

谈谈 ES 6.8 到 7.10 的功能变迁(1)- 性能优化篇
前言
ES 7.10 可能是现在比较常见的 ES 版本。但是对于一些相迭代比较慢的早期业务系统来说,ES 6.8 是一个名副其实的“钉子户”。
借着工作内升级调研的任务东风,我整理从 ES 6.8 到 ES 7.10 ELastic 重点列出的新增功能和优化内容。将分为 6 个篇幅给大家详细阐述。
本系列文章主要针对 Elasticsearch 传统的使用功能和基础的模块,像是集群任务的管理、搜索、聚合还有字段类型这样的功能。对于付费功能或者全新的模块,比如:CCR、机器学习和数据流,这里不去深入探讨。
内容的主要来源于 Elastic 各个版本的发布信息,这里主要比对 ES 6.8 版本到 7.10 版本的差异,并不一一枚举各个新的功能点出现的时间版本。
下面是第一篇:关于 ES 性能的优化
ES 7.10 的性能优化
集群协调算法升级
基于 Elastic 博客提供的资料,Elasticsearch 7.0 的核心改进在于集群协调层的彻底重构,取代了旧版 Zen Discovery 的局限性,引入更健壮、自动化的分布式共识机制。从理论上来说这次优化有着不少的进步,可以显著提升了高可用性与运维效率
主要的优化点有下面三点:
-
消除分裂脑(Split Brain)风险:通过自动化计算,确保集群状态更新的安全性。旧版
minimum_master_nodes的手动配置被移除,避免人为误操作。 -
提升集群稳定性与恢复速度:节点故障时,集群更快达成一致,减少服务中断窗口。
- 简化运维复杂度:可以动态扩缩容无需手动调整配置,系统自动管理选举配置。同时提供更清晰的日志和错误提示,加速故障诊断。
| 旧版配置 | ES 7.0 配置 | 作用 |
|---|---|---|
discovery.zen.ping.unicast.hosts |
discovery.seed_hosts |
定义初始发现的种子节点列表(IP 或主机名) |
discovery.zen.minimum_master_nodes |
已移除 | 由系统自动管理法定人数 |
而在优化的原则里,Elastic 更强调安全第一。比如,在半数以上主节点永久丢失的风险场景下,ES 7.0 之前的集群会静默等待恢复,允许通过启动新空节点强制恢复,这样可能会导致数据不一致或丢失。在 Elasticsearch 7.0 以及更高版本中,这种不安全活动受到了更多限制。集群宁愿保持不可用状态,也不会冒这种风险(除非使用 elasticsearch-node 恢复工具)。
这次优化显著降低了人为错误的风险:移除脆弱的手动配置,减少运维使用的理解成本。同时提升关键业务连续性:快速故障恢复与明确的容错机制,能适合更多场景需求。
当然也并不是尽善尽美的,也会存在大集群下投票节点过多导致竞争激烈而无法选主的问题,这种情况下,建议部署独立的主节点,并且可以考虑适当增大 cluster.election.duration 的配置。
Top K 对检索的加速
这里的 Top K 主要是指在普通检索时展示前列的数据 Top K。也就是说 Elasticsearch 7.0 对检索数据的查询性能做了明显的改善。那是做了所有查询场景的提升么?
ELastic 做了这么一个场景假设:如果用户通常只关注搜索结果的第一页,且并不关心具体匹配的文档总数,对于超出一定数量的数据搜索引擎可以展示“超过 10,000 条结果”并提供分页浏览来优化搜索效率。但是在实际过程中用户常在查询中使用高频词(如“the”或“a”),这迫使 Elasticsearch 为大量文档计算评分,明显占用了查询资源的使用,即使这些常见词对相关性排序贡献甚微。
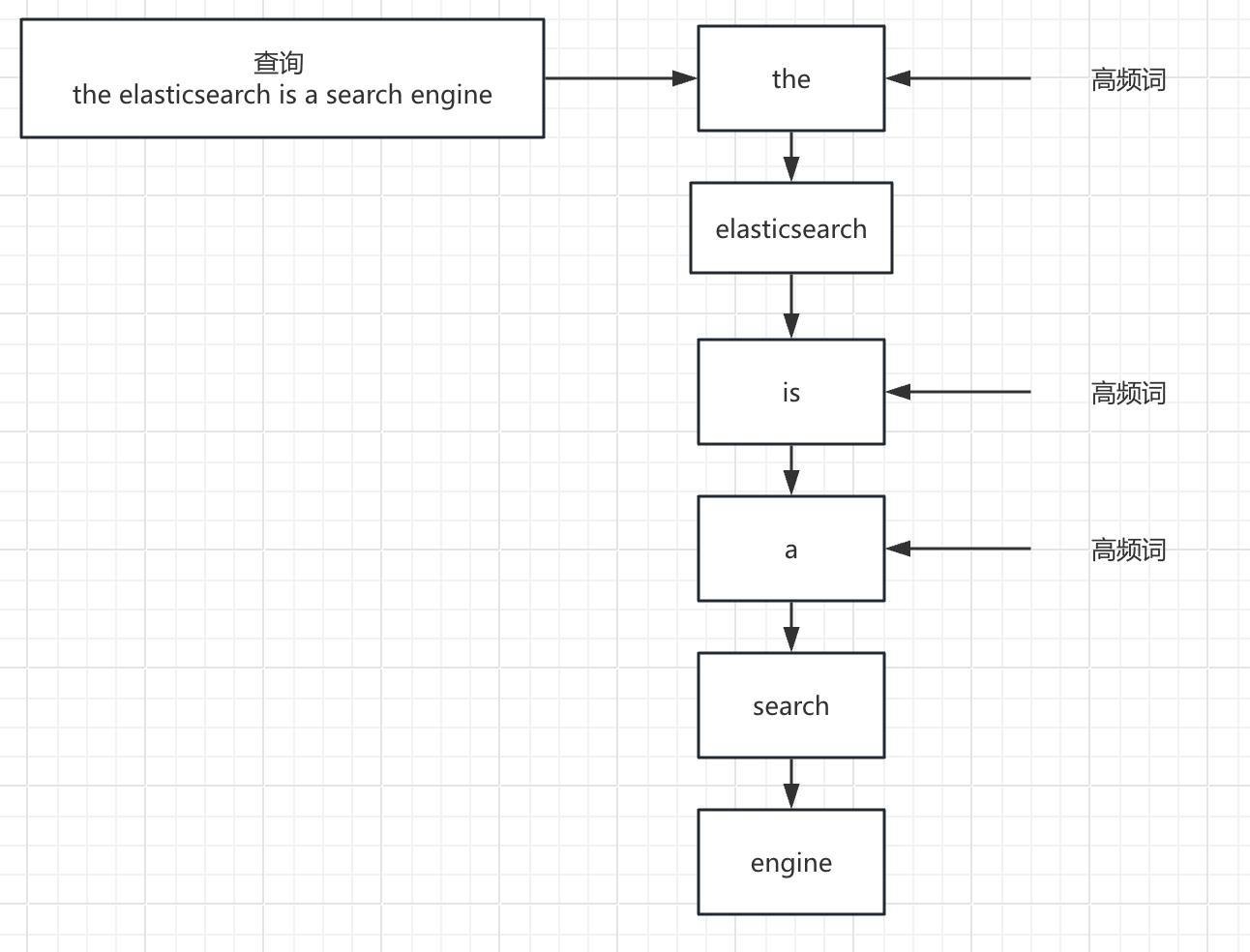
而现在,Elasticsearch 现在可以跳过那些在早期阶段就被判定为不会进入结果集顶部的低排名记录的评分计算,从而显著提升查询速度。这里主要涉及了 block-max WAND 算法的实现。这是一个复杂且漫长的优化过程,有兴趣的同学可以阅读一下这段Magic WAND: Faster Retrieval of Top Hits in Elasticsearch。
从 Elastic 的测试结果来看,新算法的优化让 term 查询加速了 3-7 倍。当然从场景背景可以看出,这个优化主要在大数据量下有明显效果(小数据量也不会有太多的日常高频词)。
默认开启 soft-delete 减少 translog
从 Elasticsearch 7.4 开始,副本的数据恢复,不再完全依赖 translog 了,而是通过索引的 soft-delete 特性(Elasticsearch 7.0 起所有新索引默认启用软删除 soft-deletes)。这样就可以缩小 translog 的使用场景,从而 translog 的保留大小也可以减少了。
那原来使用 translog 是什么样的呢?
translog 是 ES 用于保证数据安全性的重要工具。同时副分片进行恢复时,它也起着重要作用,只要副分片待获取的差异数据是在 translog 所保留的数据范围内,就可以只从 trasnlog 复制差异的部分数据,而不用拖取整个分片。在之前的版本中,Elasticsearch 默认会保留 512M 或 12 小时的 translog 用于副本恢复。
那现在使用的 soft-delete 是什么呢?
soft-deletes 是 Lucene 中实现的特性。这个软删除有时候会和 lucene 本身的标记删除概念发生混淆。为了方便理解,我们在这里归纳一下,lucene 实现删除的方式是一种标记删除的方式,而这种标记删除可以分为硬删除和软删除。软删除和硬删除有一个明显的区分点是:硬删除,被删除的文档对应的文档号用索引文件 .liv 来描述。软删除 soft-delete,被标记为删除的文档不使用索引文件.liv 来描述,而是通过索引文件 .dvd .dvm 来描述。
这里再扩展一下,.liv 文件主要实现 fixedbitset 数据结构。而 .dvd .dvm 则组合实现了 docvalue 这种正排数据结构。
正排索引的数据结构助力了 translog 的‘减负’,副本可以相对简便的通过软删除中的数据标记来实现数据恢复的处理。
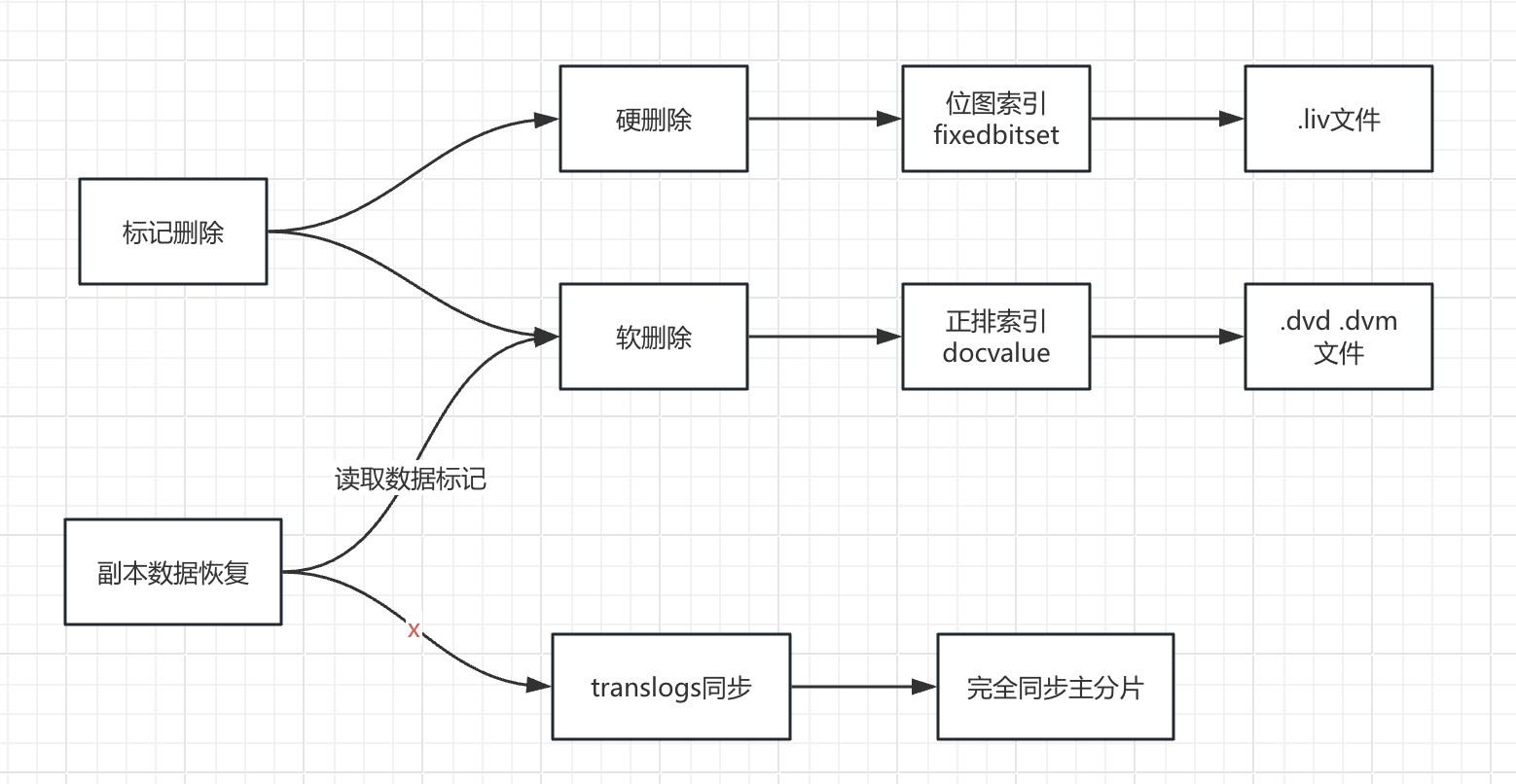
相比较简洁高效的位图索引,docvalue 虽然实现了更多的功能,满足更多的场景,也会带来更多的问题。最明显的就是对于 update 操作,会导致 refresh 变得慢,有些压力场景下 refresh 会达到 10s 以上。
数值/日期排序查询加速
Elasticsearch 7.6 版本提升了按日期或数值(即任何存储为有符号 64 位整数(long 类型)的字段)进行排序的查询性能。
这背后的优化原理和之前 top K 使用的 Block-Max WAND 算法有点相似,都是利用算法跳过非竞争性文档来实现加速。
实际效果可能因环境而异,受多种参数影响。在 Elastic 进行的测试场景下,可以达到 35 倍的速度优化。
FST 内存使用迁移到堆外
Elastic 7.3 版本实现了这个优化,是藏在 release note 里的彩蛋。
Also mmap terms index (.tip) files for hybridfs #43150 (issue: #42838)
看似不经意的一行,但是带来效果却不小。FST 从堆内转移到堆外后,JVM 的空间可以空余出很客观的一部分。

一直以来,ES 堆中常驻内存中占据比重最大是 FST,即 tip(terms index) 文件占据的空间,1TB 索引大约占用 2GB 或者更多的内存,因此为了节点稳定运行,业界通常认为一个节点 open 的索引不超过 5TB。现在,从 ES 7.3 版本开始,将 tip 文件修改为通过 mmap 的方式加载,这使 FST 占据的内存从堆内转移到了堆外由操作系统的 pagecache 管理。
存储字段压缩优化
Elasticsearch 7.10 基于 Apache Lucene 8.7 引入了对存储字段(stored fields)的更高压缩率优化。不管是对于基于 DEFLATE 的 index.codec: best_compression 还是基于 LZ4 的index.codec: default都有不错的表现,在 Elastic 的测试场景下,最大可达到 10%的存储空间减少。
对于数据压缩 lucene 这次主要做了两个优化。
-
Elastic 研究发现在存储数据的时候,底层的 block 越大,压缩效果越好,因为中间被压缩的重复数据可能越多。但是大块的 block 也可能因为解码重复数据降低查询速度。
-
block 间通过共享字典来维持检索效率和数据压缩之间的平衡。
2.1. 首先为压缩算法提供一个数据字典,它也可以用于字符串重复数据删除。如果在要压缩的数据流和字典之间有许多重复的字符串,那么最终可以得到更好的压缩比。在解压缩时也通过字典来快速补足。
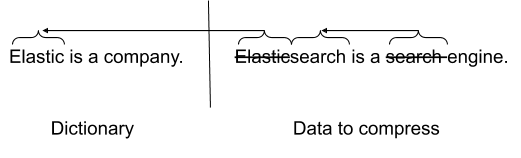
2.2. 同时,ES 使用更大的数据块,这些数据块本身被分成一个字典和 10 个子块,这些子块使用这个字典进行压缩。
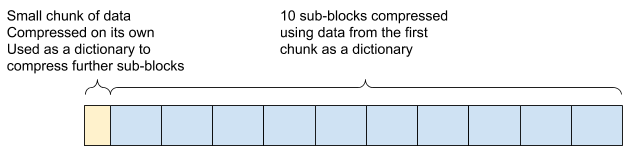
而对于实际业务场景中,日志和监控数据的重复率往往会很好,因此在这两个场景中的压缩效果也是最明显的。
小结
当然,除了这几项外,ES 在各个版本中也做了不少优化,比如:调整 search.max_buckets 增加到 65534;Date histogram 聚合性能优化等等。有兴趣的同学可以参照各个版本的 release highlight
参考资料:
- Save space and money with improved storage efficiency in Elasticsearch 7.10
- Elasticsearch 7.3 的 offheap 原理
- Elasticsearch 7.4 的 soft-deletes 是个什么鬼
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(2)- 字段类型篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/feature-evolution-from-elasticsearch-6.8-to-7.10-part-1/
前言
ES 7.10 可能是现在比较常见的 ES 版本。但是对于一些相迭代比较慢的早期业务系统来说,ES 6.8 是一个名副其实的“钉子户”。
借着工作内升级调研的任务东风,我整理从 ES 6.8 到 ES 7.10 ELastic 重点列出的新增功能和优化内容。将分为 6 个篇幅给大家详细阐述。
本系列文章主要针对 Elasticsearch 传统的使用功能和基础的模块,像是集群任务的管理、搜索、聚合还有字段类型这样的功能。对于付费功能或者全新的模块,比如:CCR、机器学习和数据流,这里不去深入探讨。
