

【搜索客社区日报】第2029期 (2025-04-28)
https://infinilabs.cn/blog/202 ... ions/
2、Easysearch S3 备份实战
https://mp.weixin.qq.com/s/3ClNHwfTSZrHYzLmBD1CzQ
3、Manus 完整版系统提示词
https://mp.weixin.qq.com/s/xT2R2o_P1DrQ3MJGmhZ_7w
4、Elasticsearch推理API设置分块策略
https://mp.weixin.qq.com/s/CIZfsNn_J4Q_n1kFlylx8w
5、Elasticsearch 8.18 ES|QL Join 功能实战
https://mp.weixin.qq.com/s/7ZUVuvabXF4L955ncs-Pqw
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... ions/
2、Easysearch S3 备份实战
https://mp.weixin.qq.com/s/3ClNHwfTSZrHYzLmBD1CzQ
3、Manus 完整版系统提示词
https://mp.weixin.qq.com/s/xT2R2o_P1DrQ3MJGmhZ_7w
4、Elasticsearch推理API设置分块策略
https://mp.weixin.qq.com/s/CIZfsNn_J4Q_n1kFlylx8w
5、Elasticsearch 8.18 ES|QL Join 功能实战
https://mp.weixin.qq.com/s/7ZUVuvabXF4L955ncs-Pqw
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
上一篇咱们了解了 ES 7.10 相较于 ES 6.8 新增的字段类型,这一篇我们继续了解新增的查询方法。
Interval 间隔查询:
功能介绍
Interval 查询,词项间距查询,可以根据匹配词项的顺序、间距和接近度对文档进行排名。主要解决的查询场景“创建一个多搜索词匹配的查询,同时保留搜索词的顺序”,比 match phrase 更加符合需求场景,查询方法使用比 span 查询更简单。ES 后续版本想用 interval 查询逐步替代 span 查询。
注意事项
规则组合
- 可以使用 prefix、wildcard、fuzzy 等规则
- 通过设置 max_gaps 和 ordered 参数,可以控制词项间的最大间隙和顺序要求。
性能考虑
- 间隔查询比简单的词项匹配更消耗资源
- 嵌套规则越多,性能开销越大
- 建议合理使用 maxGaps 参数限制间距
使用限制
- 只能用于 text 字段
- 不支持跨字段查询
- 不支持对数值类型字段使用
Distance feature 查询
功能说明
时间/地理距离特性查询,该查询用于查找更接近被查询日期和地理位置的结果。 日期和位置分别是声明为 date 和 geo_point 数据类型的字段。返回结果的字段值不需要完全等于被查询值,而是按照给定日期或给定位置的进度算分,越是接近被查询值,在相关性得分中被评为更高。
字段类型要求
- 日期字段必须是 date 类型,地理位置字段必须是 geo_point 类型
- 不支持其他类型的距离计算
评分机制
- 距离越近,得分越高
- 使用 boost 参数调整权重
- 可以与其他查询组合使用
性能考虑
- 地理距离计算较为耗费资源,建议使用合适的索引优化地理查询,比如:考虑使用地理网格索引提升性能
Pinned 查询
功能说明
实现对某些文档的置顶功能,使用存储在_id 字段中的文档 ID 来标识升级或“固定”的文档。
此功能通常用于引导搜索者查找精选的文档,这些文档在搜索的任何 “organic” 匹配项之上被提升。当查询中有排序时,pinned 查询失效。
使用限制
- 不能与自定义排序一起使用
- 置顶文档必须存在于索引中
- 最多支持 100 个置顶文档
排序规则
- 置顶文档按照 ids 数组中的顺序排序
- organic 查询结果按照相关性得分排序
- 置顶文档始终在 organic 结果之前
PIT 查询
功能说明
Point in time 查询是一个轻量级的视图,根据保留周期保留 PIT 查询发生时数据的状态,用于不同条件的深度分页查询。
scroll 滚动搜索及其上下文与查询内容绑定。这意味着编写一个查询,添加一个滚动参数,来自这个查询的响应数据就会保持一致。不同的查询内容则会产生不同的 scroll 上下文,资源使用就会相对紧张。有时想对同一固定数据集适时运行不同的查询,就需要 PIT 查询。
如果对于一个不断变化的索引有着很高的搜索负载,那么为每个请求创建一个新的时间点查询会使用相当多的资源。可以通过使用一个后台进程每隔几分钟创建一个时间点 id 并将其用于所有搜索请求的方式来优化资源使用
更多内容可以参照这里
注意事项
资源管理
- PIT 会占用系统资源,需要及时释放
- 建议设置合理的保留时间
- 监控 open context 数量
使用场景
- 适合需要一致性视图的场景
- 适合需要深度分页的场景
- 适合需要在固定数据集上执行多次查询的场景
性能优化
- 避免过长的保留时间,合理设置批次大小
- 建议查询的时候带 sort 参数排序
测试代码
// 1. 使用 product_test 索引,创建 PIT
POST /product_test/_pit?keep_alive=1m
GET /_search
{
"size": 1,
"query": {
"match": {
"model": "iphone"
}
},
"pit": {
"id": "i6-xAwEMcHJvZHVjdF90ZXN0FmRObXltV3ZDU1VTTnllYjNoR0ZtamcAFk1GQklTWXBaUkllb2h1cGl1VVFsdUEAAAAAAAABZk8WOFVoUHBhN3BSVVN5TWVmeTh4d3JpdwEWZE5teW1XdkNTVVNOeWViM2hHRm1qZwAA",
"keep_alive": "1m"
},
"sort": [
{"_score": "desc"},
{"_id": "asc"}
]
}
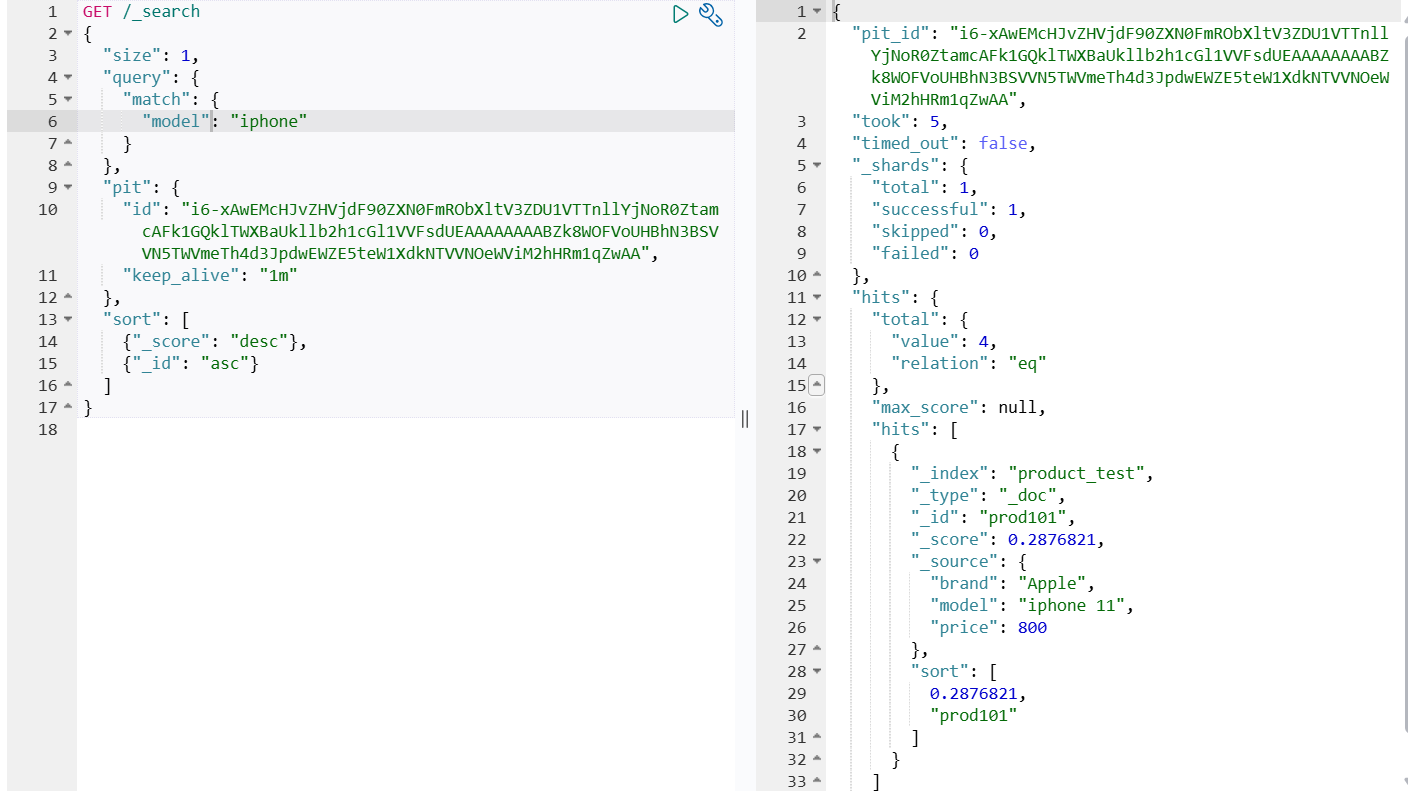
DELETE /_pit
{"id":"i6-xAwEMcHJvZHVjdF90ZXN0FmRObXltV3ZDU1VTTnllYjNoR0ZtamcAFk1GQklTWXBaUkllb2h1cGl1VVFsdUEAAAAAAAABZk8WOFVoUHBhN3BSVVN5TWVmeTh4d3JpdwEWZE5teW1XdkNTVVNOeWViM2hHRm1qZwAA"}
小结
作为查询方法,Elasticsearch 新增的几个功能面对的场景更加具象且方便,大家可以根据业务的场景特性可以优化使用。其中深度分页查询是 ES 使用者几乎避免不了的场景,PIT 查询也是提供了一个更为优质的方法。
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(1)- 性能优化篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(2)- 字段类型篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/feature-evolution-from-elasticsearch-6.8-to-7.10-part-3/
上一篇咱们了解了 ES 7.10 相较于 ES 6.8 新增的字段类型,这一篇我们继续了解新增的查询方法。
Interval 间隔查询:
功能介绍
Interval 查询,词项间距查询,可以根据匹配词项的顺序、间距和接近度对文档进行排名。主要解决的查询场景“创建一个多搜索词匹配的查询,同时保留搜索词的顺序”,比 match phrase 更加符合需求场景,查询方法使用比 span 查询更简单。ES 后续版本想用 interval 查询逐步替代 span 查询。
注意事项
规则组合
- 可以使用 prefix、wildcard、fuzzy 等规则
- 通过设置 max_gaps 和 ordered 参数,可以控制词项间的最大间隙和顺序要求。
性能考虑
- 间隔查询比简单的词项匹配更消耗资源
- 嵌套规则越多,性能开销越大
- 建议合理使用 maxGaps 参数限制间距
使用限制
- 只能用于 text 字段
- 不支持跨字段查询
- 不支持对数值类型字段使用
Distance feature 查询
功能说明
时间/地理距离特性查询,该查询用于查找更接近被查询日期和地理位置的结果。 日期和位置分别是声明为 date 和 geo_point 数据类型的字段。返回结果的字段值不需要完全等于被查询值,而是按照给定日期或给定位置的进度算分,越是接近被查询值,在相关性得分中被评为更高。
字段类型要求
- 日期字段必须是 date 类型,地理位置字段必须是 geo_point 类型
- 不支持其他类型的距离计算
评分机制
- 距离越近,得分越高
- 使用 boost 参数调整权重
- 可以与其他查询组合使用
性能考虑
- 地理距离计算较为耗费资源,建议使用合适的索引优化地理查询,比如:考虑使用地理网格索引提升性能
Pinned 查询
功能说明
实现对某些文档的置顶功能,使用存储在_id 字段中的文档 ID 来标识升级或“固定”的文档。
此功能通常用于引导搜索者查找精选的文档,这些文档在搜索的任何 “organic” 匹配项之上被提升。当查询中有排序时,pinned 查询失效。
使用限制
- 不能与自定义排序一起使用
- 置顶文档必须存在于索引中
- 最多支持 100 个置顶文档
排序规则
- 置顶文档按照 ids 数组中的顺序排序
- organic 查询结果按照相关性得分排序
- 置顶文档始终在 organic 结果之前
