规范化 HTTP 错误响应结构(#86)
- 在 WebSocket 欢迎消息中引入系统类型(#87)
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新发布!此次更新,Easysearch 增加了新的功能和数据类型,包括 wildcard 数据类型、Point in time 搜索 API、异步搜索 API、数值和日期字段的 doc-values 搜索支持,Console 新增了日志查询功能。
INFINI Easysearch v1.11.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
- 新增 wildcard 数据类型
- 新增 Point in time 搜索 API
- 新增异步搜索 API
- 数值字段添加 doc-values 搜索支持
- 日期字段添加 doc-values 搜索支持
- 新增 IK 分词器自定义词典使用文档
优化改进
- 优化 Lucene flush 的 segment 大小,减少 I/O 开销
INFINI Console v1.29.0
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验:
http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
功能更新
- 监控(集群、节点)新增日志查询
问题修复
- 修复指标数据为空时的查询错误
- 修复初始化结束步骤中主机显示为错误的问题
- 修复数据探索中获取字段值建议的错误
- 修复告警消息热图数据显示错误的问题
- 修复开发工具 _sql 查询支撑 Elasticsearch 6.x 版本
- 修复审计日志默认排序翻页之后丢失的问题
- 修复 Mapping 冲突问题
优化改进
- 优化下发给 Agent 的配置,增加集群名称
- 优化柱状图和时间选择器的 UI
- 集群,节点,索引健康状态变更支持查看日志
- 增强 LDAP 身份验证的日志记录
- 优化监控报表里拷贝指标请求的 UI
- 删除索引提示增加集群信息
INFINI Gateway v1.29.0
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
问题修复
- 同步更新 Framework v1.1.3 修复的一些已知问题
INFINI Agent v1.29.0
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
问题修复
- 同步更新 Framework v1.1.3 修复的一些已知问题
INFINI Loadgen v1.29.0
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
问题修复
- 同步更新 Framework v1.1.3 修复的一些已知问题
INFINI Framework v1.1.3
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
功能更新
- 允许注册在应用程序设置之前执行的函数(#84)
- 添加用于安全处理 JSON 的工具(#85)
问题修复
- 修复了无生产者的消费者分段问题(#89)
- 在代理未启用时禁用默认代理(#91)
优化改进
- 规范化 HTTP 错误响应结构(#86)
- 在 WebSocket 欢迎消息中引入系统类型(#87)
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第1993期 (2025-02-27)
https://www.elastic.co/search- ... dding
2.别搞Graph RAG了,拥抱新一代RAG范式DeepSearcher
https://mp.weixin.qq.com/s/gLyaLhWWDj1WoDSxEwpT6Q
3.帮你整理好了,AI 网关的8个常见应用场景
https://mp.weixin.qq.com/s/TGOB0WRrxcOXcmg_uJCuyA
4.字节跳动开源 AIBrix:专为 vLLM 打造的可扩展、高性价比控制面
https://mp.weixin.qq.com/s/DSU3jRDCYSakW6eVp0x8mA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://www.elastic.co/search- ... dding
2.别搞Graph RAG了,拥抱新一代RAG范式DeepSearcher
https://mp.weixin.qq.com/s/gLyaLhWWDj1WoDSxEwpT6Q
3.帮你整理好了,AI 网关的8个常见应用场景
https://mp.weixin.qq.com/s/TGOB0WRrxcOXcmg_uJCuyA
4.字节跳动开源 AIBrix:专为 vLLM 打造的可扩展、高性价比控制面
https://mp.weixin.qq.com/s/DSU3jRDCYSakW6eVp0x8mA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【第7期】搜索客 Meetup | 开源智能搜索与知识库管理,极限科技 Coco AI 产品介绍
本次活动由 搜索客社区、极限科技(INFINI Labs)联合举办,活动邀请到 INFINI Labs 创始人& CEO 曾勇 来分享和演示极限科技最新推出的开源搜索产品 Coco AI ,欢迎预约直播观看 ~
活动主题:开源智能搜索与知识库管理,极限科技 Coco AI 产品介绍
活动时间:2025 年 03 月 07 日 19:00-20:00(周五)
活动形式:微信视频号(极限实验室)直播
报名方式:关注或扫码海报中的二维码进行预约

嘉宾介绍
曾勇,极限科技 / INFINI Labs 创始人& CEO,前 Elastic 亚太区社区布道师,Elastic 中国区咨询业务负责人,Elasticsearch 中文社区(现搜索客)的发起人兼社区主席,目前带领团队致力于下一代实时搜索引擎与 AI 智能搜索等相关技术的研究。
主题摘要
在快速发展的人工智能时代,个人和企业对知识库管理的需求愈发迫切。有没有一个轻量级,简单,又开源免费, 高效、智能且可定制的 AI 搜索与知识库管理工具呢?
本次分享将为您详细介绍 Coco AI —— 由极限科技推出的完全开源免费的智能搜索与知识库管理工具,不仅适用于个人,也适用于企业分享知识,这次分享将为您详细介绍 Coco AI,并探讨如何利用人工智能技术和开源架构,实现智能搜索和知识管理的全面优化。
主要内容
- 开源智能搜索技术:
- 介绍开源搜索引擎与人工智能技术的结合,如何提升搜索精度和智能化水平。
- 展示 Coco AI 的智能搜索与 AI 助理功能,帮助个人或者企业实现精准的搜索与知识库管理。
- Coco AI 产品介绍:
- 详细讲解 Coco AI 的开源架构,如何帮助企业或个人快速构建智能搜索引擎并进行知识管理。
- 强调其灵活性和定制化能力,支持跨平台和跨系统的数据整合。
- 智能知识库管理:
- 探讨 Coco AI 如何通过搜索与 AI, RAG 等技术进行自动化分类、索引与语义理解,提升知识库的管理效率。
- 展示 Coco AI 在实际企业中的应用,如何打破信息孤岛,实现智能化的知识共享。
- 开源生态与发展:
- 介绍 Coco AI 的开源生态,如何通过社区合作和持续创新推动技术发展。
- 展望开源智能搜索的未来,如何通过新兴技术推动知识管理创新。
Coco AI 已经对外正式开源和下载, 下面是相关地址, 可以先睹为快, 欢迎 Star 转发分享~
项目网站:
开源地址:
参与有奖
本次直播活动将设有福袋抽奖环节,参与就有机会获得 INFINI Labs 周边纪念品,包括 T 恤、鸭舌帽、咖啡杯、指甲刀套件、精品围巾等等(图片仅供参考,款式、颜色与尺码随机)。