内容的主要来源于 Elastic 各个版本的发布信息,这里主要比对 ES 6.8 版本到 7.10 版本的差异,并不一一枚举各个新的功能点出现的时间版本。
下面是第一篇:关于 ES 性能的优化
ES 7.10 的性能优化
集群协调算法升级
基于 Elastic 博客提供的资料,Elasticsearch 7.0 的核心改进在于集群协调层的彻底重构,取代了旧版 Zen Discovery 的局限性,引入更健壮、自动化的分布式共识机制。从理论上来说这次优化有着不少的进步,可以显著提升了高可用性与运维效率
主要的优化点有下面三点:
-
消除分裂脑(Split Brain)风险:通过自动化计算,确保集群状态更新的安全性。旧版
minimum_master_nodes的手动配置被移除,避免人为误操作。 -
提升集群稳定性与恢复速度:节点故障时,集群更快达成一致,减少服务中断窗口。
- 简化运维复杂度:可以动态扩缩容无需手动调整配置,系统自动管理选举配置。同时提供更清晰的日志和错误提示,加速故障诊断。
| 旧版配置 | ES 7.0 配置 | 作用 |
|---|---|---|
discovery.zen.ping.unicast.hosts |
discovery.seed_hosts |
定义初始发现的种子节点列表(IP 或主机名) |
discovery.zen.minimum_master_nodes |
已移除 | 由系统自动管理法定人数 |
而在优化的原则里,Elastic 更强调安全第一。比如,在半数以上主节点永久丢失的风险场景下,ES 7.0 之前的集群会静默等待恢复,允许通过启动新空节点强制恢复,这样可能会导致数据不一致或丢失。在 Elasticsearch 7.0 以及更高版本中,这种不安全活动受到了更多限制。集群宁愿保持不可用状态,也不会冒这种风险(除非使用 elasticsearch-node 恢复工具)。
这次优化显著降低了人为错误的风险:移除脆弱的手动配置,减少运维使用的理解成本。同时提升关键业务连续性:快速故障恢复与明确的容错机制,能适合更多场景需求。
当然也并不是尽善尽美的,也会存在大集群下投票节点过多导致竞争激烈而无法选主的问题,这种情况下,建议部署独立的主节点,并且可以考虑适当增大 cluster.election.duration 的配置。
Top K 对检索的加速
这里的 Top K 主要是指在普通检索时展示前列的数据 Top K。也就是说 Elasticsearch 7.0 对检索数据的查询性能做了明显的改善。那是做了所有查询场景的提升么?
ELastic 做了这么一个场景假设:如果用户通常只关注搜索结果的第一页,且并不关心具体匹配的文档总数,对于超出一定数量的数据搜索引擎可以展示“超过 10,000 条结果”并提供分页浏览来优化搜索效率。但是在实际过程中用户常在查询中使用高频词(如“the”或“a”),这迫使 Elasticsearch 为大量文档计算评分,明显占用了查询资源的使用,即使这些常见词对相关性排序贡献甚微。
而现在,Elasticsearch 现在可以跳过那些在早期阶段就被判定为不会进入结果集顶部的低排名记录的评分计算,从而显著提升查询速度。这里主要涉及了 block-max WAND 算法的实现。这是一个复杂且漫长的优化过程,有兴趣的同学可以阅读一下这段Magic WAND: Faster Retrieval of Top Hits in Elasticsearch。
从 Elastic 的测试结果来看,新算法的优化让 term 查询加速了 3-7 倍。当然从场景背景可以看出,这个优化主要在大数据量下有明显效果(小数据量也不会有太多的日常高频词)。
默认开启 soft-delete 减少 translog
从 Elasticsearch 7.4 开始,副本的数据恢复,不再完全依赖 translog 了,而是通过索引的 soft-delete 特性(Elasticsearch 7.0 起所有新索引默认启用软删除 soft-deletes)。这样就可以缩小 translog 的使用场景,从而 translog 的保留大小也可以减少了。
那原来使用 translog 是什么样的呢?
translog 是 ES 用于保证数据安全性的重要工具。同时副分片进行恢复时,它也起着重要作用,只要副分片待获取的差异数据是在 translog 所保留的数据范围内,就可以只从 trasnlog 复制差异的部分数据,而不用拖取整个分片。在之前的版本中,Elasticsearch 默认会保留 512M 或 12 小时的 translog 用于副本恢复。
那现在使用的 soft-delete 是什么呢?
soft-deletes 是 Lucene 中实现的特性。这个软删除有时候会和 lucene 本身的标记删除概念发生混淆。为了方便理解,我们在这里归纳一下,lucene 实现删除的方式是一种标记删除的方式,而这种标记删除可以分为硬删除和软删除。软删除和硬删除有一个明显的区分点是:硬删除,被删除的文档对应的文档号用索引文件 .liv 来描述。软删除 soft-delete,被标记为删除的文档不使用索引文件.liv 来描述,而是通过索引文件 .dvd .dvm 来描述。
这里再扩展一下,.liv 文件主要实现 fixedbitset 数据结构。而 .dvd .dvm 则组合实现了 docvalue 这种正排数据结构。
正排索引的数据结构助力了 translog 的‘减负’,副本可以相对简便的通过软删除中的数据标记来实现数据恢复的处理。
相比较简洁高效的位图索引,docvalue 虽然实现了更多的功能,满足更多的场景,也会带来更多的问题。最明显的就是对于 update 操作,会导致 refresh 变得慢,有些压力场景下 refresh 会达到 10s 以上。
数值/日期排序查询加速
Elasticsearch 7.6 版本提升了按日期或数值(即任何存储为有符号 64 位整数(long 类型)的字段)进行排序的查询性能。
这背后的优化原理和之前 top K 使用的 Block-Max WAND 算法有点相似,都是利用算法跳过非竞争性文档来实现加速。
实际效果可能因环境而异,受多种参数影响。在 Elastic 进行的测试场景下,可以达到 35 倍的速度优化。
FST 内存使用迁移到堆外
Elastic 7.3 版本实现了这个优化,是藏在 release note 里的彩蛋。
Also mmap terms index (.tip) files for hybridfs #43150 (issue: #42838)
看似不经意的一行,但是带来效果却不小。FST 从堆内转移到堆外后,JVM 的空间可以空余出很客观的一部分。
一直以来,ES 堆中常驻内存中占据比重最大是 FST,即 tip(terms index) 文件占据的空间,1TB 索引大约占用 2GB 或者更多的内存,因此为了节点稳定运行,业界通常认为一个节点 open 的索引不超过 5TB。现在,从 ES 7.3 版本开始,将 tip 文件修改为通过 mmap 的方式加载,这使 FST 占据的内存从堆内转移到了堆外由操作系统的 pagecache 管理。
存储字段压缩优化
Elasticsearch 7.10 基于 Apache Lucene 8.7 引入了对存储字段(stored fields)的更高压缩率优化。不管是对于基于 DEFLATE 的 index.codec: best_compression 还是基于 LZ4 的index.codec: default都有不错的表现,在 Elastic 的测试场景下,最大可达到 10%的存储空间减少。
对于数据压缩 lucene 这次主要做了两个优化。
-
Elastic 研究发现在存储数据的时候,底层的 block 越大,压缩效果越好,因为中间被压缩的重复数据可能越多。但是大块的 block 也可能因为解码重复数据降低查询速度。
-
block 间通过共享字典来维持检索效率和数据压缩之间的平衡。
2.1. 首先为压缩算法提供一个数据字典,它也可以用于字符串重复数据删除。如果在要压缩的数据流和字典之间有许多重复的字符串,那么最终可以得到更好的压缩比。在解压缩时也通过字典来快速补足。
2.2. 同时,ES 使用更大的数据块,这些数据块本身被分成一个字典和 10 个子块,这些子块使用这个字典进行压缩。
而对于实际业务场景中,日志和监控数据的重复率往往会很好,因此在这两个场景中的压缩效果也是最明显的。
小结
当然,除了这几项外,ES 在各个版本中也做了不少优化,比如:调整 search.max_buckets 增加到 65534;Date histogram 聚合性能优化等等。有兴趣的同学可以参照各个版本的 release highlight
参考资料:
- Save space and money with improved storage efficiency in Elasticsearch 7.10
- Elasticsearch 7.3 的 offheap 原理
- Elasticsearch 7.4 的 soft-deletes 是个什么鬼
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(2)- 字段类型篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/feature-evolution-from-elasticsearch-6.8-to-7.10-part-1/
【搜索客社区日报】第2021期 (2025-04-14)
https://mp.weixin.qq.com/s/QyyWFim2y6mqhvzmb4FBZw
2、费曼讲解大模型参数微调——小白也能看懂
https://mp.weixin.qq.com/s/39vzs9RTB824oZvF01Kdmw
3、想得久≠答得对!LLM应该自主决定Reasoning长度!
https://mp.weixin.qq.com/s/XTiJrWkuRmyzW5KO3lwrow
4、如何合理规划Elasticsearch的索引|得物技术
https://mp.weixin.qq.com/s/eKuD4eSF4FS9Fw5xdj6Sow
5、我们为何必须坚持国产替代?
https://mp.weixin.qq.com/s/yliQf4cf1kBfwIG-w_hjTQ
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/QyyWFim2y6mqhvzmb4FBZw
2、费曼讲解大模型参数微调——小白也能看懂
https://mp.weixin.qq.com/s/39vzs9RTB824oZvF01Kdmw
3、想得久≠答得对!LLM应该自主决定Reasoning长度!
https://mp.weixin.qq.com/s/XTiJrWkuRmyzW5KO3lwrow
4、如何合理规划Elasticsearch的索引|得物技术
https://mp.weixin.qq.com/s/eKuD4eSF4FS9Fw5xdj6Sow
5、我们为何必须坚持国产替代?