PIT 查询
功能说明
Point in time 查询是一个轻量级的视图,根据保留周期保留 PIT 查询发生时数据的状态,用于不同条件的深度分页查询。
scroll 滚动搜索及其上下文与查询内容绑定。这意味着编写一个查询,添加一个滚动参数,来自这个查询的响应数据就会保持一致。不同的查询内容则会产生不同的 scroll 上下文,资源使用就会相对紧张。有时想对同一固定数据集适时运行不同的查询,就需要 PIT 查询。
如果对于一个不断变化的索引有着很高的搜索负载,那么为每个请求创建一个新的时间点查询会使用相当多的资源。可以通过使用一个后台进程每隔几分钟创建一个时间点 id 并将其用于所有搜索请求的方式来优化资源使用
更多内容可以参照这里
注意事项
资源管理
- PIT 会占用系统资源,需要及时释放
- 建议设置合理的保留时间
- 监控 open context 数量
使用场景
- 适合需要一致性视图的场景
- 适合需要深度分页的场景
- 适合需要在固定数据集上执行多次查询的场景
性能优化
- 避免过长的保留时间,合理设置批次大小
- 建议查询的时候带 sort 参数排序
测试代码
// 1. 使用 product_test 索引,创建 PIT
POST /product_test/_pit?keep_alive=1m
GET /_search
{
"size": 1,
"query": {
"match": {
"model": "iphone"
}
},
"pit": {
"id": "i6-xAwEMcHJvZHVjdF90ZXN0FmRObXltV3ZDU1VTTnllYjNoR0ZtamcAFk1GQklTWXBaUkllb2h1cGl1VVFsdUEAAAAAAAABZk8WOFVoUHBhN3BSVVN5TWVmeTh4d3JpdwEWZE5teW1XdkNTVVNOeWViM2hHRm1qZwAA",
"keep_alive": "1m"
},
"sort": [
{"_score": "desc"},
{"_id": "asc"}
]
}
DELETE /_pit
{"id":"i6-xAwEMcHJvZHVjdF90ZXN0FmRObXltV3ZDU1VTTnllYjNoR0ZtamcAFk1GQklTWXBaUkllb2h1cGl1VVFsdUEAAAAAAAABZk8WOFVoUHBhN3BSVVN5TWVmeTh4d3JpdwEWZE5teW1XdkNTVVNOeWViM2hHRm1qZwAA"}
小结
作为查询方法,Elasticsearch 新增的几个功能面对的场景更加具象且方便,大家可以根据业务的场景特性可以优化使用。其中深度分页查询是 ES 使用者几乎避免不了的场景,PIT 查询也是提供了一个更为优质的方法。
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(1)- 性能优化篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(2)- 字段类型篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/feature-evolution-from-elasticsearch-6.8-to-7.10-part-3/
【直播预告】开源智能搜索与知识管理革新 —— Coco AI 全景解读
4 月 28 日(周一)19:00,INFINI Labs 与 GitCode 联合为您带来 Coco AI 专场直播!本次直播将深度剖析 Coco AI 的核心功能、技术架构及其在实际场景中的应用,带您领略智能搜索与知识管理的全新变革。精彩不容错过,快来预约观看吧!👇

直播时间: 2025-04-28 19:00
直播平台: GitCode 视频号 、CSDN 双端、极限实验室视频号
CSDN 直播间地址 👇
https://live.csdn.net/room/csdnedu/q6BD0Kui
直播主题
开源智能搜索与知识管理革新 —— Coco AI 全景解读
直播简介
在人工智能技术飞速发展的今天,如何高效管理海量信息、实现智能搜索与知识共享,已成为个人与企业共同面临的挑战。本次直播将全面解析 Coco AI —— 由极限科技(INFINI Labs)推出的开源、跨平台智能搜索与知识库管理工具,带您探索其核心功能、技术架构及实际应用场景。
无论您是希望优化知识管理的个人,还是期望建立高效信息生态的企业,亦或是对技术实现感兴趣的开发者,本次直播都将是您不可错过的学习与交流机会。
直播主题及嘉宾介绍
主题一 :《下一代 AI 搜索工具 - Coco AI 介绍》
主题摘要: Coco AI 是由极限科技推出的一款完全开源且免费的智能搜索与 AI 知识库工具。本次分享将深入介绍 Coco AI 的核心功能,并探讨如何融合人工智能与搜索技术,实现智能化搜索与知识管理的全面优化,从而有效提升企业协作效率与个人生产力。
分享嘉宾: 曾勇,极限科技 / INFINI Labs 创始人兼 CEO,现正带领团队专注于下一代实时搜索引擎与 AI 智能搜索相关技术的研发与创新。
主题二 :《使用 Coco AI 打造 ES 专用工具箱》
主题摘要: 基于 Coco AI 打造了专门针对 ES 的工具箱,旨在通过快速、高效、准确的数据检索,解决 ES 使用过程中常见的问题,提升工作效率。
分享嘉宾: 杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
主题三 :《Coco AI 技术选型-Tauri v2 的优劣》
主题摘要: Tauri v2 是一款基于 Rust 的跨平台应用开发框架,凭借其轻量化、高性能和扩展性,成为近年来替代 Electron 的热门选择。尤其在 AI 应用开发中,Tauri v2 凭借其独特优势吸引了开发者关注,但也存在一些局限性需权衡。
分享嘉宾: 张斌,极限科技(INFINI Labs)Coco AI 前端研发负责人,拥有丰富的全栈开发经验,专注于 Web 技术与系统架构设计,致力于构建高效、可扩展的应用系统。擅长 JavaScript/TypeScript 生态,熟悉大数据处理和人工智能等前沿技术,具备深厚的工程实践背景,持续探索技术的边界与创新的可能。
关于 Gitcode

GitCode 新一代由 AI 驱动的开源开发者平台,依托 CSDN 开发者社区,通过集成代码托管服务、代码仓库和可信赖的开源组件库,使开发者能够在云端进行代码托管和开发,平台提供了丰富的功能支持和完善的生态体系,帮助开发者轻松管理和分享代码,为开源项目提供强有力的支持。
关于 Coco AI

Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
GitCode:https://gitcode.com/infinilabs/coco-app
Github:https://github.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
4 月 28 日(周一)19:00,INFINI Labs 与 GitCode 联合为您带来 Coco AI 专场直播!本次直播将深度剖析 Coco AI 的核心功能、技术架构及其在实际场景中的应用,带您领略智能搜索与知识管理的全新变革。精彩不容错过,快来预约观看吧!👇
直播时间: 2025-04-28 19:00
直播平台: GitCode 视频号 、CSDN 双端、极限实验室视频号
CSDN 直播间地址 👇
https://live.csdn.net/room/csdnedu/q6BD0Kui
直播主题
开源智能搜索与知识管理革新 —— Coco AI 全景解读
直播简介
在人工智能技术飞速发展的今天,如何高效管理海量信息、实现智能搜索与知识共享,已成为个人与企业共同面临的挑战。本次直播将全面解析 Coco AI —— 由极限科技(INFINI Labs)推出的开源、跨平台智能搜索与知识库管理工具,带您探索其核心功能、技术架构及实际应用场景。
无论您是希望优化知识管理的个人,还是期望建立高效信息生态的企业,亦或是对技术实现感兴趣的开发者,本次直播都将是您不可错过的学习与交流机会。
直播主题及嘉宾介绍
主题一 :《下一代 AI 搜索工具 - Coco AI 介绍》
主题摘要: Coco AI 是由极限科技推出的一款完全开源且免费的智能搜索与 AI 知识库工具。本次分享将深入介绍 Coco AI 的核心功能,并探讨如何融合人工智能与搜索技术,实现智能化搜索与知识管理的全面优化,从而有效提升企业协作效率与个人生产力。
分享嘉宾: 曾勇,极限科技 / INFINI Labs 创始人兼 CEO,现正带领团队专注于下一代实时搜索引擎与 AI 智能搜索相关技术的研发与创新。
主题二 :《使用 Coco AI 打造 ES 专用工具箱》
主题摘要: 基于 Coco AI 打造了专门针对 ES 的工具箱,旨在通过快速、高效、准确的数据检索,解决 ES 使用过程中常见的问题,提升工作效率。
分享嘉宾: 杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
主题三 :《Coco AI 技术选型-Tauri v2 的优劣》
主题摘要: Tauri v2 是一款基于 Rust 的跨平台应用开发框架,凭借其轻量化、高性能和扩展性,成为近年来替代 Electron 的热门选择。尤其在 AI 应用开发中,Tauri v2 凭借其独特优势吸引了开发者关注,但也存在一些局限性需权衡。
分享嘉宾: 张斌,极限科技(INFINI Labs)Coco AI 前端研发负责人,拥有丰富的全栈开发经验,专注于 Web 技术与系统架构设计,致力于构建高效、可扩展的应用系统。擅长 JavaScript/TypeScript 生态,熟悉大数据处理和人工智能等前沿技术,具备深厚的工程实践背景,持续探索技术的边界与创新的可能。
关于 Gitcode