活动交流
本活动设有 Meetup 技术交流群,可添加小助手微信拉群,与更多小伙伴一起学习交流。

Meetup 讲师招募
搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!

Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
往期回顾
- 【第 6 期】搜索客 Meetup | Easysearch 请求限速漫谈
- 【第 5 期】搜索客 Meetup | 最强开源 Elasticsearch 多集群管理工具 INFINI Console 动手实战
- 【第 4 期】搜索客 Meetup | INFINI Pizza 网站 SVG 动画这么炫,我教你啊!
- 【第 3 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 下篇
- 【第 2 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 上篇
- 【第 1 期】搜索客 Meetup | Easysearch 结合大模型实现 RAG
本次活动由 搜索客社区、极限科技(INFINI Labs)联合举办,活动邀请到 INFINI Labs 创始人& CEO 曾勇 来分享和演示极限科技最新推出的开源搜索产品 Coco AI ,欢迎预约直播观看 ~
活动主题:开源智能搜索与知识库管理,极限科技 Coco AI 产品介绍
活动时间:2025 年 03 月 07 日 19:00-20:00(周五)
活动形式:微信视频号(极限实验室)直播
报名方式:关注或扫码海报中的二维码进行预约
嘉宾介绍
曾勇,极限科技 / INFINI Labs 创始人& CEO,前 Elastic 亚太区社区布道师,Elastic 中国区咨询业务负责人,Elasticsearch 中文社区(现搜索客)的发起人兼社区主席,目前带领团队致力于下一代实时搜索引擎与 AI 智能搜索等相关技术的研究。
主题摘要
在快速发展的人工智能时代,个人和企业对知识库管理的需求愈发迫切。有没有一个轻量级,简单,又开源免费, 高效、智能且可定制的 AI 搜索与知识库管理工具呢?
本次分享将为您详细介绍 Coco AI —— 由极限科技推出的完全开源免费的智能搜索与知识库管理工具,不仅适用于个人,也适用于企业分享知识,这次分享将为您详细介绍 Coco AI,并探讨如何利用人工智能技术和开源架构,实现智能搜索和知识管理的全面优化。
主要内容
- 开源智能搜索技术:
- 介绍开源搜索引擎与人工智能技术的结合,如何提升搜索精度和智能化水平。
- 展示 Coco AI 的智能搜索与 AI 助理功能,帮助个人或者企业实现精准的搜索与知识库管理。
- Coco AI 产品介绍:
- 详细讲解 Coco AI 的开源架构,如何帮助企业或个人快速构建智能搜索引擎并进行知识管理。
- 强调其灵活性和定制化能力,支持跨平台和跨系统的数据整合。
- 智能知识库管理:
- 探讨 Coco AI 如何通过搜索与 AI, RAG 等技术进行自动化分类、索引与语义理解,提升知识库的管理效率。
- 展示 Coco AI 在实际企业中的应用,如何打破信息孤岛,实现智能化的知识共享。
- 开源生态与发展:
- 介绍 Coco AI 的开源生态,如何通过社区合作和持续创新推动技术发展。
- 展望开源智能搜索的未来,如何通过新兴技术推动知识管理创新。
Coco AI 已经对外正式开源和下载, 下面是相关地址, 可以先睹为快, 欢迎 Star 转发分享~
项目网站:
开源地址:
参与有奖
本次直播活动将设有福袋抽奖环节,参与就有机会获得 INFINI Labs 周边纪念品,包括 T 恤、鸭舌帽、咖啡杯、指甲刀套件、精品围巾等等(图片仅供参考,款式、颜色与尺码随机)。
活动交流
本活动设有 Meetup 技术交流群,可添加小助手微信拉群,与更多小伙伴一起学习交流。
Meetup 讲师招募
搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!
Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
往期回顾
- 【第 6 期】搜索客 Meetup | Easysearch 请求限速漫谈
- 【第 5 期】搜索客 Meetup | 最强开源 Elasticsearch 多集群管理工具 INFINI Console 动手实战
- 【第 4 期】搜索客 Meetup | INFINI Pizza 网站 SVG 动画这么炫,我教你啊!
- 【第 3 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 下篇
- 【第 2 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 上篇
- 【第 1 期】搜索客 Meetup | Easysearch 结合大模型实现 RAG