https://mp.weixin.qq.com/s/yliQf4cf1kBfwIG-w_hjTQ
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
代理 Elasticsearch 服务:INFINI Gateway VS Nginx

INFINI Gateway 简介
INFINI Gateway 是一款面向 Elasticsearch 的高性能应用网关,专为提升 Elasticsearch 集群的性能、安全性和可管理性而设计。它作为 Elasticsearch 的前置网关,能够处理所有客户端请求,并将其转发到后端的 Elasticsearch 集群,同时提供丰富的功能来优化请求处理和管理。此外还支持代理 Opensearch、Easysearch 服务。
Nginx 简介
Nginx 是一个高性能的 HTTP 和反向代理服务器,以其高并发处理能力、低内存消耗和稳定性著称,广泛应用于 Web 服务器、负载均衡和反向代理等场景。在 Elasticsearch 的使用场景里,也有小伙伴使用 Nginx 来代理 Elasticsearch 的服务,利用 Nginx 的负载均衡能力,将请求转发到多个 Elasticsearch 节点。
这两个软件都能代理 Elasticsearch 服务,但是他们有什么区别?我们来一起分析分析。
负载均衡
Elasticsearch 是分布式系统,提倡使用 round-robin 方式将请求发送到多个节点。不管是 Nginx 还是 INFINI Gateway 都默认使用 round-boin 方式转发请求,也都支持 weighted round-robin(加权轮询)方式进行请求转发,这点两者相当。
节点自动更新
Elasticsearch 集群可能会遇到添加、删除节点的情况,代理程序能否感知 Elasticsearch 节点的变化将变得非常关键。
在 Nginx 中,所有转发节点的 IP 地址都必须写入到配置文件中。如果 Elasticsearch 集群加入了新的节点进行请求处理,则需要 Nginx 编辑配置文件把新节点的 IP 地址加入其中,然后重启或重载 Nginx 服务,才能将请求分发到新的节点。反之如果有节点下线,也要编辑 Nginx 配置文件并重载服务。
INFINI Gateway 是面向 Elasticsearch 设计的应用网关,具有后端节点发现和更新的功能,能够感知 Elasticsearch 集群节点加入、离开的情况。开启节点发现和更新功能后,Gateway 会定期自动更新节点列表,将请求均匀转发到列表中的节点。可参考之前的博客开启节点自动更新。
⚠️ 注意:INFINI Gateway 默认后端节点发现和更新的功能为关闭状态。
定向转发请求
使用 Elasticsearch 集群的场景多种多样,如果想对转发的节点做进一步控制,可能需要根据不同条件进行节点筛选:
- IP 地址
- 节点角色
- 节点标签
Nginx
Nginx 支持根据 IP 地址进行转发的,将需要转发的节点 IP 地址写入配置文件即可。
upstream es-cluster {
server 192.168.56.102:9200;
server 192.168.56.102:9201;
server 192.168.56.102:9202;
}但不支持按节点角色、节点标签进行筛选,因为 Nginx 中并没有这种概念。
INFINI Gateway
INFINI Gateway 支持按 IP 地址进行筛选:
- 不开节点发现:只转发到配置文件指定的节点(IP 地址)
- 开启节点发现:转发到所有发现的节点
flow:
- name: cache_first
filter:
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
filter:
hosts:
exclude:
- 192.168.3.201:9200
include:
- 192.168.3.202:9200
- 192.168.3.203:9200此外 Gateway 还支持通过节点角色、节点标签筛选转发节点。
flow:
- name: cache_first
filter:
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
filter:
tags:
exclude:
- temp: cold
include:
- disk: ssd
roles:
exclude:
- master
include:
- data
- ingest多种筛选条件可以同时使用,详细信息请查看官方文档。
作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
原文:https://infinilabs.cn/blog/2025/proxy-elasticsearch-infini-gateway-vs-nginx/
INFINI Gateway 简介
INFINI Gateway 是一款面向 Elasticsearch 的高性能应用网关,专为提升 Elasticsearch 集群的性能、安全性和可管理性而设计。它作为 Elasticsearch 的前置网关,能够处理所有客户端请求,并将其转发到后端的 Elasticsearch 集群,同时提供丰富的功能来优化请求处理和管理。此外还支持代理 Opensearch、Easysearch 服务。
Nginx 简介
Nginx 是一个高性能的 HTTP 和反向代理服务器,以其高并发处理能力、低内存消耗和稳定性著称,广泛应用于 Web 服务器、负载均衡和反向代理等场景。在 Elasticsearch 的使用场景里,也有小伙伴使用 Nginx 来代理 Elasticsearch 的服务,利用 Nginx 的负载均衡能力,将请求转发到多个 Elasticsearch 节点。
这两个软件都能代理 Elasticsearch 服务,但是他们有什么区别?我们来一起分析分析。
负载均衡
Elasticsearch 是分布式系统,提倡使用 round-robin 方式将请求发送到多个节点。不管是 Nginx 还是 INFINI Gateway 都默认使用 round-boin 方式转发请求,也都支持 weighted round-robin(加权轮询)方式进行请求转发,这点两者相当。
节点自动更新
Elasticsearch 集群可能会遇到添加、删除节点的情况,代理程序能否感知 Elasticsearch 节点的变化将变得非常关键。
在 Nginx 中,所有转发节点的 IP 地址都必须写入到配置文件中。如果 Elasticsearch 集群加入了新的节点进行请求处理,则需要 Nginx 编辑配置文件把新节点的 IP 地址加入其中,然后重启或重载 Nginx 服务,才能将请求分发到新的节点。反之如果有节点下线,也要编辑 Nginx 配置文件并重载服务。
INFINI Gateway 是面向 Elasticsearch 设计的应用网关,具有后端节点发现和更新的功能,能够感知 Elasticsearch 集群节点加入、离开的情况。开启节点发现和更新功能后,Gateway 会定期自动更新节点列表,将请求均匀转发到列表中的节点。可参考之前的博客开启节点自动更新。
⚠️ 注意:INFINI Gateway 默认后端节点发现和更新的功能为关闭状态。
定向转发请求
使用 Elasticsearch 集群的场景多种多样,如果想对转发的节点做进一步控制,可能需要根据不同条件进行节点筛选:
- IP 地址
- 节点角色
- 节点标签
Nginx
Nginx 支持根据 IP 地址进行转发的,将需要转发的节点 IP 地址写入配置文件即可。
upstream es-cluster {
server 192.168.56.102:9200;
server 192.168.56.102:9201;
server 192.168.56.102:9202;
}但不支持按节点角色、节点标签进行筛选,因为 Nginx 中并没有这种概念。
INFINI Gateway
INFINI Gateway 支持按 IP 地址进行筛选:
- 不开节点发现:只转发到配置文件指定的节点(IP 地址)
- 开启节点发现:转发到所有发现的节点
flow:
- name: cache_first
filter:
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
filter:
hosts:
exclude:
- 192.168.3.201:9200
include:
- 192.168.3.202:9200
- 192.168.3.203:9200此外 Gateway 还支持通过节点角色、节点标签筛选转发节点。
flow:
- name: cache_first
filter:
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
filter:
tags:
exclude:
- temp: cold
include:
- disk: ssd
roles:
exclude:
- master
include:
- data
- ingest多种筛选条件可以同时使用,详细信息请查看官方文档。
收起阅读 »作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
原文:https://infinilabs.cn/blog/2025/proxy-elasticsearch-infini-gateway-vs-nginx/
【搜索客社区日报】第2020期 (2025-04-11)
https://www.infoq.cn/article/y9gcWYGXUhRYqvXqsy1f
2、Easysearch 索引备份之 Clone API
https://blog.csdn.net/yangmf20 ... 88006
3、Elasticsearch 8.X 如何利用嵌入向量提升搜索能力?
https://mp.weixin.qq.com/s/Vv2i3FOSUTAhnTiKJM2h3A
4、ES 集群日增数据统计难?手把手教你精准计算文档数&存储量!
https://cloud.tencent.com/deve ... 09449
5、INFINI Console:助力 Elasticsearch 集群平滑升级,保障业务零中断
https://infinilabs.cn/case/ind ... nsole
编辑:Fred
更多资讯:http://news.searchkit.cn
https://www.infoq.cn/article/y9gcWYGXUhRYqvXqsy1f
2、Easysearch 索引备份之 Clone API
https://blog.csdn.net/yangmf20 ... 88006
3、Elasticsearch 8.X 如何利用嵌入向量提升搜索能力?
https://mp.weixin.qq.com/s/Vv2i3FOSUTAhnTiKJM2h3A
4、ES 集群日增数据统计难?手把手教你精准计算文档数&存储量!
https://cloud.tencent.com/deve ... 09449
5、INFINI Console:助力 Elasticsearch 集群平滑升级,保障业务零中断
https://infinilabs.cn/case/ind ... nsole
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2019期 (2025-04-10)
https://mp.weixin.qq.com/s/R_X0qxSiA3X4FqhWzyQM1g
2. MCP,竟然是两位年轻工程师的杰作
https://mp.weixin.qq.com/s/4F9PokMiKTaobeKQaw7Wcg
3.为 Kubernetes 提供智能的 LLM 推理路由:Gateway API Inference Extension 深度解析
https://mp.weixin.qq.com/s/jRxY4GJgnvzk-o3nBmjP4g
4.基于 MCP 实现 AI 应用架构新范式的一线实践(含78页架构图下载)
https://mp.weixin.qq.com/s/r1wKHJDzUgWncZvNko2O2Q
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/R_X0qxSiA3X4FqhWzyQM1g
2. MCP,竟然是两位年轻工程师的杰作
https://mp.weixin.qq.com/s/4F9PokMiKTaobeKQaw7Wcg
3.为 Kubernetes 提供智能的 LLM 推理路由:Gateway API Inference Extension 深度解析
https://mp.weixin.qq.com/s/jRxY4GJgnvzk-o3nBmjP4g
4.基于 MCP 实现 AI 应用架构新范式的一线实践(含78页架构图下载)
https://mp.weixin.qq.com/s/r1wKHJDzUgWncZvNko2O2Q
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
Operator 开发入门系列(一):Hello World!
背景
我们公司最近计划将产品迁移到 Kubernetes 环境。 为了更好地管理和自动化我们的应用程序,我们决定使用 Kubernetes Operator。 本系列博客将记录我们学习和开发 Operator 的过程,希望能帮助更多的人入门 Operator 开发。
目标读者
- 对 Kubernetes 有一定了解的开发人员和运维人员
- 希望使用 Operator 自动化管理应用程序的人员
- 对 Go 语言有基本了解的人员
准备工作
在开始之前,你需要准备以下环境:
-
Go 语言环境 (>= 1.23): Operator 通常使用 Go 语言开发,你需要安装 Go 语言环境。 建议使用 Go 1.21 或更高版本。 可以从 https://go.dev/dl/ 下载安装包。 安装完成后,请配置好
GOPATH和PATH环境变量。 -
Kubernetes 集群: 你需要一个可用的 Kubernetes 集群来部署和测试 Operator。 可以使用 Minikube、Kind 或其他的 Kubernetes 发行版。
-
kubectl 命令行工具:
kubectl是 Kubernetes 的命令行工具,用于与 Kubernetes 集群交互。 请确保你已经安装并配置了kubectl, 并且能够连接到你的 Kubernetes 集群。 - Kubebuilder (>= 3.0): Kubebuilder 是一个用于快速构建 Kubernetes Operator 的框架。 使用 Kubebuilder 可以简化 Operator 的开发流程,并生成一些必要的代码框架。 可以使用以下命令安装 Kubebuilder:
cd $HOME/go/bin
curl -L -o kubebuilder "https://go.kubebuilder.io/dl/latest/$(go env GOOS)/$(go env GOARCH)"
chmod +x kubebuilder请确保
$HOME/go/bin目录在你的PATH环境变量中。 可以运行kubebuilder version命令来验证 Kubebuilder 是否安装成功。
- Docker (可选): 如果你需要构建 Operator 的 Docker 镜像,你需要安装 Docker。
我的环境是 MacOS(arm64) + Orbstack
什么是 Operator?
简单来说,Operator 是 Kubernetes 的扩展,它利用自定义资源(Custom Resources, CRs)来自动化管理应用程序。Operator 允许我们像管理 Kubernetes 内置资源一样管理复杂的应用程序,例如数据库、消息队列等。
为什么选择 Operator?
Operator 提供了一种声明式的方式来管理应用程序的生命周期,包括部署、升级、备份、恢复等。它可以简化运维流程,提高自动化程度,并确保应用程序的状态符合预期。
我们的第一个 Operator:Hello World
这个 Operator 将监听一个名为 HelloWorld 的自定义资源,并在 Kubernetes 中创建一个 Pod,该 Pod 运行一个简单的 "Hello World" 应用程序。
1. 初始化 Kubebuilder 项目
首先,我们需要使用 Kubebuilder 创建一个新的项目。 在你的 GOPATH 目录下创建一个新的目录,例如 hello-world-operator,然后进入该目录,运行以下命令
kubebuilder init --domain infini.cloud --repo github.com/infinilabs/hello-world-operator这个命令会创建一个新的 Kubebuilder 项目,并生成一些必要的文件和目录。
2. 创建自定义资源(Custom Resource Definition, CRD)
接下来,我们需要定义 HelloWorld 资源的结构。 运行以下命令
kubebuilder create api --group example --version v1alpha1 --kind HelloWorld这个命令会创建一个新的 API 定义,包括 api/v1alpha1/helloworld_types.go 和 controllers/helloworld_controller.go 两个文件。
编辑 api/v1alpha1/helloworld_types.go 文件,修改 HelloWorldSpec 的定义,添加 name 和 message 字段:
// HelloWorldSpec defines the desired state of HelloWorld
type HelloWorldSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Name is the name of the HelloWorld resource
Name string `json:"name,omitempty"`
// Message is the message to be printed by the pod
Message string `json:"message,omitempty"`
}3. 实现 Reconcile 逻辑
编辑 controllers/helloworld_controller.go 文件,实现 Reconcile 函数, 创建一个 Pod,该 Pod 运行一个 busybox 镜像,并输出 HelloWorld 资源中定义的 message。
package controllers
import (
"context"
"fmt"
corev1 "k8s.io/api/core/v1"
apierrors "k8s.io/apimachinery/pkg/api/errors"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
examplev1alpha1 "github.com/infinilabs/hello-world-operator/api/v1alpha1"
)
// HelloWorldReconciler reconciles a HelloWorld object
type HelloWorldReconciler struct {
client.Client
Scheme *runtime.Scheme
}
//+kubebuilder:rbac:groups=example.com,resources=helloworlds,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=example.com,resources=helloworlds/status,verbs=get;update;patch
//+kubebuilder:rbac:groups=example.com,resources=helloworlds/finalizers,verbs=update
//+kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;watch;create;update;patch;delete
// Reconcile is part of the main kubernetes reconciliation loop which aims to
// move the current state of the cluster closer to the desired state.
// For more details, check Reconcile and its Result here:
// - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.13.0/pkg/reconcile
func (r *HelloWorldReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := log.FromContext(ctx)
// 1. Fetch the HelloWorld instance
helloWorld := &examplev1alpha1.HelloWorld{}
err := r.Get(ctx, req.NamespacedName, helloWorld)
if err != nil {
if apierrors.IsNotFound(err) {
// Object not found, return. Created objects are automatically garbage collected.
// For additional cleanup logic use finalizers.
log.Info("HelloWorld resource not found. Ignoring since object must be deleted")
return ctrl.Result{}, nil
}
// Error reading the object - requeue the request.
log.Error(err, "Failed to get HelloWorld")
return ctrl.Result{}, err
}
// 2. Define the desired Pod
pod := &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: helloWorld.Name + "-pod",
Namespace: helloWorld.Namespace,
Labels: map[string]string{
"app": helloWorld.Name,
},
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: "hello-world",
Image: "busybox",
Command: []string{"sh", "-c", fmt.Sprintf("echo '%s' && sleep 3600", helloWorld.Spec.Message)},
},
},
},
}
// 3. Set HelloWorld instance as the owner and controller
if err := ctrl.SetControllerReference(helloWorld, pod, r.Scheme); err != nil {
log.Error(err, "Failed to set controller reference")
return ctrl.Result{}, err
}
// 4. Check if the Pod already exists
found := &corev1.Pod{}
err = r.Get(ctx, client.ObjectKey{Name: pod.Name, Namespace: pod.Namespace}, found)
if err != nil && apierrors.IsNotFound(err) {
log.Info("Creating a new Pod", "Pod.Namespace", pod.Namespace, "Pod.Name", pod.Name)
err = r.Create(ctx, pod)
if err != nil {
log.Error(err, "Failed to create new Pod", "Pod.Namespace", pod.Namespace, "Pod.Name", pod.Name)
return ctrl.Result{}, err
}
// Pod created successfully - return and requeue
return ctrl.Result{Requeue: true}, nil
} else if err != nil {
log.Error(err, "Failed to get Pod")
return ctrl.Result{}, err
}
// 5. Pod already exists - don't requeue
log.Info("Skip reconcile: Pod already exists", "Pod.Namespace", found.Namespace, "Pod.Name", found.Name)
return ctrl.Result{}, nil
}
// SetupWithManager sets up the controller with the Manager.
func (r *HelloWorldReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&examplev1alpha1.HelloWorld{}).
Owns(&corev1.Pod{}).