GitCode 新一代由 AI 驱动的开源开发者平台,依托 CSDN 开发者社区,通过集成代码托管服务、代码仓库和可信赖的开源组件库,使开发者能够在云端进行代码托管和开发,平台提供了丰富的功能支持和完善的生态体系,帮助开发者轻松管理和分享代码,为开源项目提供强有力的支持。
关于 Coco AI
Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
GitCode:https://gitcode.com/infinilabs/coco-app
Github:https://github.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
收起阅读 »Coco AI 入驻 GitCode:打破数据孤岛,解锁智能协作新可能
在信息爆炸时代,企业正面临前所未有的挑战:
- 企业数据和信息分散,数据孤岛现象严重,员工往往浪费大量时间跨平台检索;
- 跨部门协作困难,团队因信息隔阂导致项目延期;
- 数据安全问题严峻,迫使企业对数据管理提出高要求;
- 传统搜索准确率不足,无法满足用户深层次需求;
这正是 Coco AI 诞生的契机——一款重新定义企业效率的智能中枢。
Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,深度融合大语言模型技术,实现从"人找信息"到"信息追人"的范式革命。目前已加入 GitCode 平台成为 G-Star 优秀毕业项目。通过连接 Google Workspace、Notion、语雀等 200+ 数据源,接入 DeepSeek 等大模型,构建企业级智能知识图谱,让数据真正流动起来,帮助企业高效管理和利用内外部数据资源。

多种功能 一次集合
全域智能搜索
- Coco AI 支持整合企业内部和外部的多种数据源,包括 Google Workspace、Dropbox、GitHub、本地文件系统等。
- 提供统一的搜索界面,用户无需切换多个平台即可快速检索所需信息。
AI 知识管家
- 内置基于生成式 AI 的聊天助手,能够理解企业内部的文档、对话记录和工作流程。
- 支持从互联网、内部知识库和指定数据源中提取信息,提供与组织相关的智能回答。
- 支持在搜索模式和聊天模式之间快速切换。
企业安全中枢
- 遵循企业级权限管理规范,确保数据访问的安全性。
- 支持私有化部署,满足企业对数据隐私的高要求。
- 允许开发者根据需求进行定制和扩展,支持企业自行部署,确保数据隐私和安全。
协作生态集成
- 用户可以直接与单个文件或数据源进行交互,例如对文档内容提问或生成摘要。
- 通过整合团队常用的工具和数据源,提升团队协作效率。
- 支持基于上下文的多轮对话,帮助团队成员快速获取所需信息。
- 在 1 分钟内轻松将 Coco AI 功能嵌入到您的网站中。
架构设计图
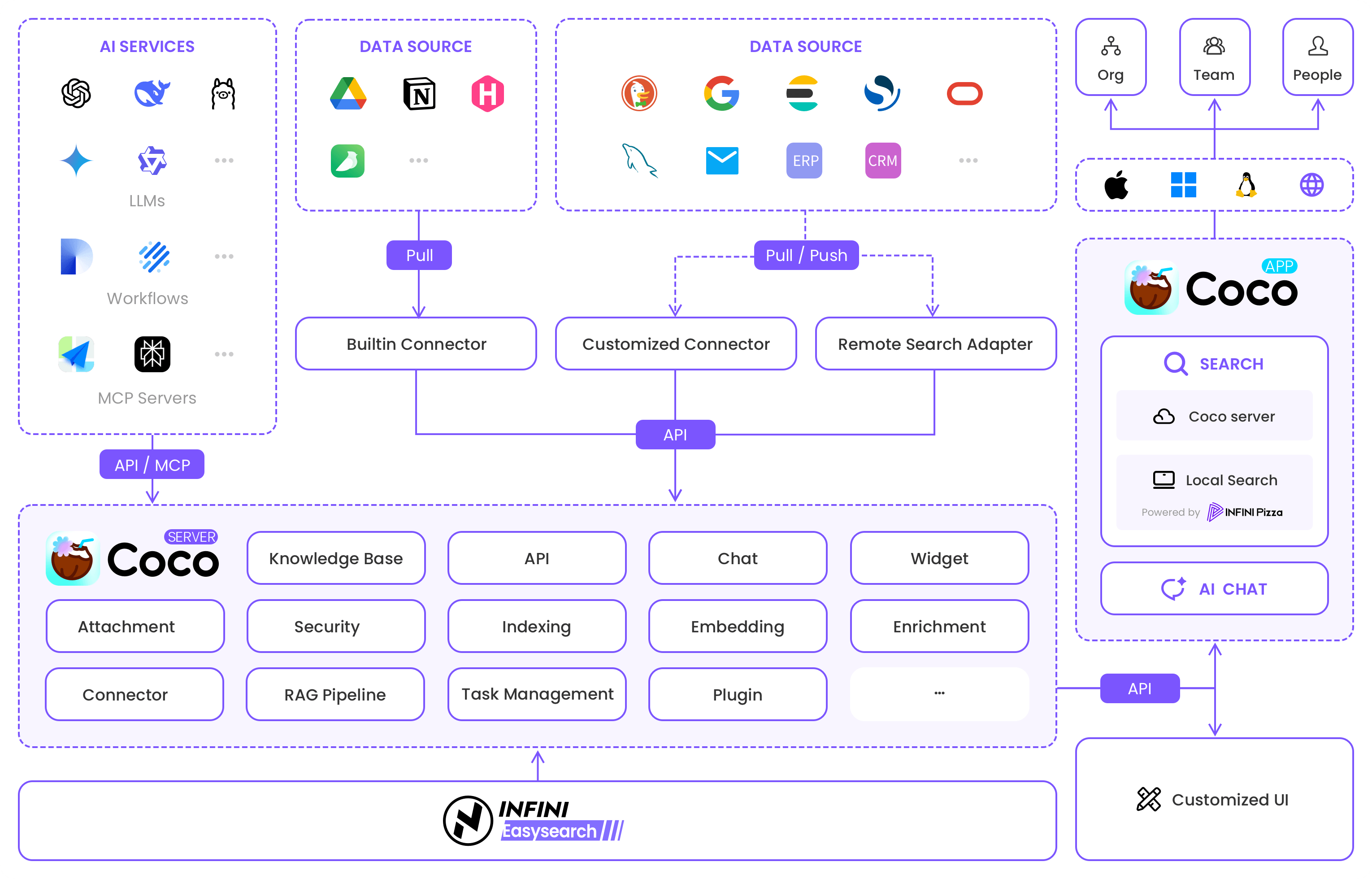
核心模块 “Coco Server” 提供搜索、聊天、附件管理、索引、嵌入、安全等功能,并通过 API 实现与外部系统的交互。同时,系统支持自定义 UI,为用户提供个性化的搜索和任务管理体验,并通过 AI 助手提供智能化的信息交互体验。
从 V0.3 到行业标准,Coco AI 持续进化,致力于推动知识管理和信息检索的变革,加速企业数字化转型。
立即访问
来 GitCode 了解 Coco AI,让您的企业获得:
- 每年节省百万级人力成本
- 打造永不遗忘的组织和大脑
- 激活数据资产的复合价值
开源可许:
MIT License
项目地址:
https://gitcode.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
直播预告
4 月 28 日 星期一 19:00 极限科技(INFINI Labs)团队带您全面解析 Coco AI,探索其核心功能、技术架构及实际应用场景,领略智能搜索与知识管理的革新。
CSDN 直播间地址 👇
https://live.csdn.net/room/csdnedu/q6BD0Kui
关于 Gitcode
GitCode 新一代由 AI 驱动的开源开发者平台,依托 CSDN 开发者社区,通过集成代码托管服务、代码仓库和可信赖的开源组件库,使开发者能够在云端进行代码托管和开发,平台提供了丰富的功能支持和完善的生态体系,帮助开发者轻松管理和分享代码,为开源项目提供强有力的支持。
作者:GitCode
原文:https://mp.weixin.qq.com/s/03VTrmVXzflO6QTcZaCLTA
在信息爆炸时代,企业正面临前所未有的挑战:
- 企业数据和信息分散,数据孤岛现象严重,员工往往浪费大量时间跨平台检索;
- 跨部门协作困难,团队因信息隔阂导致项目延期;
- 数据安全问题严峻,迫使企业对数据管理提出高要求;
- 传统搜索准确率不足,无法满足用户深层次需求;
这正是 Coco AI 诞生的契机——一款重新定义企业效率的智能中枢。
Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,深度融合大语言模型技术,实现从"人找信息"到"信息追人"的范式革命。目前已加入 GitCode 平台成为 G-Star 优秀毕业项目。通过连接 Google Workspace、Notion、语雀等 200+ 数据源,接入 DeepSeek 等大模型,构建企业级智能知识图谱,让数据真正流动起来,帮助企业高效管理和利用内外部数据资源。
多种功能 一次集合
全域智能搜索
- Coco AI 支持整合企业内部和外部的多种数据源,包括 Google Workspace、Dropbox、GitHub、本地文件系统等。
- 提供统一的搜索界面,用户无需切换多个平台即可快速检索所需信息。
AI 知识管家
- 内置基于生成式 AI 的聊天助手,能够理解企业内部的文档、对话记录和工作流程。
- 支持从互联网、内部知识库和指定数据源中提取信息,提供与组织相关的智能回答。
- 支持在搜索模式和聊天模式之间快速切换。
企业安全中枢
- 遵循企业级权限管理规范,确保数据访问的安全性。
- 支持私有化部署,满足企业对数据隐私的高要求。
- 允许开发者根据需求进行定制和扩展,支持企业自行部署,确保数据隐私和安全。
协作生态集成
- 用户可以直接与单个文件或数据源进行交互,例如对文档内容提问或生成摘要。
- 通过整合团队常用的工具和数据源,提升团队协作效率。
- 支持基于上下文的多轮对话,帮助团队成员快速获取所需信息。
- 在 1 分钟内轻松将 Coco AI 功能嵌入到您的网站中。
架构设计图
核心模块 “Coco Server” 提供搜索、聊天、附件管理、索引、嵌入、安全等功能,并通过 API 实现与外部系统的交互。同时,系统支持自定义 UI,为用户提供个性化的搜索和任务管理体验,并通过 AI 助手提供智能化的信息交互体验。
从 V0.3 到行业标准,Coco AI 持续进化,致力于推动知识管理和信息检索的变革,加速企业数字化转型。
立即访问
来 GitCode 了解 Coco AI,让您的企业获得:
- 每年节省百万级人力成本
- 打造永不遗忘的组织和大脑
- 激活数据资产的复合价值
开源可许:
MIT License
项目地址:
https://gitcode.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
直播预告
4 月 28 日 星期一 19:00 极限科技(INFINI Labs)团队带您全面解析 Coco AI,探索其核心功能、技术架构及实际应用场景,领略智能搜索与知识管理的革新。
CSDN 直播间地址 👇
https://live.csdn.net/room/csdnedu/q6BD0Kui
关于 Gitcode
GitCode 新一代由 AI 驱动的开源开发者平台,依托 CSDN 开发者社区,通过集成代码托管服务、代码仓库和可信赖的开源组件库,使开发者能够在云端进行代码托管和开发,平台提供了丰富的功能支持和完善的生态体系,帮助开发者轻松管理和分享代码,为开源项目提供强有力的支持。
收起阅读 »作者:GitCode
原文:https://mp.weixin.qq.com/s/03VTrmVXzflO6QTcZaCLTA
谈谈 ES 6.8 到 7.10 的功能变迁(2)- 字段类型篇
我们继续来了解一下从 ES 6.8 到 ES 7.10 新增的功能。本篇主要介绍新增的字段类型,会简要概述一下新增字段类型的使用场景和限制,提供简单的测试代码。
Flattened 扁平化对象字段
功能说明
解决场景
该功能主要用于处理具有大量不确定键的 JSON 对象,避免字段映射爆炸问题,特别适用于不需要对对象内部字段进行单独分析和聚合的场景,以及当对象结构不固定,字段名称动态变化时。
使用注意点
- 整个对象被视为单个字段,无法对内部单个字段进行分析或聚合
- 只支持 keyword 类型的操作,如 term、prefix 查询等。因为它的每个解析出的字段都值为 keyword 字段
- 默认最大字段深度为 20,可以通过 depth_limit 来设置。
- 不支持数字范围查询,高亮显示
- 查询时,无法使用通配符引用字段键,比如 { "term": {"labels.time*": 1541457010}}
- split_queries_on_whitespace 为 true 时,这个字段的全文查询(match,query_string,simple_query_string)等于是用了空格分词器。
支持的查询方法
- term 查询:精确匹配某个字段的值
- terms/terms_set 查询:匹配多个值中的任意一个或者多个
- prefix 查询:前缀匹配
- exists 查询:检查字段是否存在
- match 查询:分词后的全文检索(但因为是 keyword,所以实际上是精确匹配)
- query_string 和 simple_query_string