Complete(r)
}4. 安装 CRD 到 Kubernetes 集群
运行以下命令安装 CRD 到 Kubernetes 集群:
make install5. 运行 Operator
运行以下命令在本地运行 Operator:
make run6. 创建 HelloWorld 资源
创建一个名为 my-hello-world.yaml 的文件,内容如下:
apiVersion: example.com/v1alpha1
kind: HelloWorld
metadata:
name: my-hello-world
spec:
name: my-hello-world
message: "Hello World from Operator!"使用 kubectl apply -f my-hello-world.yaml 创建资源。
7. 验证
使用 kubectl get pods 命令查看是否创建了名为 my-hello-world-pod 的 Pod。 使用 kubectl logs my-hello-world-pod 查看 Pod 的日志,确认是否输出了 "Hello World from Operator!"。
总结
恭喜你完成了第一个 Operator! 虽然这个 Operator 非常简单,但它展示了 Operator 的基本原理:监听自定义资源,并根据资源的状态来管理 Kubernetes 资源。 在接下来的系列中,我们将深入探讨 Operator 的更多高级特性。
敬请期待下一篇博客!
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/kubernetes-operator-develop-part-1/
背景
我们公司最近计划将产品迁移到 Kubernetes 环境。 为了更好地管理和自动化我们的应用程序,我们决定使用 Kubernetes Operator。 本系列博客将记录我们学习和开发 Operator 的过程,希望能帮助更多的人入门 Operator 开发。
目标读者
- 对 Kubernetes 有一定了解的开发人员和运维人员
- 希望使用 Operator 自动化管理应用程序的人员
- 对 Go 语言有基本了解的人员
准备工作
在开始之前,你需要准备以下环境:
-
Go 语言环境 (>= 1.23): Operator 通常使用 Go 语言开发,你需要安装 Go 语言环境。 建议使用 Go 1.21 或更高版本。 可以从 https://go.dev/dl/ 下载安装包。 安装完成后,请配置好
GOPATH和PATH环境变量。 -
Kubernetes 集群: 你需要一个可用的 Kubernetes 集群来部署和测试 Operator。 可以使用 Minikube、Kind 或其他的 Kubernetes 发行版。
-
kubectl 命令行工具:
kubectl是 Kubernetes 的命令行工具,用于与 Kubernetes 集群交互。 请确保你已经安装并配置了kubectl, 并且能够连接到你的 Kubernetes 集群。 - Kubebuilder (>= 3.0): Kubebuilder 是一个用于快速构建 Kubernetes Operator 的框架。 使用 Kubebuilder 可以简化 Operator 的开发流程,并生成一些必要的代码框架。 可以使用以下命令安装 Kubebuilder:
cd $HOME/go/bin
curl -L -o kubebuilder "https://go.kubebuilder.io/dl/latest/$(go env GOOS)/$(go env GOARCH)"
chmod +x kubebuilder请确保
$HOME/go/bin目录在你的PATH环境变量中。 可以运行kubebuilder version命令来验证 Kubebuilder 是否安装成功。
- Docker (可选): 如果你需要构建 Operator 的 Docker 镜像,你需要安装 Docker。
我的环境是 MacOS(arm64) + Orbstack
什么是 Operator?
简单来说,Operator 是 Kubernetes 的扩展,它利用自定义资源(Custom Resources, CRs)来自动化管理应用程序。Operator 允许我们像管理 Kubernetes 内置资源一样管理复杂的应用程序,例如数据库、消息队列等。
为什么选择 Operator?
Operator 提供了一种声明式的方式来管理应用程序的生命周期,包括部署、升级、备份、恢复等。它可以简化运维流程,提高自动化程度,并确保应用程序的状态符合预期。
我们的第一个 Operator:Hello World
这个 Operator 将监听一个名为 HelloWorld 的自定义资源,并在 Kubernetes 中创建一个 Pod,该 Pod 运行一个简单的 "Hello World" 应用程序。
1. 初始化 Kubebuilder 项目
首先,我们需要使用 Kubebuilder 创建一个新的项目。 在你的 GOPATH 目录下创建一个新的目录,例如 hello-world-operator,然后进入该目录,运行以下命令
kubebuilder init --domain infini.cloud --repo github.com/infinilabs/hello-world-operator这个命令会创建一个新的 Kubebuilder 项目,并生成一些必要的文件和目录。
2. 创建自定义资源(Custom Resource Definition, CRD)
接下来,我们需要定义 HelloWorld 资源的结构。 运行以下命令
kubebuilder create api --group example --version v1alpha1 --kind HelloWorld这个命令会创建一个新的 API 定义,包括 api/v1alpha1/helloworld_types.go 和 controllers/helloworld_controller.go 两个文件。
编辑 api/v1alpha1/helloworld_types.go 文件,修改 HelloWorldSpec 的定义,添加 name 和 message 字段:
// HelloWorldSpec defines the desired state of HelloWorld
type HelloWorldSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Name is the name of the HelloWorld resource
Name string `json:"name,omitempty"`
// Message is the message to be printed by the pod
Message string `json:"message,omitempty"`
}3. 实现 Reconcile 逻辑
编辑 controllers/helloworld_controller.go 文件,实现 Reconcile 函数, 创建一个 Pod,该 Pod 运行一个 busybox 镜像,并输出 HelloWorld 资源中定义的 message。
package controllers
import (
"context"
"fmt"
corev1 "k8s.io/api/core/v1"
apierrors "k8s.io/apimachinery/pkg/api/errors"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
examplev1alpha1 "github.com/infinilabs/hello-world-operator/api/v1alpha1"
)
// HelloWorldReconciler reconciles a HelloWorld object
type HelloWorldReconciler struct {
client.Client
Scheme *runtime.Scheme
}
//+kubebuilder:rbac:groups=example.com,resources=helloworlds,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=example.com,resources=helloworlds/status,verbs=get;update;patch
//+kubebuilder:rbac:groups=example.com,resources=helloworlds/finalizers,verbs=update
//+kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;watch;create;update;patch;delete
// Reconcile is part of the main kubernetes reconciliation loop which aims to
// move the current state of the cluster closer to the desired state.
// For more details, check Reconcile and its Result here:
// - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.13.0/pkg/reconcile
func (r *HelloWorldReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := log.FromContext(ctx)
// 1. Fetch the HelloWorld instance
helloWorld := &examplev1alpha1.HelloWorld{}
err := r.Get(ctx, req.NamespacedName, helloWorld)
if err != nil {
if apierrors.IsNotFound(err) {
// Object not found, return. Created objects are automatically garbage collected.
// For additional cleanup logic use finalizers.
log.Info("HelloWorld resource not found. Ignoring since object must be deleted")
return ctrl.Result{}, nil
}
// Error reading the object - requeue the request.
log.Error(err, "Failed to get HelloWorld")
return ctrl.Result{}, err
}
// 2. Define the desired Pod
pod := &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: helloWorld.Name + "-pod",
Namespace: helloWorld.Namespace,
Labels: map[string]string{
"app": helloWorld.Name,
},
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: "hello-world",
Image: "busybox",
Command: []string{"sh", "-c", fmt.Sprintf("echo '%s' && sleep 3600", helloWorld.Spec.Message)},
},
},
},
}
// 3. Set HelloWorld instance as the owner and controller
if err := ctrl.SetControllerReference(helloWorld, pod, r.Scheme); err != nil {
log.Error(err, "Failed to set controller reference")
return ctrl.Result{}, err
}