Shape 字段
功能说明
该功能主要用于存储和查询任意几何图形数据,支持点、线、圆、矩形、多边形等几何形状,特别适用于地理空间分析和基于形状的搜索场景,以及相比于 geo_shape 专门用于地理空间数据(坐标系统固定为 WGS84 经纬度),shape 字段可以用于任意坐标系统的几何形状,比如虚拟世界或者保密空间。
使用要点
- 形状数据使用 GeoJSON 或Well-Known Text (WKT)格式表示
- 支持的空间关系操作包括:INTERSECTS(相交)、DISJOINT(不相交)、WITHIN(内部)和 CONTAINS(包含)
- 由于 shape 字段的复杂输入结构和索引表示,目前无法对 shape 字段进行排序,也无法直接检索其字段值(只能通过 _source 字段获取)
- orientation 参数用于定义多边形顶点读取的顺序:默认逆时针(counterclockwise),可选顺时针(clockwise)
Wildcard 字段
功能说明
解决的场景
用于优化通配符和正则表达式查询性能。特别适用于需要进行暴力模糊匹配的文本字段。 wildcard 字段在 keyword 字段和 ngrams 分词器之间找到了性能和存储成本的均衡。
原理说明
wildcard 字段采用了一种独特的索引策略,使用这种数据类型自动加速通配符和正则表达式搜索:
- n-gram 索引:存储字符串中所有 3 个字符的序列。可以理解为 ngram 分词器取长度为 3 的子串.
- 二进制 doc value:存储完整的原始文档值
这种方式与传统的 keyword 字段(完全不分词)和 text 字段(基于分词器分词)有很大不同。在查询时,系统首先使用这些 ngrams 构建的索引进行初步筛选,快速定位可能匹配的文档。这个过程类似于数据库中的索引过滤,可以大大减少需要详细检查的文档数量。然后,系统会从二进制 doc value 中取出这些候选文档的完整字段值,进行精确的模式匹配,确保最终结果的准确性。
这种策略在性能和存储空间上取得了很好的平衡:
- 相比 keyword 字段,在精确匹配查询时性能稍差
- 相比 ngrams 分词,它避免了过度的 token 生成,既节省存储空间,又保持了不错的查询性能
- 特别适合对日志数据进行类似 grep 的模式匹配查询,如通配符查询和正则表达式查询
使用注意点
- 比 keyword 类型更适合做通配符搜索,但会占用更多磁盘空间
- 建议仅在确实需要频繁进行通配符查询的字段上使用
- 与 keyword 字段一样是非分词(untokenized)的,所以不支持依赖词项位置的查询(如短语查询)
更多原理说明可以参照这里
Version 字段类型
功能说明
该功能主要用于存储和比较软件版本号,提供版本号的自然排序和比较功能,支持标准的版本号格式(如 1.0.0, 2.1.3-alpha 等)。
使用说明
- 版本号必须符合标准格式:主版本号、次版本号、修订号
- 支持带有预发布标识符的版本号(如 alpha, beta, rc 等)
- 可以进行版本号的大小比较和范围查询,比如可以在 1.0.0 和 2.0.0 之间查找所有版本
- 底层存储的是 keyword 类型,虽然可以正则匹配或者模糊查询,但是在大数据量下注意性能问题。
Histogram 直方图字段
功能说明
解决的场景
Histogram 字段专门用于存储预先计算好的直方图数据,这种数据结构在需要频繁进行统计分析的场景下特别有用。通过预先聚合数据并以直方图形式存储,可以显著减少查询时的实时计算开销,提高查询性能。对大规模数据集的统计分析很有利,比如系统监控指标、用户行为分析等需要快速获取数据分布情况的场景。
直方图的数据格式
直方图字段需要包含两个必需的参数来表示直方图数据:
values:数值数组,表示每个聚合分桶的取值点,即区间的起点。数组中的值必须是严格递增双精度浮点数counts:整数数组,表示落在当前区间内的元素数量。数组中的值必须是非负整数。具体来说,对于位置 i,counts[i] 表示数值大于等于 values[i] 且小于 values[i+1] 的元素个数(最后一个区间则包含等于 values[last] 的元素)
这两个数组必须具有相同的长度。 例如,一个表示年龄分布的直方图数据可能如下:
{
"age_histogram": {
"values": [20.0, 30.0, 40.0, 50.0], // 年龄区间的起点:[20-30)、[30-40)、[40-50)、[50 及以上]
"counts": [100, 150, 75, 25] // 表示:20-29 岁有 100 人,30-39 岁有 150 人,40-49 岁有 75 人,50 岁及以上有 25 人
}
}存储说明
直方图字段主要用于聚合分析。为了优化聚合操作的性能,数据以二进制 doc values 形式存储,而不是创建索引。每个直方图字段的存储大小最多为 13 * numValues 字节,其中 numValues 是数组的长度。
使用注意点
- value 数组必须按升序排列
- count 数组的长度必须与 value 数组相同
- 由于数据被索引,直方图字段仅支持以下操作:
- 聚合操作:min(最小值)、max(最大值)、sum(求和)、value_count(计数)、avg(平均值)、percentiles(百分位数)、percentile_ranks(百分位等级)、boxplot(箱线图)、histogram(直方图)
- 查询操作:仅支持 exists(存在性)查询
Search-as-you-type 字段
功能说明
解决的场景
该功能主要用于实现自动补全的即时搜索体验,比如可以在当用户输入搜索关键词的时候,还没输完就可以提示用户数据库里最相关的内容。 它是通过支持前缀匹配和部分词语匹配的方式,使用户在输入过程中就能获得搜索结果。
字段结构说明
search_as_you_type 字段会自动创建以下子字段:
{field_name}: 基础字段,用于完整词语匹配,使用字段设置的分词器。{field_name}._2gram: 用大小为 2 的 shingle token filter 分词器对 ny_field 进行分词{field_name}._3gram: 用大小为 3 的 shingle token filter 分词器对 ny_field 进行分词{field_name}._index_prefix: 用 edge ngram token filter 包装 my_field._3gram 的分词器
使用注意
- 可以通过设置 max_shingle_size 参数(默认为 3)来控制生成的子字段数量。max_shingle_size 参数越大,子字段越多,默认 3 个字段能覆盖大部分的场景。
- search-as-you-type 字段索引空间占用较大,因为需要存储多个分词器的结果。
前缀查询(prefix)优化机制
search_as_you_type 字段在处理前缀查询时有特殊的优化。当对根字段或其子字段进行前缀查询时,查询会被重写为针对 ._index_prefix 子字段的 term 查询,这比传统的文本字段前缀查询更高效 ._index_prefix 子字段的分析器会对分词结果进行特殊处理:
- 不仅索引常规的 n-gram 分词结果
- 还会索引字段值词条的前缀,即使这些词条不会出现在 n-gram 子字段中
例如,对于文本 "quick brown fox",在 max_shingle_size 为 3 的情况下:不仅会索引会索引"quick" "brown" "fox",还会索引这些此项的前缀,这确保了字段中所有词条都能支持自动完成功能,即使这些词条组合并不存在于 ._3gram 子字段中
小结
这里我们只是简要的介绍了一下新增字段类型的设计背景和原理,并没有深入展开挖掘新增字段的性能场景或者奇思妙用,比如 wildcard 与 ngram 颗粒度性能对比,直方图数据和 pipeline 进行日志分析的组合等等。大家可以根据实际的需求场景进行深度挖掘。
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(1)- 性能优化篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
我们继续来了解一下从 ES 6.8 到 ES 7.10 新增的功能。本篇主要介绍新增的字段类型,会简要概述一下新增字段类型的使用场景和限制,提供简单的测试代码。
Flattened 扁平化对象字段
功能说明
解决场景
该功能主要用于处理具有大量不确定键的 JSON 对象,避免字段映射爆炸问题,特别适用于不需要对对象内部字段进行单独分析和聚合的场景,以及当对象结构不固定,字段名称动态变化时。
使用注意点
- 整个对象被视为单个字段,无法对内部单个字段进行分析或聚合
- 只支持 keyword 类型的操作,如 term、prefix 查询等。因为它的每个解析出的字段都值为 keyword 字段
- 默认最大字段深度为 20,可以通过 depth_limit 来设置。
- 不支持数字范围查询,高亮显示
- 查询时,无法使用通配符引用字段键,比如 { "term": {"labels.time*": 1541457010}}
- split_queries_on_whitespace 为 true 时,这个字段的全文查询(match,query_string,simple_query_string)等于是用了空格分词器。
支持的查询方法
- term 查询:精确匹配某个字段的值
- terms/terms_set 查询:匹配多个值中的任意一个或者多个
- prefix 查询:前缀匹配
- exists 查询:检查字段是否存在
- match 查询:分词后的全文检索(但因为是 keyword,所以实际上是精确匹配)
- query_string 和 simple_query_string