// 4. Check if the Pod already exists
found := &corev1.Pod{}
err = r.Get(ctx, client.ObjectKey{Name: pod.Name, Namespace: pod.Namespace}, found)
if err != nil && apierrors.IsNotFound(err) {
log.Info("Creating a new Pod", "Pod.Namespace", pod.Namespace, "Pod.Name", pod.Name)
err = r.Create(ctx, pod)
if err != nil {
log.Error(err, "Failed to create new Pod", "Pod.Namespace", pod.Namespace, "Pod.Name", pod.Name)
return ctrl.Result{}, err
}
// Pod created successfully - return and requeue
return ctrl.Result{Requeue: true}, nil
} else if err != nil {
log.Error(err, "Failed to get Pod")
return ctrl.Result{}, err
}
// 5. Pod already exists - don't requeue
log.Info("Skip reconcile: Pod already exists", "Pod.Namespace", found.Namespace, "Pod.Name", found.Name)
return ctrl.Result{}, nil
}
// SetupWithManager sets up the controller with the Manager.
func (r *HelloWorldReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&examplev1alpha1.HelloWorld{}).
Owns(&corev1.Pod{}).
Complete(r)
}4. 安装 CRD 到 Kubernetes 集群
运行以下命令安装 CRD 到 Kubernetes 集群:
make install5. 运行 Operator
运行以下命令在本地运行 Operator:
make run6. 创建 HelloWorld 资源
创建一个名为 my-hello-world.yaml 的文件,内容如下:
apiVersion: example.com/v1alpha1
kind: HelloWorld
metadata:
name: my-hello-world
spec:
name: my-hello-world
message: "Hello World from Operator!"使用 kubectl apply -f my-hello-world.yaml 创建资源。
7. 验证
使用 kubectl get pods 命令查看是否创建了名为 my-hello-world-pod 的 Pod。 使用 kubectl logs my-hello-world-pod 查看 Pod 的日志,确认是否输出了 "Hello World from Operator!"。
总结
恭喜你完成了第一个 Operator! 虽然这个 Operator 非常简单,但它展示了 Operator 的基本原理:监听自定义资源,并根据资源的状态来管理 Kubernetes 资源。 在接下来的系列中,我们将深入探讨 Operator 的更多高级特性。
敬请期待下一篇博客!
收起阅读 »作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/kubernetes-operator-develop-part-1/
Easysearch 自动备份:快照生命周期管理
之前介绍了 Easysearch 如何使用 S3 进行快照备份,毕竟那是手工操作。Easysearch 还提供了快照生命周期管理,能够按照策略自动创建、删除快照,极大地方便了用户的日常管理。
快照生命周期管理计划由创建计划、删除计划以及快照配置组成。
- 创建计划和删除计划包含一个 cron 表达式,指定任务的频率和时间。
- 删除计划可以指定快照保留策略,以保留过去 30 天的快照或仅保留最近的 10 个快照。
- 快照配置包括快照的索引和存储库,并支持所有通过 API 创建快照时的参数。此外,还可以指定快照名称中使用的日期的格式和时区。
快照生命周期创建的快照名称格式为 <policy _ name>-<date>-<Random number> 。
比如, 计划每 2 分钟对索引 .infini_metrics-00001 创建一个快照,并且只保留最近的 2 个快照。
curl -XPOST -uadmin:admin -H 'Content-Type: application/json' 'https://localhost:9200/_slm/policies/daily-policy' -d '
{
"description": "测试快照策略",
"creation": {
"schedule": {
"cron": {
"expression": "*/2 * * * *",
"timezone": "Asia/Shanghai"
}
},
"time_limit": "1h"
},
"deletion": {
"schedule": {
"cron": {
"expression": "*/1 * * * *",
"timezone": "Asia/Shanghai"
}
},
"condition": {
"max_count": 2
},
"time_limit": "1h"
},
"snapshot_config": {
"date_format": "yyyy-MM-dd-HH:mm",
"date_format_timezone": "Asia/Shanghai",
"indices": ".infini_metrics-00001",
"repository": "easysearch_s3_repo",
"ignore_unavailable": "true",
"include_global_state": "false"
}
}'自动创建的快照如下图,一个 16 点 34 分创建的,另一个 16 点 36 分创建的。
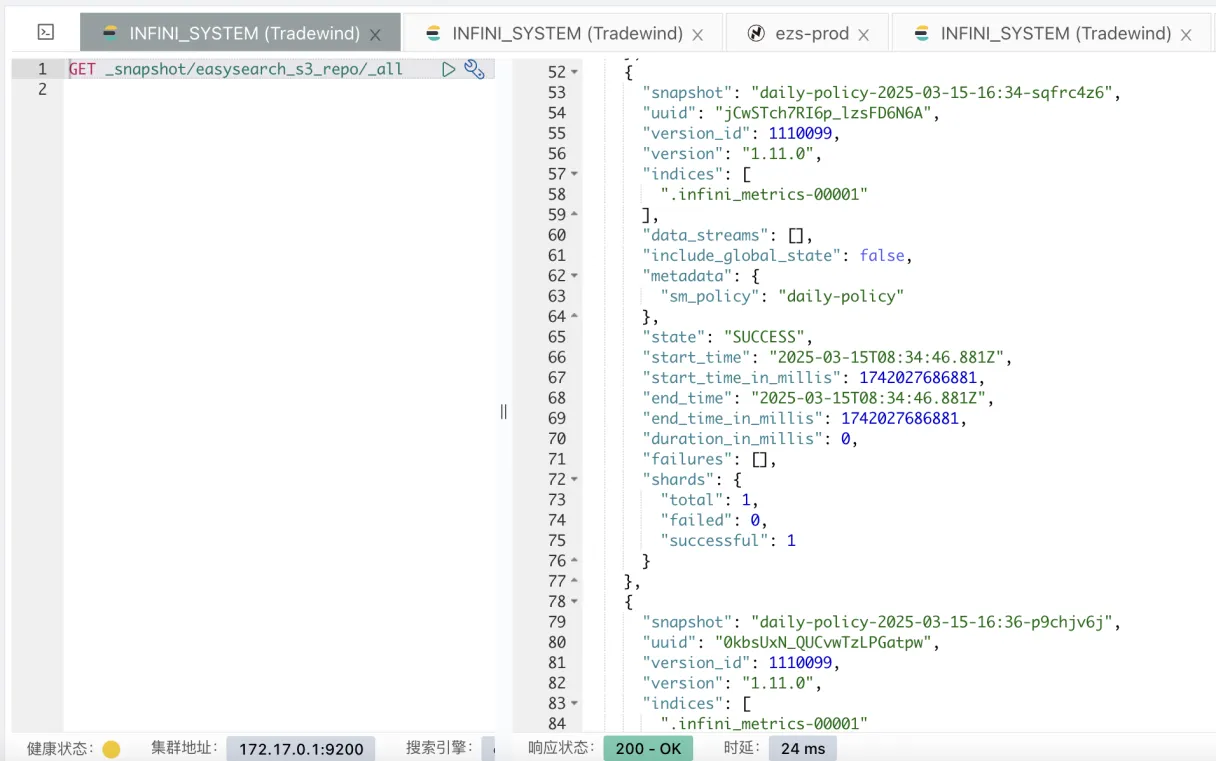
⚠️ 注意:虽然指定只保留最近两个快照,但因为创建和删除其实是两个独立的任务,所以会短暂出现存在 3 个快照的现象,等删除任务调度一次就会删除多余的快照了。
如果遇到维护需要停止自动备份,也有相应的 API 来启停快照策略。
停止策略
curl -XPOST -uadmin:admin 'https://localhost:9200/_slm/policies/daily-policy/_start'启动策略
curl -XPOST -uadmin:admin 'https://localhost:9200/_slm/policies/daily-policy/_stop'查看策略
curl -XGET -uadmin:admin 'https://localhost:9200/_slm/policies'删除策略
curl -XDELETE -uadmin:admin 'https://localhost:9200/_slm/policies/daily-policy?pretty'更多详细信息请参考官方文档。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch/main/
作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
之前介绍了 Easysearch 如何使用 S3 进行快照备份,毕竟那是手工操作。Easysearch 还提供了快照生命周期管理,能够按照策略自动创建、删除快照,极大地方便了用户的日常管理。
快照生命周期管理计划由创建计划、删除计划以及快照配置组成。
- 创建计划和删除计划包含一个 cron 表达式,指定任务的频率和时间。
- 删除计划可以指定快照保留策略,以保留过去 30 天的快照或仅保留最近的 10 个快照。
- 快照配置包括快照的索引和存储库,并支持所有通过 API 创建快照时的参数。此外,还可以指定快照名称中使用的日期的格式和时区。
快照生命周期创建的快照名称格式为 <policy _ name>-<date>-<Random number> 。
比如, 计划每 2 分钟对索引 .infini_metrics-00001 创建一个快照,并且只保留最近的 2 个快照。
curl -XPOST -uadmin:admin -H 'Content-Type: application/json' 'https://localhost:9200/_slm/policies/daily-policy' -d '
{
"description": "测试快照策略",
"creation": {
"schedule": {
"cron": {
"expression": "*/2 * * * *",
"timezone": "Asia/Shanghai"
}
},
"time_limit": "1h"
},
"deletion": {
"schedule": {
"cron": {
"expression": "*/1 * * * *",
"timezone": "Asia/Shanghai"
}
},
"condition": {
"max_count": 2
},
"time_limit": "1h"
},
"snapshot_config": {
"date_format": "yyyy-MM-dd-HH:mm",
"date_format_timezone": "Asia/Shanghai",
"indices": ".infini_metrics-00001",
"repository": "easysearch_s3_repo",
"ignore_unavailable": "true",
"include_global_state": "false"
}
}'自动创建的快照如下图,一个 16 点 34 分创建的,另一个 16 点 36 分创建的。
⚠️ 注意:虽然指定只保留最近两个快照,但因为创建和删除其实是两个独立的任务,所以会短暂出现存在 3 个快照的现象,等删除任务调度一次就会删除多余的快照了。
如果遇到维护需要停止自动备份,也有相应的 API 来启停快照策略。
停止策略
curl -XPOST -uadmin:admin 'https://localhost:9200/_slm/policies/daily-policy/_start'启动策略
curl -XPOST -uadmin:admin 'https://localhost:9200/_slm/policies/daily-policy/_stop'查看策略
curl -XGET -uadmin:admin 'https://localhost:9200/_slm/policies'删除策略
curl -XDELETE -uadmin:admin 'https://localhost:9200/_slm/policies/daily-policy?pretty'更多详细信息请参考官方文档。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch/main/
收起阅读 »作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
Easysearch S3 备份实战
Easysearch 内置了 S3 插件,这意味着用户可以直接使用该功能而无需额外安装任何插件。通过这一内置支持,用户能够方便快捷地执行 Amazon S3 上的数据快照操作。这种设计不仅简化了配置流程,也提高了工作效率,使得数据备份或迁移等任务变得更加简单易行。对于需要频繁与 S3 存储服务交互的应用场景来说,这是一个非常实用且高效的功能特性。
Minio
MinIO 是一款高性能的开源对象存储系统,专为存储大量的非结构化数据而设计。它提供了与 Amazon S3 兼容的 API,本次测试我们使用 MinIO 作为存储仓库。
建立 Bucket
进入 MinIO 管理界面,创建测试用的 bucket。