Shape 字段
功能说明
该功能主要用于存储和查询任意几何图形数据,支持点、线、圆、矩形、多边形等几何形状,特别适用于地理空间分析和基于形状的搜索场景,以及相比于 geo_shape 专门用于地理空间数据(坐标系统固定为 WGS84 经纬度),shape 字段可以用于任意坐标系统的几何形状,比如虚拟世界或者保密空间。
使用要点
- 形状数据使用 GeoJSON 或Well-Known Text (WKT)格式表示
- 支持的空间关系操作包括:INTERSECTS(相交)、DISJOINT(不相交)、WITHIN(内部)和 CONTAINS(包含)
- 由于 shape 字段的复杂输入结构和索引表示,目前无法对 shape 字段进行排序,也无法直接检索其字段值(只能通过 _source 字段获取)
- orientation 参数用于定义多边形顶点读取的顺序:默认逆时针(counterclockwise),可选顺时针(clockwise)
Wildcard 字段
功能说明
解决的场景
用于优化通配符和正则表达式查询性能。特别适用于需要进行暴力模糊匹配的文本字段。 wildcard 字段在 keyword 字段和 ngrams 分词器之间找到了性能和存储成本的均衡。
原理说明
wildcard 字段采用了一种独特的索引策略,使用这种数据类型自动加速通配符和正则表达式搜索:
- n-gram 索引:存储字符串中所有 3 个字符的序列。可以理解为 ngram 分词器取长度为 3 的子串.
- 二进制 doc value:存储完整的原始文档值
这种方式与传统的 keyword 字段(完全不分词)和 text 字段(基于分词器分词)有很大不同。在查询时,系统首先使用这些 ngrams 构建的索引进行初步筛选,快速定位可能匹配的文档。这个过程类似于数据库中的索引过滤,可以大大减少需要详细检查的文档数量。然后,系统会从二进制 doc value 中取出这些候选文档的完整字段值,进行精确的模式匹配,确保最终结果的准确性。
这种策略在性能和存储空间上取得了很好的平衡:
- 相比 keyword 字段,在精确匹配查询时性能稍差
- 相比 ngrams 分词,它避免了过度的 token 生成,既节省存储空间,又保持了不错的查询性能
- 特别适合对日志数据进行类似 grep 的模式匹配查询,如通配符查询和正则表达式查询
使用注意点
- 比 keyword 类型更适合做通配符搜索,但会占用更多磁盘空间
- 建议仅在确实需要频繁进行通配符查询的字段上使用
- 与 keyword 字段一样是非分词(untokenized)的,所以不支持依赖词项位置的查询(如短语查询)
更多原理说明可以参照这里
Version 字段类型
功能说明
该功能主要用于存储和比较软件版本号,提供版本号的自然排序和比较功能,支持标准的版本号格式(如 1.0.0, 2.1.3-alpha 等)。
使用说明
- 版本号必须符合标准格式:主版本号、次版本号、修订号
- 支持带有预发布标识符的版本号(如 alpha, beta, rc 等)
- 可以进行版本号的大小比较和范围查询,比如可以在 1.0.0 和 2.0.0 之间查找所有版本
- 底层存储的是 keyword 类型,虽然可以正则匹配或者模糊查询,但是在大数据量下注意性能问题。
Histogram 直方图字段
功能说明
解决的场景
Histogram 字段专门用于存储预先计算好的直方图数据,这种数据结构在需要频繁进行统计分析的场景下特别有用。通过预先聚合数据并以直方图形式存储,可以显著减少查询时的实时计算开销,提高查询性能。对大规模数据集的统计分析很有利,比如系统监控指标、用户行为分析等需要快速获取数据分布情况的场景。
直方图的数据格式
直方图字段需要包含两个必需的参数来表示直方图数据:
values:数值数组,表示每个聚合分桶的取值点,即区间的起点。数组中的值必须是严格递增双精度浮点数counts:整数数组,表示落在当前区间内的元素数量。数组中的值必须是非负整数。具体来说,对于位置 i,counts[i] 表示数值大于等于 values[i] 且小于 values[i+1] 的元素个数(最后一个区间则包含等于 values[last] 的元素)
这两个数组必须具有相同的长度。 例如,一个表示年龄分布的直方图数据可能如下:
{
"age_histogram": {
"values": [20.0, 30.0, 40.0, 50.0], // 年龄区间的起点:[20-30)、[30-40)、[40-50)、[50 及以上]
"counts": [100, 150, 75, 25] // 表示:20-29 岁有 100 人,30-39 岁有 150 人,40-49 岁有 75 人,50 岁及以上有 25 人
}
}存储说明
直方图字段主要用于聚合分析。为了优化聚合操作的性能,数据以二进制 doc values 形式存储,而不是创建索引。每个直方图字段的存储大小最多为 13 * numValues 字节,其中 numValues 是数组的长度。
使用注意点
- value 数组必须按升序排列
- count 数组的长度必须与 value 数组相同
- 由于数据被索引,直方图字段仅支持以下操作:
- 聚合操作:min(最小值)、max(最大值)、sum(求和)、value_count(计数)、avg(平均值)、percentiles(百分位数)、percentile_ranks(百分位等级)、boxplot(箱线图)、histogram(直方图)
- 查询操作:仅支持 exists(存在性)查询
Search-as-you-type 字段
功能说明
解决的场景
该功能主要用于实现自动补全的即时搜索体验,比如可以在当用户输入搜索关键词的时候,还没输完就可以提示用户数据库里最相关的内容。 它是通过支持前缀匹配和部分词语匹配的方式,使用户在输入过程中就能获得搜索结果。
字段结构说明
search_as_you_type 字段会自动创建以下子字段:
{field_name}: 基础字段,用于完整词语匹配,使用字段设置的分词器。{field_name}._2gram: 用大小为 2 的 shingle token filter 分词器对 ny_field 进行分词{field_name}._3gram: 用大小为 3 的 shingle token filter 分词器对 ny_field 进行分词{field_name}._index_prefix: 用 edge ngram token filter 包装 my_field._3gram 的分词器
使用注意
- 可以通过设置 max_shingle_size 参数(默认为 3)来控制生成的子字段数量。max_shingle_size 参数越大,子字段越多,默认 3 个字段能覆盖大部分的场景。
- search-as-you-type 字段索引空间占用较大,因为需要存储多个分词器的结果。
前缀查询(prefix)优化机制
search_as_you_type 字段在处理前缀查询时有特殊的优化。当对根字段或其子字段进行前缀查询时,查询会被重写为针对 ._index_prefix 子字段的 term 查询,这比传统的文本字段前缀查询更高效 ._index_prefix 子字段的分析器会对分词结果进行特殊处理:
- 不仅索引常规的 n-gram 分词结果
- 还会索引字段值词条的前缀,即使这些词条不会出现在 n-gram 子字段中
例如,对于文本 "quick brown fox",在 max_shingle_size 为 3 的情况下:不仅会索引会索引"quick" "brown" "fox",还会索引这些此项的前缀,这确保了字段中所有词条都能支持自动完成功能,即使这些词条组合并不存在于 ._3gram 子字段中
小结
这里我们只是简要的介绍了一下新增字段类型的设计背景和原理,并没有深入展开挖掘新增字段的性能场景或者奇思妙用,比如 wildcard 与 ngram 颗粒度性能对比,直方图数据和 pipeline 进行日志分析的组合等等。大家可以根据实际的需求场景进行深度挖掘。
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(1)- 性能优化篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
【搜索客社区日报】第2028期 (2025-04-24)
https://mp.weixin.qq.com/s/2tYO1z5pt-nU6duANzDlbg
2.分布式数据库是伪需求
https://mp.weixin.qq.com/s/FNhTCZk-SBVQkYhQ3zi_-g
3.使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
https://mp.weixin.qq.com/s/NByw3E2Tl53YOslBUZKAkw
4.MCP协议重大升级,Spring AI Alibaba联合Higress发布业界首个Streamable HTTP实现方案
https://mp.weixin.qq.com/s/wZ47ZETmjO0RwsJIbCFdJw
5.MCP云托管最优解,揭秘国内最大MCP中文社区背后的运行时
https://mp.weixin.qq.com/s/TzLRQWHQd5svAiwp2zlIGA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/2tYO1z5pt-nU6duANzDlbg
2.分布式数据库是伪需求
https://mp.weixin.qq.com/s/FNhTCZk-SBVQkYhQ3zi_-g
3.使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
https://mp.weixin.qq.com/s/NByw3E2Tl53YOslBUZKAkw