创建 Access key
测试的 Access Key 设置的比较简单。
Easysearch
为了能够使用 S3 存储,Easysearch 要进行必要的配置。
easyearch.yml
修改 easysearch.yml 配置 S3 信息。
s3.client.default.endpoint: 172.17.0.4:9000
s3.client.default.protocol: http⚠️ 注意:修改了 easysearch.yml 需要重启生效。
keystore
为了安全,我们把 S3 的 Access key 信息加入 keystore 中。
bin/easysearch-keystore add s3.client.default.access_key #输入easysearch
bin/easysearch-keystore add s3.client.default.secret_key #输入easysearch
bin/easysearch-keystore list注册存储库
在 INFINI Console 的开发工具中,使用命令注册 s3 存储库。
PUT /_snapshot/easysearch_s3_repo?verify=true&pretty
{
"type": "s3",
"settings": {
"bucket": "easysearch-bucket",
"compress": true
}
}更多参数请查看文档。
创建快照
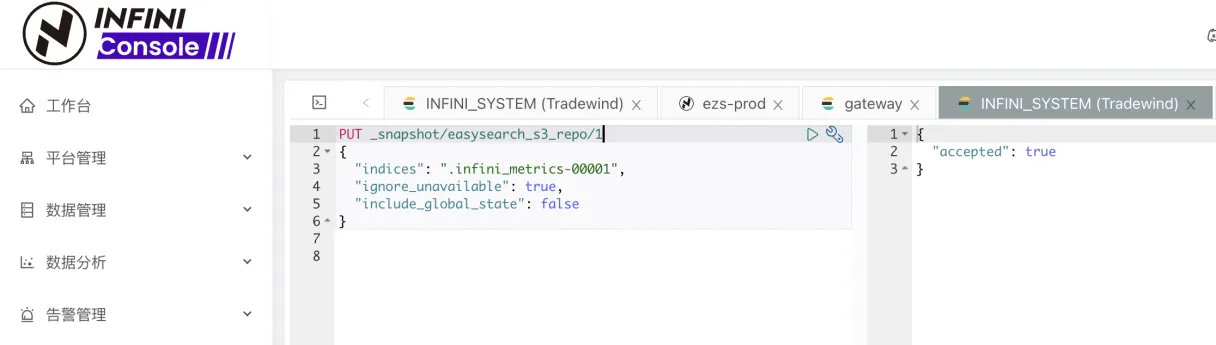
在 INFINI Console 的开发工具中,使用命令创建快照。
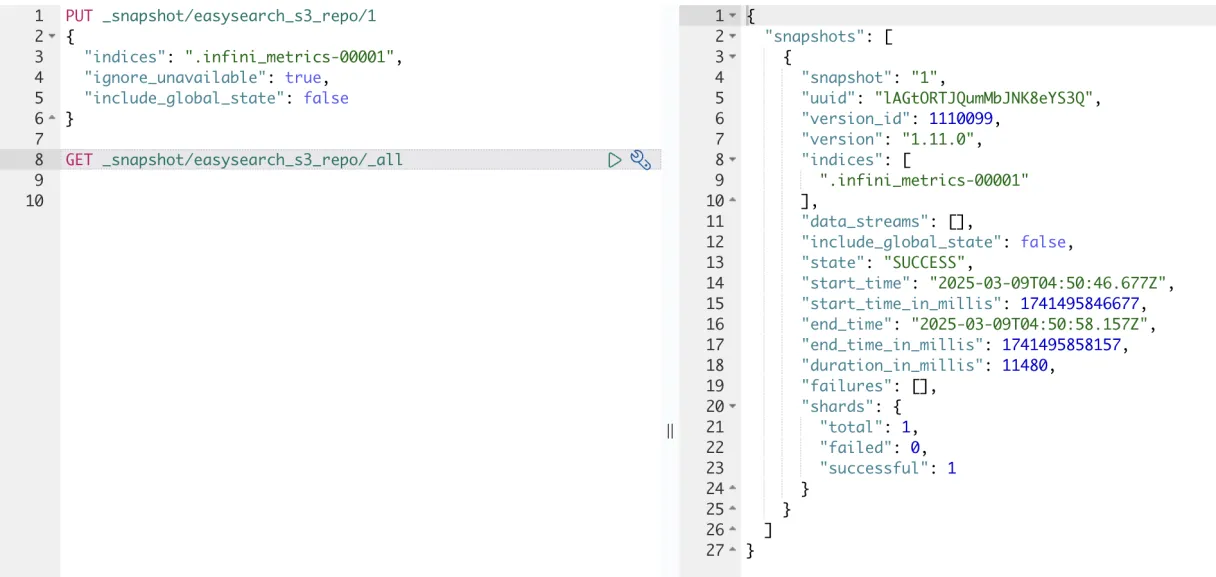
备份执行完成。
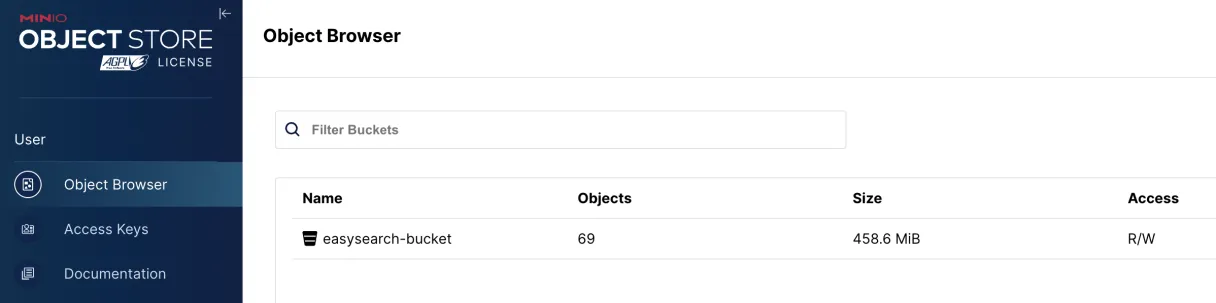
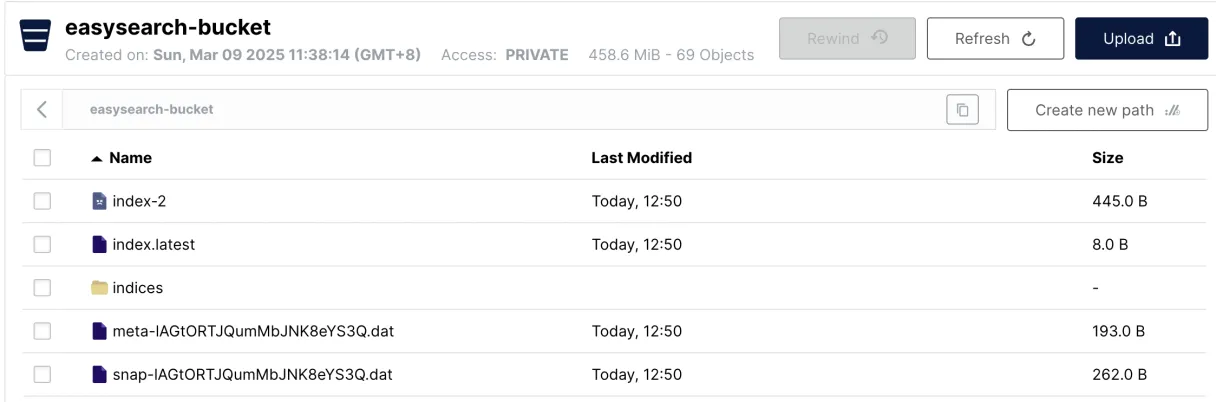
S3 查看快照
我们在 INFINI Console 中通过命令创建了快照,可以在 MinIO 的 bucket 中进行进一步确认是否有相关文件。
快照还原测试
删除以备份索引 .infini_metrics-0001,删除前先查看下索引情况,文档数 557953。
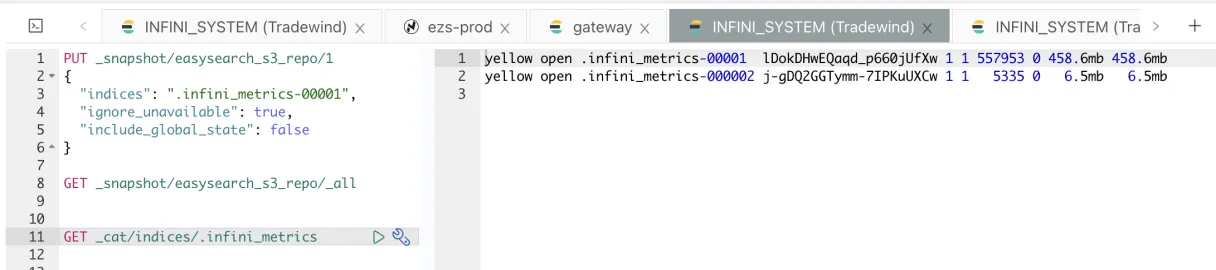
删除 .infini_metrics-0001 索引。
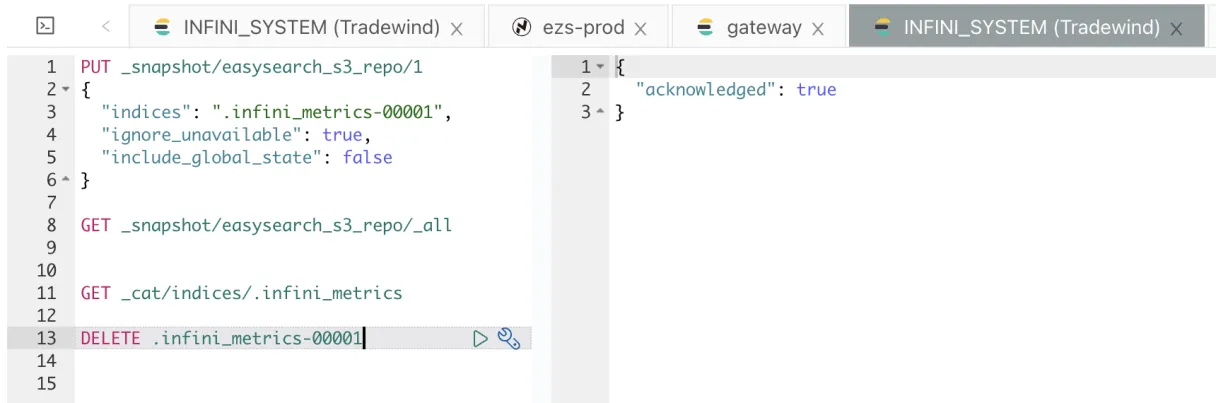
确认 .infini_metrics-0001 索引已被删除。
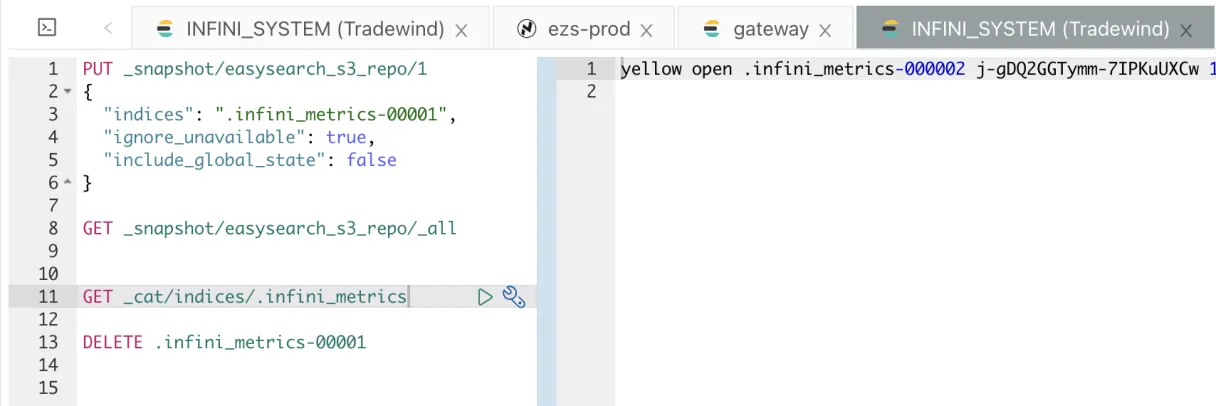
进行快照还原。
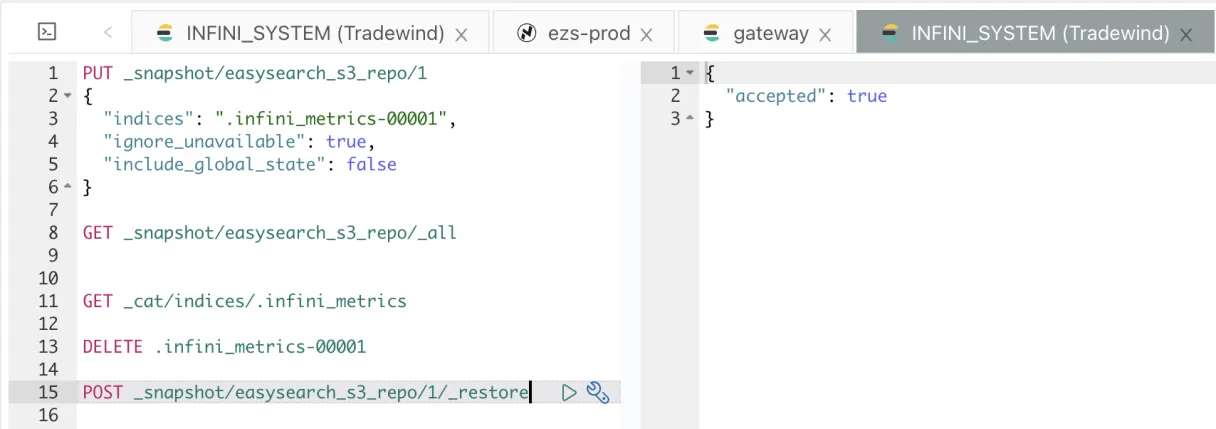
验证恢复索引。
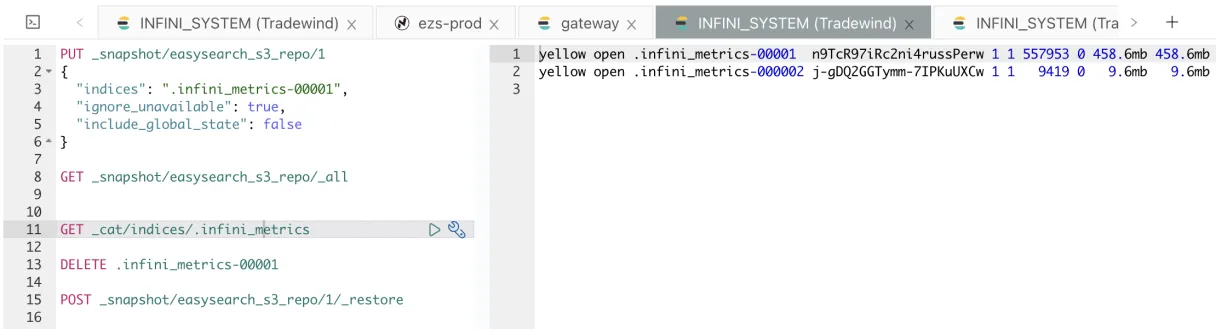
索引 .infini_metrics-0001 已经还原了,文档数也一致。
小结
Easysearch 使用 S3 存储备份的步骤如下:
- S3 服务建立 Bucket、Access Key。
- Easysearch 编辑 easysearch.yml 添加 S3 服务 endpoint 信息。
- easysearch-keystore 添加 S3 的 Access key 信息,加密保存。
- Easysearch 注册 S3 存储仓库。
- 执行快照备份。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch/main/
作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
Easysearch 内置了 S3 插件,这意味着用户可以直接使用该功能而无需额外安装任何插件。通过这一内置支持,用户能够方便快捷地执行 Amazon S3 上的数据快照操作。这种设计不仅简化了配置流程,也提高了工作效率,使得数据备份或迁移等任务变得更加简单易行。对于需要频繁与 S3 存储服务交互的应用场景来说,这是一个非常实用且高效的功能特性。
Minio
MinIO 是一款高性能的开源对象存储系统,专为存储大量的非结构化数据而设计。它提供了与 Amazon S3 兼容的 API,本次测试我们使用 MinIO 作为存储仓库。
建立 Bucket
进入 MinIO 管理界面,创建测试用的 bucket。
创建 Access key
测试的 Access Key 设置的比较简单。
Easysearch
为了能够使用 S3 存储,Easysearch 要进行必要的配置。
easyearch.yml
修改 easysearch.yml 配置 S3 信息。
s3.client.default.endpoint: 172.17.0.4:9000
s3.client.default.protocol: http⚠️ 注意:修改了 easysearch.yml 需要重启生效。
keystore
为了安全,我们把 S3 的 Access key 信息加入 keystore 中。
bin/easysearch-keystore add s3.client.default.access_key #输入easysearch
bin/easysearch-keystore add s3.client.default.secret_key #输入easysearch
bin/easysearch-keystore list注册存储库
在 INFINI Console 的开发工具中,使用命令注册 s3 存储库。
PUT /_snapshot/easysearch_s3_repo?verify=true&pretty
{
"type": "s3",
"settings": {
"bucket": "easysearch-bucket",
"compress": true
}
}更多参数请查看文档。
创建快照
在 INFINI Console 的开发工具中,使用命令创建快照。
备份执行完成。
S3 查看快照
我们在 INFINI Console 中通过命令创建了快照,可以在 MinIO 的 bucket 中进行进一步确认是否有相关文件。
快照还原测试
删除以备份索引 .infini_metrics-0001,删除前先查看下索引情况,文档数 557953。
删除 .infini_metrics-0001 索引。
确认 .infini_metrics-0001 索引已被删除。
进行快照还原。
验证恢复索引。
索引 .infini_metrics-0001 已经还原了,文档数也一致。
小结
Easysearch 使用 S3 存储备份的步骤如下:
- S3 服务建立 Bucket、Access Key。
- Easysearch 编辑 easysearch.yml 添加 S3 服务 endpoint 信息。
- easysearch-keystore 添加 S3 的 Access key 信息,加密保存。
- Easysearch 注册 S3 存储仓库。
- 执行快照备份。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch/main/
收起阅读 »作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
【搜索客社区日报】第2018期 (2025-04-09)
https://zhuanlan.zhihu.com/p/26631768854
2.RAG结合上下文提升召回成功率|Claude
https://zhuanlan.zhihu.com/p/721306620
3.RAG探索之路的血泪史及曙光
https://zhuanlan.zhihu.com/p/664921095
4.加速 HNSW 图的合并
https://mp.weixin.qq.com/s/5s2xuXKaTmznTo7bijeVqA
编辑:kin122
更多资讯:http://news.searchkit.cn
https://zhuanlan.zhihu.com/p/26631768854
2.RAG结合上下文提升召回成功率|Claude
https://zhuanlan.zhihu.com/p/721306620
3.RAG探索之路的血泪史及曙光
https://zhuanlan.zhihu.com/p/664921095
4.加速 HNSW 图的合并
https://mp.weixin.qq.com/s/5s2xuXKaTmznTo7bijeVqA
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2017期 (2025-04-08)
https://faun.pub/how-to-config ... 29bb4
2. 一个月撸150亿的日志,你来你也行(需要梯子)
https://medium.com/%40lunguh/h ... 33ab4
3. 无痛更新ES证书可行不?(需要梯子)
https://medium.com/%40ashishof ... b2a7c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://faun.pub/how-to-config ... 29bb4
2. 一个月撸150亿的日志,你来你也行(需要梯子)
https://medium.com/%40lunguh/h ... 33ab4
3. 无痛更新ES证书可行不?(需要梯子)
https://medium.com/%40ashishof ... b2a7c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2015期 (2025-04-03)
https://mp.weixin.qq.com/s/bgDd82lj0jBUWifLMNByjw
2.自动化新时代:OWL、CRAB 与 MCP 如何打通“最后一公里”
https://mp.weixin.qq.com/s/jvQRFRlADYJUtDyYQ29qQQ
3.Nvidia 收购 Run:ai 后开源的 KAI-Scheduler vs HAMi:GPU 共享的技术路线分析与协同展望
https://mp.weixin.qq.com/s/6qEdQjjh3YeSnCxGymHnHQ
4.学习如何设计大型系统
https://github.com/donnemartin ... rimer
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/bgDd82lj0jBUWifLMNByjw
2.自动化新时代:OWL、CRAB 与 MCP 如何打通“最后一公里”
https://mp.weixin.qq.com/s/jvQRFRlADYJUtDyYQ29qQQ
3.Nvidia 收购 Run:ai 后开源的 KAI-Scheduler vs HAMi:GPU 共享的技术路线分析与协同展望
https://mp.weixin.qq.com/s/6qEdQjjh3YeSnCxGymHnHQ
4.学习如何设计大型系统
https://github.com/donnemartin ... rimer
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2014期 (2025-04-02)
https://mp.weixin.qq.com/s/YRxn8Ur9Ykl6Q0ZKyuWbxQ
2.深度剖析Elasticsearch倒排索引数据结构
https://mp.weixin.qq.com/s/hDVxDCLD9UQbBk7sqcoPFQ
3.为什么 Apache Doris 是比 Elasticsearch 更好的实时分析替代方案?
https://mp.weixin.qq.com/s/JgjE-hk_MpRyXFHPhhYnyA
4.RAG与微调的实用比较
https://mp.weixin.qq.com/s/VHq_3mCNP3G9rakKPcbJtg
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/YRxn8Ur9Ykl6Q0ZKyuWbxQ
2.深度剖析Elasticsearch倒排索引数据结构
https://mp.weixin.qq.com/s/hDVxDCLD9UQbBk7sqcoPFQ
3.为什么 Apache Doris 是比 Elasticsearch 更好的实时分析替代方案?
https://mp.weixin.qq.com/s/JgjE-hk_MpRyXFHPhhYnyA
4.RAG与微调的实用比较
https://mp.weixin.qq.com/s/VHq_3mCNP3G9rakKPcbJtg
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
INFINI Labs 产品更新 | Coco AI 0.3 发布 – 新增支持 Widget 外部站点集成

INFINI Labs 产品更新发布!此次更新涵盖 Coco AI 、Easysearch 等产品多项重要升级,重点提升 AI 搜索能力、易用性及企业级优化。
- Coco AI v0.3 作为 开源、跨平台的 AI 搜索工具,新增快捷键设置,支持多个聊天会话等功能。
- Coco AI Server 新增连接器 UI 管理支持,允许用户通过请求头传递 websocket 会话 ID。
- INFINI Easysearch v1.12.0 集成 AI 向量搜索,优化 Rollup 能力。
- INFINI Console、Gateway、Agent、Loadgen、Framework 关键问题修复,优化 Security 处理与整体用户体验。
Coco AI v0.3
Coco AI 是一个完全开源、跨平台的统一 AI 搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
Coco AI v0.3.0 视频演示。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.3.0
功能更新
- 新增快捷键设置
- 支持多个聊天会话
问题修复
- 应用程序搜索移除图标不正常的候选列表
优化改进
- 重构代码,复用前端组件提供 Web Widget 外部引入
Coco AI 服务端 v0.3.0
功能更新
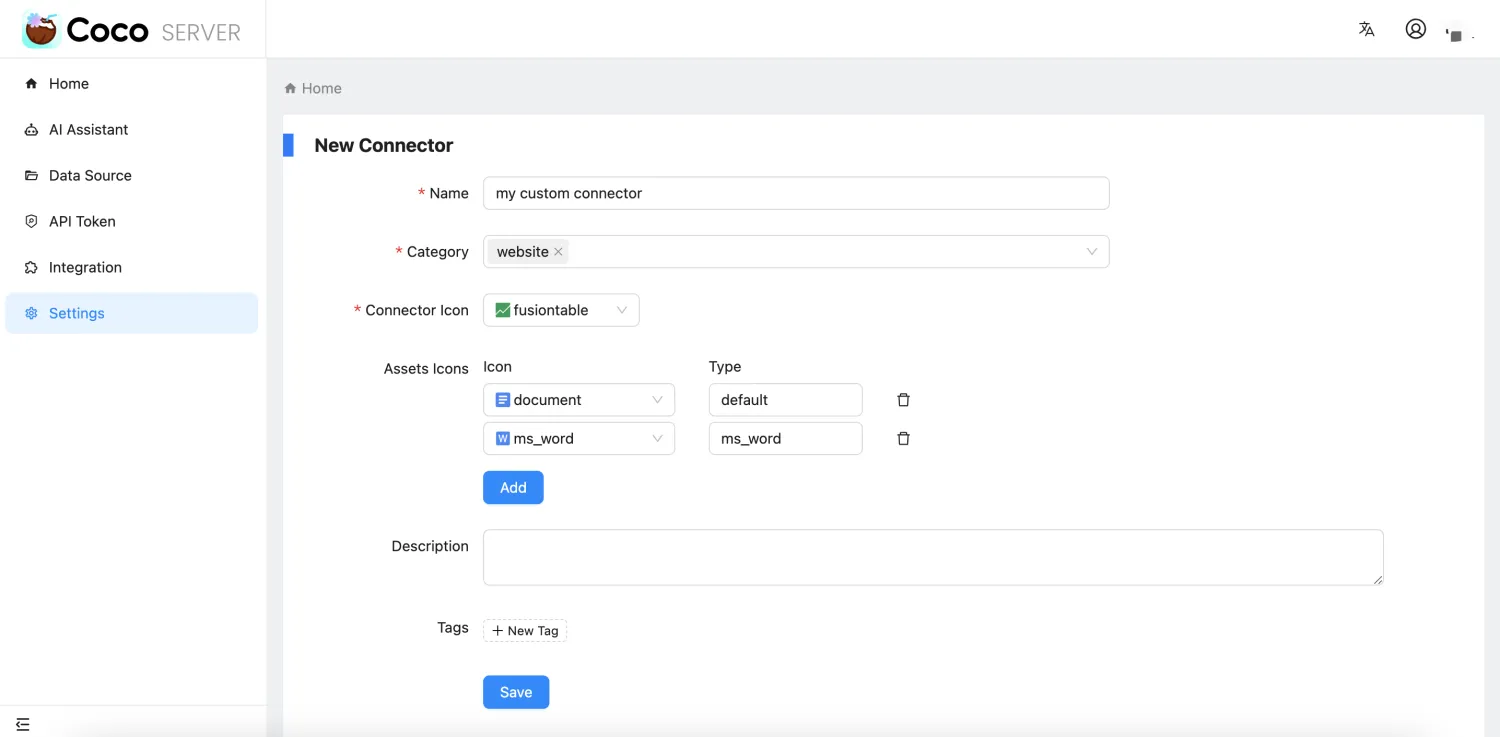
- 新增连接器 UI 管理支持
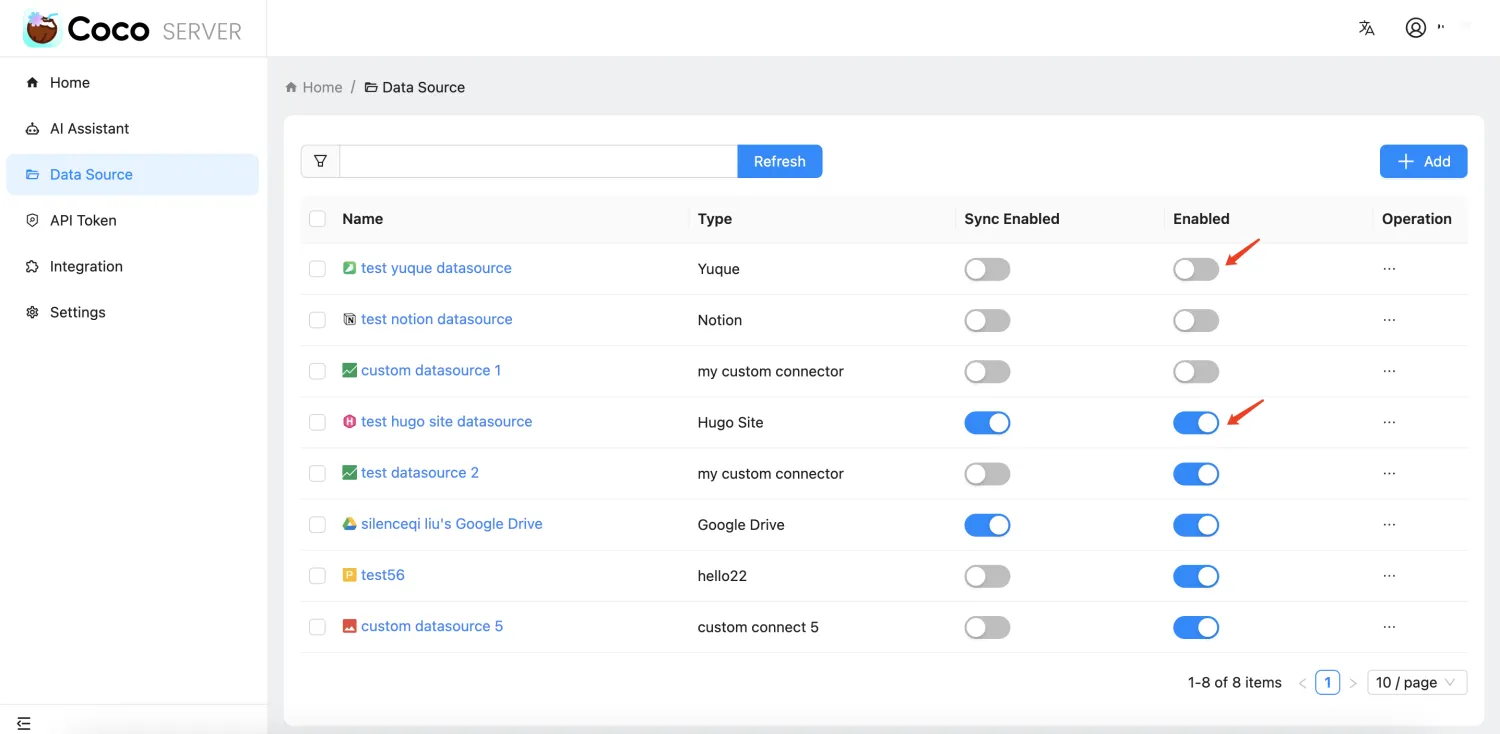
- 根据数据源的启用状态控制相关文档的可搜索性
- 允许用户通过请求头传递 websocket 会话 ID
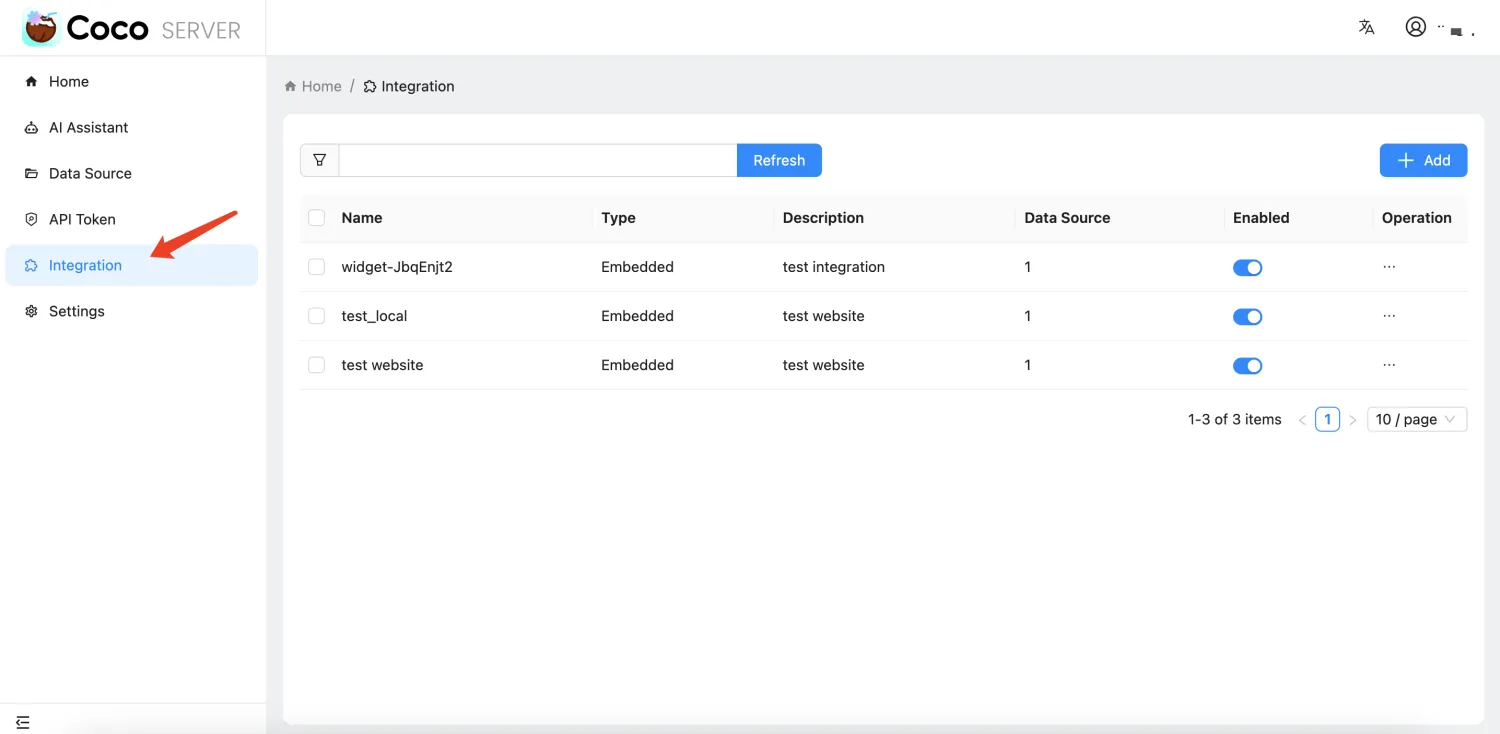
- 新增集成组件管理
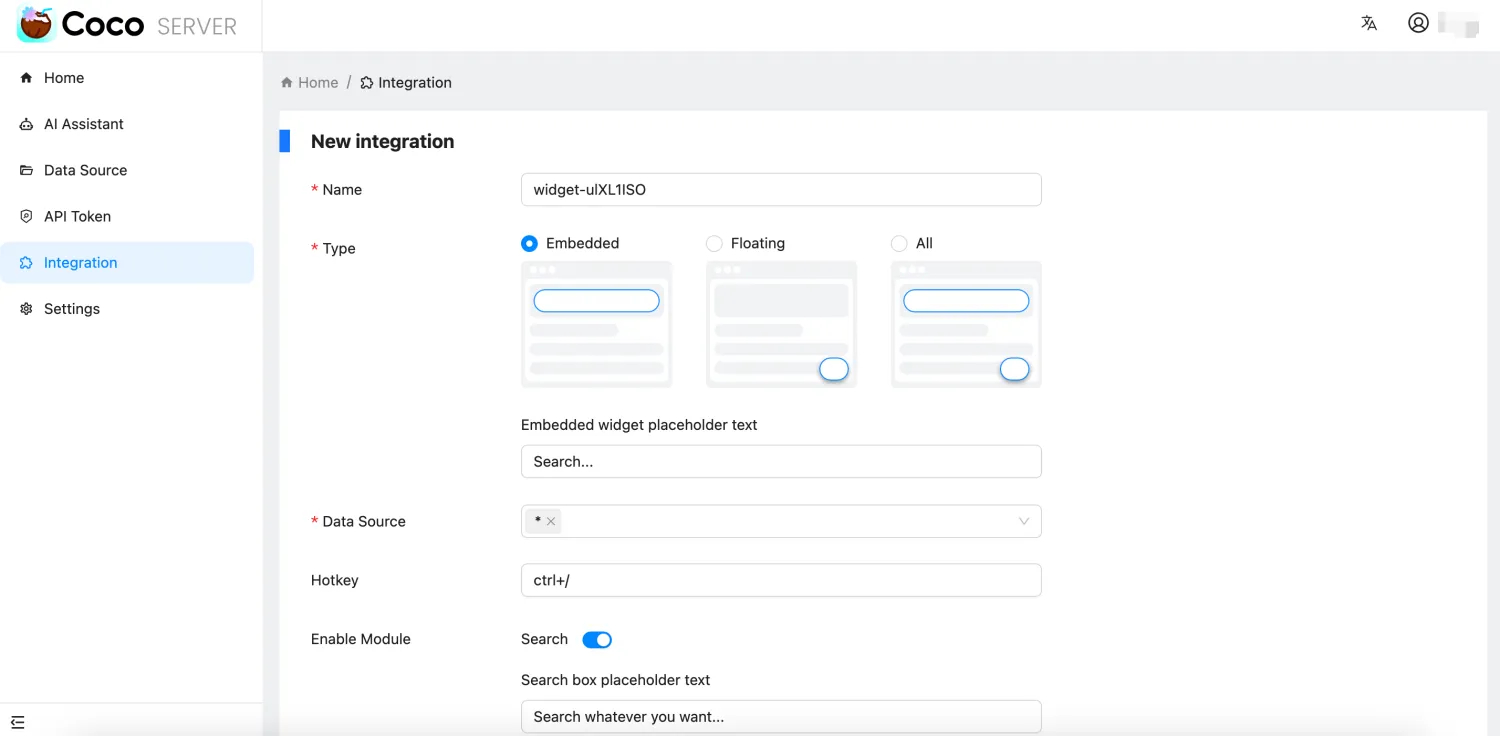
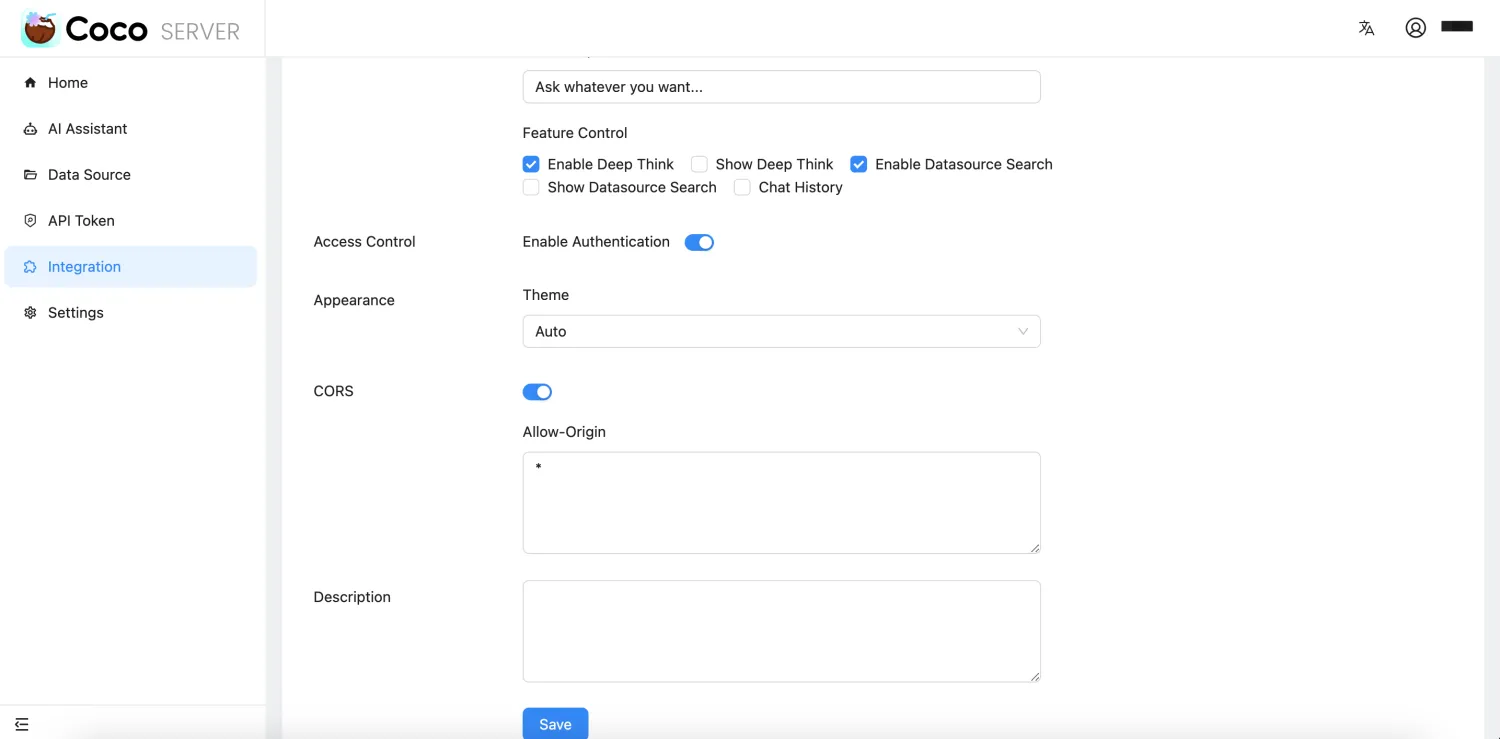
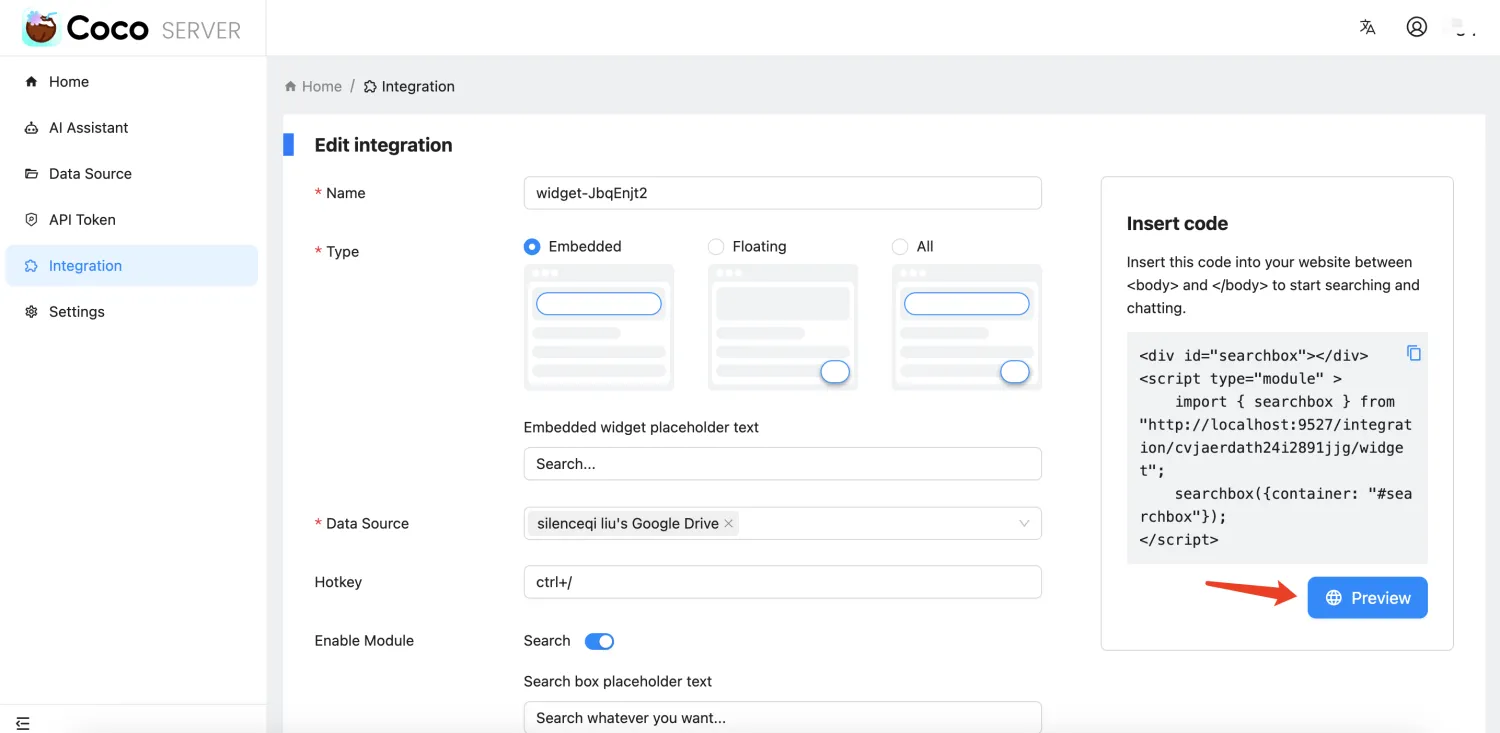
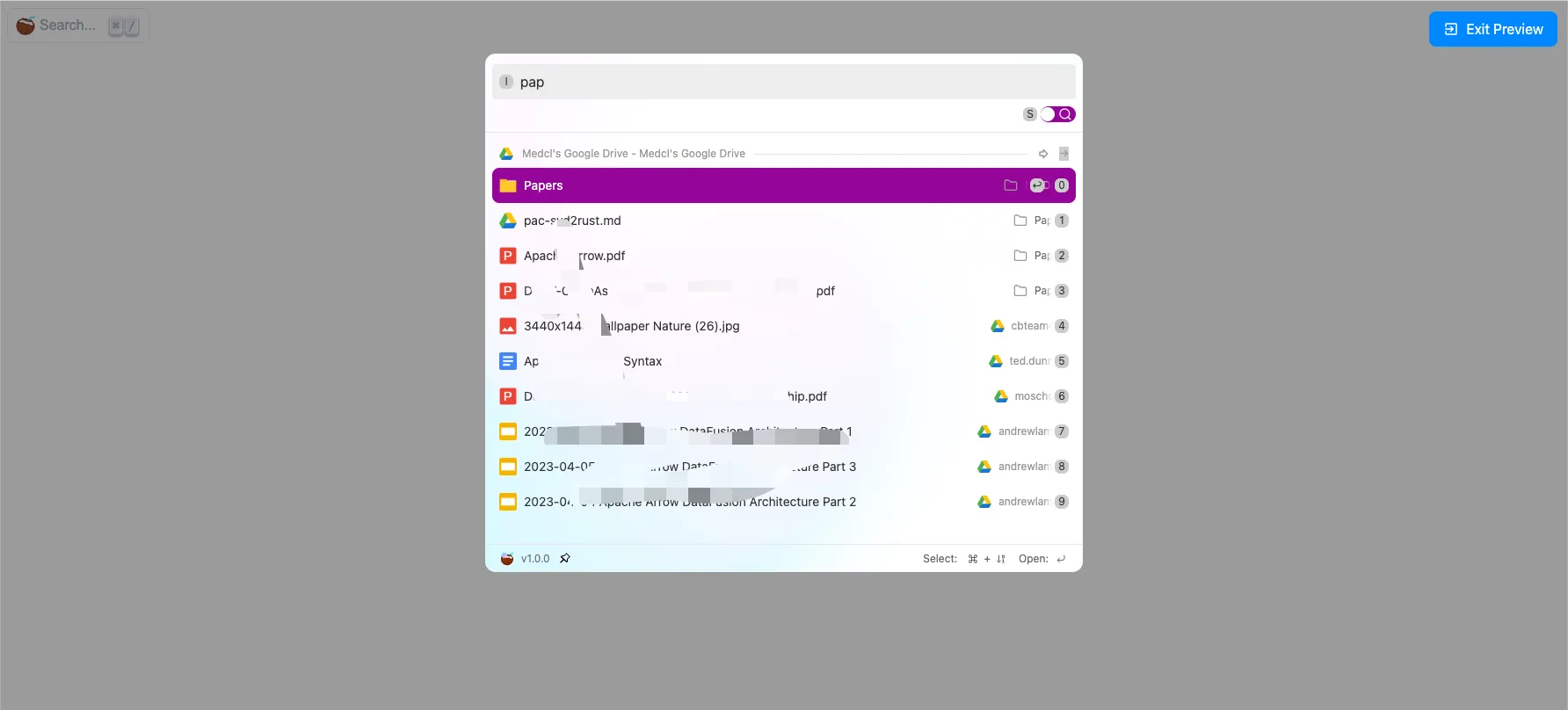
- 新增搜索框小组件,便于嵌入网站
- 新增集成 CRUD 管理和 CORS 配置支持
- 新增删除附件 API
- 新增动态 JS 封装器用于小组件
- 支持在服务端解析文档图标
- 为小组件集成添加推荐主题功能
- 新增敏感字段过滤支持
问题修复
- 修复提供商信息版本问题
- 修复数据源关键词搜索过滤未按预期工作的问题
- 修复必须条件中未选中数据源条件未被移除的问题
INFINI Easysearch v1.12.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
AI模块持续增强中,已集成Ollama embedding API,支持文本向量化Rollup新增write_optimization配置项,启用后采用自动生成文档 ID 的策略,大幅提升写入速度Rollup现在支持针对job级别配置rollover的max docs
问题修复
Rollup修复带有内嵌的 pipeline 聚合时不能和原始索引聚合正常合并的问题
优化改进
- 优化了
rollup索引字段名长度,减小rollup job运行时的内存占用
INFINI Console v1.29.2
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验:
http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
问题修复
- 修复开发工具查询长整型数据精度丢失问题
- 回滚
strict_date_optional_time去除修改,影响数据探索时间格式化
优化改进
- 优化配置中心配置自动同步时,可根据客户端实例标签进行筛选
- 优化屏幕分辨率适配,增强用户体验
INFINI Gateway v1.29.2
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
优化改进
- 同步更新 Framework v1.1.5 优化了一些已知问题
INFINI Agent v1.29.2
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
优化改进
- 同步更新 Framework v1.1.5 优化了一些已知问题
INFINI Loadgen v1.29.2
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
优化改进
- 同步更新 Framework v1.1.5 优化了一些已知问题
INFINI Framework v1.1.5
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
重大变更
- 为了 Web 模块,将认证配置 (auth config) 重构为安全配置 (security config)。
功能更新
- 通用可插拔的安全特性。
- 向 UI 处理程序添加 CORS 设置。
问题修复
- 修复默认设置为绿色 (green) 时集群初始化状态丢失的问题。
优化改进
- 重构 Elasticsearch 的错误基类。
- 避免 Redis 启动期间发生 panic。
- 跳过 JSON 序列化时任务上下文中的 Cancel 操作。
- 日志记录中不包含换行符。
- 更新日志信息。
- 向 API 添加更多选项。
- 应首先执行低优先级的过滤器。
- 将权限选项 (permission options) 重构为数组。
- 添加在 InterfaceToInt 中转换浮点数的支持。
- 添加用于访问 API 特性选项的实用工具。
- 移除不必要的锁。
- 更新 API 标签以支持接口。
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
- INFINI Easysearch
- INFINI Console
- INFINI Gateway
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
- Coco AI App
- Coco AI Server
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新发布!此次更新涵盖 Coco AI 、Easysearch 等产品多项重要升级,重点提升 AI 搜索能力、易用性及企业级优化。
- Coco AI v0.3 作为 开源、跨平台的 AI 搜索工具,新增快捷键设置,支持多个聊天会话等功能。