4.MCP协议重大升级,Spring AI Alibaba联合Higress发布业界首个Streamable HTTP实现方案
https://mp.weixin.qq.com/s/wZ47ZETmjO0RwsJIbCFdJw
5.MCP云托管最优解,揭秘国内最大MCP中文社区背后的运行时
https://mp.weixin.qq.com/s/TzLRQWHQd5svAiwp2zlIGA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2027期 (2025-04-23)
https://blog.csdn.net/UbuntuTo ... 18516
2.又来一个挑战 ElasticSearch 的,初识 SigLens
https://zhuanlan.zhihu.com/p/1897571712566027886
3.把 CSV 文件摄入到 Elasticsearch 中 - CSVES
https://zhuanlan.zhihu.com/p/1895418234372613962
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 18516
2.又来一个挑战 ElasticSearch 的,初识 SigLens
https://zhuanlan.zhihu.com/p/1897571712566027886
3.把 CSV 文件摄入到 Elasticsearch 中 - CSVES
https://zhuanlan.zhihu.com/p/1895418234372613962
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2026期 (2025-04-22)
https://medium.com/%40joseph5/ ... e0d63
2. 让大模型陪你一起学习吗?(需要梯子)
https://medium.com/poatek/unlo ... 432c5
3. ES 监控工具集,总有一款适合你(需要梯子)
https://medium.com/%40tumersev ... 4ad57
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40joseph5/ ... e0d63
2. 让大模型陪你一起学习吗?(需要梯子)
https://medium.com/poatek/unlo ... 432c5
3. ES 监控工具集,总有一款适合你(需要梯子)
https://medium.com/%40tumersev ... 4ad57
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
搜索服务统一治理(跨引擎多个集群监控管理、流量管控、服务编排)【Workshop 第一期 - 北京站】
快来与 INFINI Labs 的技术专家面对面,第一时间了解 INFINI Labs 的发布最新产品和功能特性,通过动手实战,快速掌握最前沿的搜索技术,并用于实际项目中。活动免费,欢迎报名参加。
活动时间:2025 年 5 月 15 日 13:30~17:30
活动地点:北京市海淀区 Wework 辉煌时代大厦 3 楼 3E 会议室
活动海报

活动内容
1、搜索服务统一治理
环境搭建:INFINI Console、Easysearch、Agent、Email
- 多集群监控管理:生命周期保留期限调整、删除老的索引、rollover
- 多集群监控告警:告警监控数据、告警业务数据
- 多集群日志查看:实时日志查看
2、流量管控
环境搭建:INFINI Gateway
- Easysearch 节点限速
- Easysearch 索引限速
- Easysearch 分片限速
- Gateway 限速
3、服务编排
环境搭建:安装K8S、INFINI Cloud
- INFINI Cloud 安装
- INFINI Cloud 发布 Easysearch 集群
- INFINI Cloud 增加 Easysearch 节点
- INFINI Cloud 扩容 Easysearch 资源
参会提示
- 请务必自备电脑(Windows 系统环境请提前安装好 Linux 虚拟机)
- 请提前在 INFINI Labs 官网下载对应平台最新安装包(INFINI Easysearch、INFINI Gateway、INFINI Console)
- 下载地址:https://www.infinilabs.com/download
- 如有任何疑问可添加 INFINI Labs 小助手(微信号: INFINI-Labs)进行联系
快来与 INFINI Labs 的技术专家面对面,第一时间了解 INFINI Labs 的发布最新产品和功能特性,通过动手实战,快速掌握最前沿的搜索技术,并用于实际项目中。活动免费,欢迎报名参加。
活动时间:2025 年 5 月 15 日 13:30~17:30
活动地点:北京市海淀区 Wework 辉煌时代大厦 3 楼 3E 会议室
活动海报
活动内容
1、搜索服务统一治理
环境搭建:INFINI Console、Easysearch、Agent、Email
- 多集群监控管理:生命周期保留期限调整、删除老的索引、rollover
- 多集群监控告警:告警监控数据、告警业务数据
- 多集群日志查看:实时日志查看
2、流量管控
环境搭建:INFINI Gateway
- Easysearch 节点限速
- Easysearch 索引限速
- Easysearch 分片限速
- Gateway 限速
3、服务编排
环境搭建:安装K8S、INFINI Cloud
- INFINI Cloud 安装
- INFINI Cloud 发布 Easysearch 集群
- INFINI Cloud 增加 Easysearch 节点
- INFINI Cloud 扩容 Easysearch 资源
参会提示
- 请务必自备电脑(Windows 系统环境请提前安装好 Linux 虚拟机)
- 请提前在 INFINI Labs 官网下载对应平台最新安装包(INFINI Easysearch、INFINI Gateway、INFINI Console)
- 下载地址:https://www.infinilabs.com/download
- 如有任何疑问可添加 INFINI Labs 小助手(微信号: INFINI-Labs)进行联系
【搜索客社区日报】第2025期 (2025-04-21)
https://mp.weixin.qq.com/s/8I9CL8E4t1LgxB7ao06J4A
2、MCP 实践:基于 MCP 架构实现知识库答疑系统
https://mp.weixin.qq.com/s/ETmbEAE7lNligcM_A_GF8A
3、Easysearch 迁移数据之 Reindex From Remote
https://infinilabs.cn/blog/202 ... mote/
4、给AI装上“万能双手”的协议,小白也能玩转智能工具-一文搞懂MCP
https://blog.csdn.net/sjw89082 ... 99039
5、【视频上新】Coco AI 部署及使用详解
https://mp.weixin.qq.com/s/7CkceoXg8WYxqlFQK9_waw
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/8I9CL8E4t1LgxB7ao06J4A
2、MCP 实践:基于 MCP 架构实现知识库答疑系统
https://mp.weixin.qq.com/s/ETmbEAE7lNligcM_A_GF8A
3、Easysearch 迁移数据之 Reindex From Remote
https://infinilabs.cn/blog/202 ... mote/
4、给AI装上“万能双手”的协议,小白也能玩转智能工具-一文搞懂MCP
https://blog.csdn.net/sjw89082 ... 99039
5、【视频上新】Coco AI 部署及使用详解
https://mp.weixin.qq.com/s/7CkceoXg8WYxqlFQK9_waw
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2024期 (2025-04-17)
https://www.elastic.co/search- ... earch
2.使用 Agent、LLM 和 RAG 构建你的第二个大脑 AI 助手
https://github.com/decodingml/ ... ourse
3.我用 Cursor 和 DevBox 业余时间开发了一个 Web 防火墙
https://mp.weixin.qq.com/s/KwhulGZW9mSgA1sti61iZg
4.V0创始人:从设计图到代码,AI绝对能搞定。翻译类的代码任务,都应该交给AI去干
https://mp.weixin.qq.com/s/qQ9Y9pDvxB6xPkdaOGGzDg
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://www.elastic.co/search- ... earch
2.使用 Agent、LLM 和 RAG 构建你的第二个大脑 AI 助手
https://github.com/decodingml/ ... ourse
3.我用 Cursor 和 DevBox 业余时间开发了一个 Web 防火墙
https://mp.weixin.qq.com/s/KwhulGZW9mSgA1sti61iZg
4.V0创始人:从设计图到代码,AI绝对能搞定。翻译类的代码任务,都应该交给AI去干
https://mp.weixin.qq.com/s/qQ9Y9pDvxB6xPkdaOGGzDg