- Coco AI Server 新增连接器 UI 管理支持,允许用户通过请求头传递 websocket 会话 ID。
- INFINI Easysearch v1.12.0 集成 AI 向量搜索,优化 Rollup 能力。
- INFINI Console、Gateway、Agent、Loadgen、Framework 关键问题修复,优化 Security 处理与整体用户体验。
Coco AI v0.3
Coco AI 是一个完全开源、跨平台的统一 AI 搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
Coco AI v0.3.0 视频演示。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.3.0
功能更新
- 新增快捷键设置
- 支持多个聊天会话
问题修复
- 应用程序搜索移除图标不正常的候选列表
优化改进
- 重构代码,复用前端组件提供 Web Widget 外部引入
Coco AI 服务端 v0.3.0
功能更新
- 新增连接器 UI 管理支持
- 根据数据源的启用状态控制相关文档的可搜索性
- 允许用户通过请求头传递 websocket 会话 ID
- 新增集成组件管理
- 新增搜索框小组件,便于嵌入网站
- 新增集成 CRUD 管理和 CORS 配置支持
- 新增删除附件 API
- 新增动态 JS 封装器用于小组件
- 支持在服务端解析文档图标
- 为小组件集成添加推荐主题功能
- 新增敏感字段过滤支持
问题修复
- 修复提供商信息版本问题
- 修复数据源关键词搜索过滤未按预期工作的问题
- 修复必须条件中未选中数据源条件未被移除的问题
INFINI Easysearch v1.12.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
AI模块持续增强中,已集成Ollama embedding API,支持文本向量化Rollup新增write_optimization配置项,启用后采用自动生成文档 ID 的策略,大幅提升写入速度Rollup现在支持针对job级别配置rollover的max docs
问题修复
Rollup修复带有内嵌的 pipeline 聚合时不能和原始索引聚合正常合并的问题
优化改进
- 优化了
rollup索引字段名长度,减小rollup job运行时的内存占用
INFINI Console v1.29.2
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验:
http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
问题修复
- 修复开发工具查询长整型数据精度丢失问题
- 回滚
strict_date_optional_time去除修改,影响数据探索时间格式化
优化改进
- 优化配置中心配置自动同步时,可根据客户端实例标签进行筛选
- 优化屏幕分辨率适配,增强用户体验
INFINI Gateway v1.29.2
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
优化改进
- 同步更新 Framework v1.1.5 优化了一些已知问题
INFINI Agent v1.29.2
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
优化改进
- 同步更新 Framework v1.1.5 优化了一些已知问题
INFINI Loadgen v1.29.2
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
优化改进
- 同步更新 Framework v1.1.5 优化了一些已知问题
INFINI Framework v1.1.5
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
重大变更
- 为了 Web 模块,将认证配置 (auth config) 重构为安全配置 (security config)。
功能更新
- 通用可插拔的安全特性。
- 向 UI 处理程序添加 CORS 设置。
问题修复
- 修复默认设置为绿色 (green) 时集群初始化状态丢失的问题。
优化改进
- 重构 Elasticsearch 的错误基类。
- 避免 Redis 启动期间发生 panic。
- 跳过 JSON 序列化时任务上下文中的 Cancel 操作。
- 日志记录中不包含换行符。
- 更新日志信息。
- 向 API 添加更多选项。
- 应首先执行低优先级的过滤器。
- 将权限选项 (permission options) 重构为数组。
- 添加在 InterfaceToInt 中转换浮点数的支持。
- 添加用于访问 API 特性选项的实用工具。
- 移除不必要的锁。
- 更新 API 标签以支持接口。
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
- INFINI Easysearch
- INFINI Console
- INFINI Gateway
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
- Coco AI App
- Coco AI Server
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第2012期 (2025-03-31)
https://infinilabs.cn/blog/202 ... ison/
2、如何使用 Grafana 连接 Easyearch
https://infinilabs.cn/blog/202 ... arch/
3、不建 Hugo、不用 Hexo,纯 Markdown 文件也能接入 Coco-AI!
https://mp.weixin.qq.com/s/Xvn1CcQqlVOREY0fSI2A4w
4、Manus的技术实现原理浅析与简单复刻
https://mp.weixin.qq.com/s/SSO-w6FF4mBm2zrXY5RzkA
5、深入解读大模型开发工具Dify--底层数据存储
https://blog.csdn.net/weixin_4 ... 37251
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... ison/
2、如何使用 Grafana 连接 Easyearch
https://infinilabs.cn/blog/202 ... arch/
3、不建 Hugo、不用 Hexo,纯 Markdown 文件也能接入 Coco-AI!
https://mp.weixin.qq.com/s/Xvn1CcQqlVOREY0fSI2A4w
4、Manus的技术实现原理浅析与简单复刻
https://mp.weixin.qq.com/s/SSO-w6FF4mBm2zrXY5RzkA
5、深入解读大模型开发工具Dify--底层数据存储
https://blog.csdn.net/weixin_4 ... 37251
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »