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2023期 (2025-04-16)
https://zhuanlan.zhihu.com/p/668706342
2.Elasticsearch BBQ 与 OpenSearch FAISS:向量搜索性能对比
https://blog.csdn.net/UbuntuTo ... 64172
3.Elasticsearch 与 OpenSearch:解开向量搜索性能差距
https://zhuanlan.zhihu.com/p/719251376
编辑:kin122
更多资讯:http://news.searchkit.cn
https://zhuanlan.zhihu.com/p/668706342
2.Elasticsearch BBQ 与 OpenSearch FAISS:向量搜索性能对比
https://blog.csdn.net/UbuntuTo ... 64172
3.Elasticsearch 与 OpenSearch:解开向量搜索性能差距
https://zhuanlan.zhihu.com/p/719251376
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch Rollup 相比 OpenSearch Rollup 的优势分析
背景
在处理时序数据时,Rollup 功能通过数据聚合显著降低存储成本,并提升查询性能。Easysearch 与 OpenSearch 均提供了 Rollup 能力,但在多个关键维度上,Easysearch Rollup 展现出更优的表现。本文将从查询体验、索引管理、聚合能力、性能优化和任务管理五个方面,分析 Easysearch Rollup 相较于 OpenSearch Rollup 的优势。
Easysearch vs OpenSearch
1. 查询体验:标准接口与无缝集成
Easysearch Rollup 支持通过标准的 _search API 查询原始索引,系统自动融合 Rollup 数据,用户无需变更现有代码或使用专用查询端点。相比之下,OpenSearch Rollup 虽然使用标准查询语法,但需要用户显式指定 Rollup 索引,无法自动结合原始数据,在需要同时访问原始与聚合数据的场景下显得更为繁琐。
- 差异:Easysearch 支持自动融合原始与 Rollup 数据,OpenSearch 需手动指定索引。
- 影响:Easysearch 显著降低了查询逻辑的复杂性和开发维护成本。
2. 索引管理:自动化与扩展能力
Easysearch Rollup 提供自动索引滚动功能,可通过 rollup.index_max_docs. 配置项为不同的目标 Rollup 索引设置文档数上限,触发新索引的动态创建,显著简化管理流程。此外,配置中支持使用变量(如 {{ctx.source_index}})动态生成目标索引名,便于多个任务复用同一模板,批量扩展 Rollup 任务时更加高效和灵活。
相比之下,OpenSearch Rollup 依赖 Index State Management(ISM)策略或手动操作进行索引切换,配置复杂、监控成本高,且在大规模任务部署时缺乏灵活的模板化机制。
- 差异:Easysearch 提供内建的自动滚动机制,OpenSearch 依赖外部策略或手动配置。
- 影响:Easysearch 更易于统一管理和大规模扩展,运维成本更低。
3. 聚合能力:更广泛的聚合类型支持
Easysearch Rollup 支持丰富的聚合类型,包括数值字段的 avg、sum、max、min、percentiles,关键词字段的 terms,日期字段的 date_histogram 与 date_range,还支持 filter 聚合与 special_metrics(可自定义聚合字段和方式)等高级功能。OpenSearch Rollup 支持的聚合类型相对有限,不支持 date_range、filter 等复杂聚合表达式。
- 差异:Easysearch 提供更全面的聚合能力,OpenSearch 仅支持基础聚合。
- 影响:Easysearch 更适合构建复杂的时序分析任务,满足更广泛的业务需求。
4. 性能优化:精细化配置与资源控制
Easysearch Rollup 提供多种性能优化选项,例如 ROLLUP_SEARCH_MAX_COUNT 控制并发查询数,rollup.hours_before 限制回溯时间范围,write_optimization 和 field_abbr 用于优化写入效率与运行时的内存占用。而 OpenSearch Rollup 缺乏类似的专用配置项,主要依赖通用的集群参数,灵活性与精细度较低。
- 差异:Easysearch 提供针对 Rollup 场景的专属优化选项,OpenSearch 优化能力较通用。
- 影响:Easysearch 在资源使用效率、查询性能和成本控制方面更具优势。
5. 任务管理:批量控制与更高灵活性
Easysearch Rollup 支持使用通配符进行任务批量管理,且新建任务默认处于非激活状态,用户可按需启用。而 OpenSearch Rollup 中,任务默认立即启用,管理粒度较粗,仅支持单个任务的启停与修改,缺乏批量操作能力。
- 差异:Easysearch 支持批量任务管理与按需启用,OpenSearch 功能较为基础。
- 影响:Easysearch 在多任务环境下提供更高的管理效率和控制能力。
实战示例:节点统计 Rollup 配置
以下是一个 Easysearch Rollup 任务的配置示例:
{
"rollup": {
"source_index": ".infini_metrics",
"target_index": "rollup_node_stats_{{ctx.source_index}}",
"timestamp": "timestamp",
"continuous": true,
"page_size": 200,
"cron": "*/5 1-23 * * *",
"interval": "1m",
"identity": ["metadata.labels.cluster_id", "metadata.labels.node_id"],
"stats": [{ "max": {} }, { "min": {} }, { "value_count": {} }],
"special_metrics": [
{
"source_field": "payload.elasticsearch.node_stats.jvm.mem.heap_used_in_bytes",
"metrics": [{ "avg": {} }, { "max": {} }, { "min": {} }]
}
],
"write_optimization": true
}
}- 亮点:支持自动索引滚动、标准 API 查询、
special_metrics高级聚合与写入优化等特性。
总结
综合来看,Easysearch Rollup 在以下方面优于 OpenSearch Rollup:
- 查询接口的兼容性与无感知集成
- 自动化的索引管理与扩展能力
- 更丰富的聚合类型与表达能力
- 针对性更强的性能优化参数
- 灵活高效的任务批量管理机制
这些优势使 Easysearch Rollup 更加适用于复杂、多样化的时序数据处理场景,特别是在对性能、扩展性与运维效率有较高要求的系统中表现出色。如果你正在寻找一款功能全面、易于管理的 Rollup 解决方案,Easysearch 是一个值得重点考虑的选择。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Rollup-vs-OpenSearch-Rollup/
背景
在处理时序数据时,Rollup 功能通过数据聚合显著降低存储成本,并提升查询性能。Easysearch 与 OpenSearch 均提供了 Rollup 能力,但在多个关键维度上,Easysearch Rollup 展现出更优的表现。本文将从查询体验、索引管理、聚合能力、性能优化和任务管理五个方面,分析 Easysearch Rollup 相较于 OpenSearch Rollup 的优势。
Easysearch vs OpenSearch
1. 查询体验:标准接口与无缝集成
Easysearch Rollup 支持通过标准的 _search API 查询原始索引,系统自动融合 Rollup 数据,用户无需变更现有代码或使用专用查询端点。相比之下,OpenSearch Rollup 虽然使用标准查询语法,但需要用户显式指定 Rollup 索引,无法自动结合原始数据,在需要同时访问原始与聚合数据的场景下显得更为繁琐。
- 差异:Easysearch 支持自动融合原始与 Rollup 数据,OpenSearch 需手动指定索引。
- 影响:Easysearch 显著降低了查询逻辑的复杂性和开发维护成本。
2. 索引管理:自动化与扩展能力
Easysearch Rollup 提供自动索引滚动功能,可通过 rollup.index_max_docs. 配置项为不同的目标 Rollup 索引设置文档数上限,触发新索引的动态创建,显著简化管理流程。此外,配置中支持使用变量(如 {{ctx.source_index}})动态生成目标索引名,便于多个任务复用同一模板,批量扩展 Rollup 任务时更加高效和灵活。
相比之下,OpenSearch Rollup 依赖 Index State Management(ISM)策略或手动操作进行索引切换,配置复杂、监控成本高,且在大规模任务部署时缺乏灵活的模板化机制。
- 差异:Easysearch 提供内建的自动滚动机制,OpenSearch 依赖外部策略或手动配置。
- 影响:Easysearch 更易于统一管理和大规模扩展,运维成本更低。
3. 聚合能力:更广泛的聚合类型支持
Easysearch Rollup 支持丰富的聚合类型,包括数值字段的 avg、sum、max、min、percentiles,关键词字段的 terms,日期字段的 date_histogram 与 date_range,还支持 filter 聚合与 special_metrics(可自定义聚合字段和方式)等高级功能。OpenSearch Rollup 支持的聚合类型相对有限,不支持 date_range、filter 等复杂聚合表达式。
- 差异:Easysearch 提供更全面的聚合能力,OpenSearch 仅支持基础聚合。
- 影响:Easysearch 更适合构建复杂的时序分析任务,满足更广泛的业务需求。
4. 性能优化:精细化配置与资源控制
Easysearch Rollup 提供多种性能优化选项,例如 ROLLUP_SEARCH_MAX_COUNT 控制并发查询数,rollup.hours_before 限制回溯时间范围,write_optimization 和 field_abbr 用于优化写入效率与运行时的内存占用。而 OpenSearch Rollup 缺乏类似的专用配置项,主要依赖通用的集群参数,灵活性与精细度较低。
- 差异:Easysearch 提供针对 Rollup 场景的专属优化选项,OpenSearch 优化能力较通用。
- 影响:Easysearch 在资源使用效率、查询性能和成本控制方面更具优势。
5. 任务管理:批量控制与更高灵活性
Easysearch Rollup 支持使用通配符进行任务批量管理,且新建任务默认处于非激活状态,用户可按需启用。而 OpenSearch Rollup 中,任务默认立即启用,管理粒度较粗,仅支持单个任务的启停与修改,缺乏批量操作能力。
- 差异:Easysearch 支持批量任务管理与按需启用,OpenSearch 功能较为基础。
- 影响:Easysearch 在多任务环境下提供更高的管理效率和控制能力。
实战示例:节点统计 Rollup 配置
以下是一个 Easysearch Rollup 任务的配置示例:
{
"rollup": {
"source_index": ".infini_metrics",
"target_index": "rollup_node_stats_{{ctx.source_index}}",
"timestamp": "timestamp",
"continuous": true,
"page_size": 200,
"cron": "*/5 1-23 * * *",
"interval": "1m",
"identity": ["metadata.labels.cluster_id", "metadata.labels.node_id"],
"stats": [{ "max": {} }, { "min": {} }, { "value_count": {} }],
"special_metrics": [
{
"source_field": "payload.elasticsearch.node_stats.jvm.mem.heap_used_in_bytes",
"metrics": [{ "avg": {} }, { "max": {} }, { "min": {} }]
}
],
"write_optimization": true
}
}- 亮点:支持自动索引滚动、标准 API 查询、
special_metrics高级聚合与写入优化等特性。
总结
综合来看,Easysearch Rollup 在以下方面优于 OpenSearch Rollup:
- 查询接口的兼容性与无感知集成
- 自动化的索引管理与扩展能力
- 更丰富的聚合类型与表达能力
- 针对性更强的性能优化参数
- 灵活高效的任务批量管理机制
这些优势使 Easysearch Rollup 更加适用于复杂、多样化的时序数据处理场景,特别是在对性能、扩展性与运维效率有较高要求的系统中表现出色。如果你正在寻找一款功能全面、易于管理的 Rollup 解决方案,Easysearch 是一个值得重点考虑的选择。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
收起阅读 »作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Rollup-vs-OpenSearch-Rollup/
【搜索客社区日报】第2022期 (2025-04-15)
https://blog.devgenius.io/the- ... 7c791
2. ES索引重建的最佳实践(需要梯子)
https://medium.com/%40mrtkrkrt ... 2ef98
3. 用airflow做ES的索引轮换、snapshot(需要梯子)
https://medium.com/%40MadhavPr ... 240df
https://medium.com/%40MadhavPr ... 65b71
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://blog.devgenius.io/the- ... 7c791
2. ES索引重建的最佳实践(需要梯子)
https://medium.com/%40mrtkrkrt ... 2ef98
3. 用airflow做ES的索引轮换、snapshot(需要梯子)
https://medium.com/%40MadhavPr ... 240df
https://medium.com/%40MadhavPr ... 65b71
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
谈谈 ES 6.8 到 7.10 的功能变迁(1)- 性能优化篇
前言
ES 7.10 可能是现在比较常见的 ES 版本。但是对于一些相迭代比较慢的早期业务系统来说,ES 6.8 是一个名副其实的“钉子户”。
借着工作内升级调研的任务东风,我整理从 ES 6.8 到 ES 7.10 ELastic 重点列出的新增功能和优化内容。将分为 6 个篇幅给大家详细阐述。
本系列文章主要针对 Elasticsearch 传统的使用功能和基础的模块,像是集群任务的管理、搜索、聚合还有字段类型这样的功能。对于付费功能或者全新的模块,比如:CCR、机器学习和数据流,这里不去深入探讨。
内容的主要来源于 Elastic 各个版本的发布信息,这里主要比对 ES 6.8 版本到 7.10 版本的差异,并不一一枚举各个新的功能点出现的时间版本。
下面是第一篇:关于 ES 性能的优化
ES 7.10 的性能优化
集群协调算法升级
基于 Elastic 博客提供的资料,Elasticsearch 7.0 的核心改进在于集群协调层的彻底重构,取代了旧版 Zen Discovery 的局限性,引入更健壮、自动化的分布式共识机制。从理论上来说这次优化有着不少的进步,可以显著提升了高可用性与运维效率
主要的优化点有下面三点:
-
消除分裂脑(Split Brain)风险:通过自动化计算,确保集群状态更新的安全性。旧版
minimum_master_nodes的手动配置被移除,避免人为误操作。 -
提升集群稳定性与恢复速度:节点故障时,集群更快达成一致,减少服务中断窗口。
- 简化运维复杂度:可以动态扩缩容无需手动调整配置,系统自动管理选举配置。同时提供更清晰的日志和错误提示,加速故障诊断。
| 旧版配置 | ES 7.0 配置 | 作用 |
|---|---|---|
discovery.zen.ping.unicast.hosts |
discovery.seed_hosts |
定义初始发现的种子节点列表(IP 或主机名) |
discovery.zen.minimum_master_nodes |
已移除 | 由系统自动管理法定人数 |
而在优化的原则里,Elastic 更强调安全第一。比如,在半数以上主节点永久丢失的风险场景下,ES 7.0 之前的集群会静默等待恢复,允许通过启动新空节点强制恢复,这样可能会导致数据不一致或丢失。在 Elasticsearch 7.0 以及更高版本中,这种不安全活动受到了更多限制。集群宁愿保持不可用状态,也不会冒这种风险(除非使用 elasticsearch-node 恢复工具)。
这次优化显著降低了人为错误的风险:移除脆弱的手动配置,减少运维使用的理解成本。同时提升关键业务连续性:快速故障恢复与明确的容错机制,能适合更多场景需求。
当然也并不是尽善尽美的,也会存在大集群下投票节点过多导致竞争激烈而无法选主的问题,这种情况下,建议部署独立的主节点,并且可以考虑适当增大 cluster.election.duration 的配置。
Top K 对检索的加速
这里的 Top K 主要是指在普通检索时展示前列的数据 Top K。也就是说 Elasticsearch 7.0 对检索数据的查询性能做了明显的改善。那是做了所有查询场景的提升么?
ELastic 做了这么一个场景假设:如果用户通常只关注搜索结果的第一页,且并不关心具体匹配的文档总数,对于超出一定数量的数据搜索引擎可以展示“超过 10,000 条结果”并提供分页浏览来优化搜索效率。但是在实际过程中用户常在查询中使用高频词(如“the”或“a”),这迫使 Elasticsearch 为大量文档计算评分,明显占用了查询资源的使用,即使这些常见词对相关性排序贡献甚微。
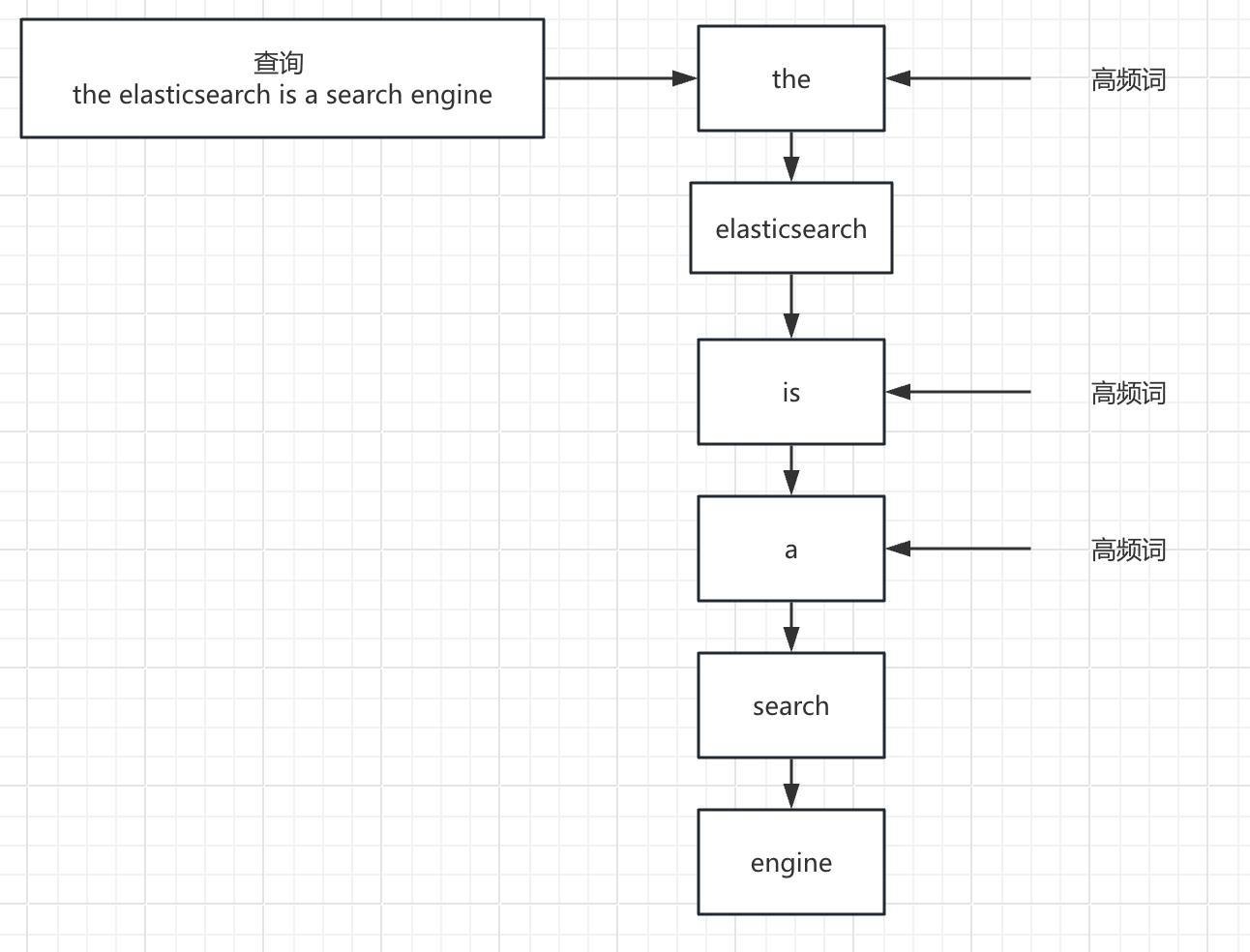
而现在,Elasticsearch 现在可以跳过那些在早期阶段就被判定为不会进入结果集顶部的低排名记录的评分计算,从而显著提升查询速度。这里主要涉及了 block-max WAND 算法的实现。这是一个复杂且漫长的优化过程,有兴趣的同学可以阅读一下这段Magic WAND: Faster Retrieval of Top Hits in Elasticsearch。
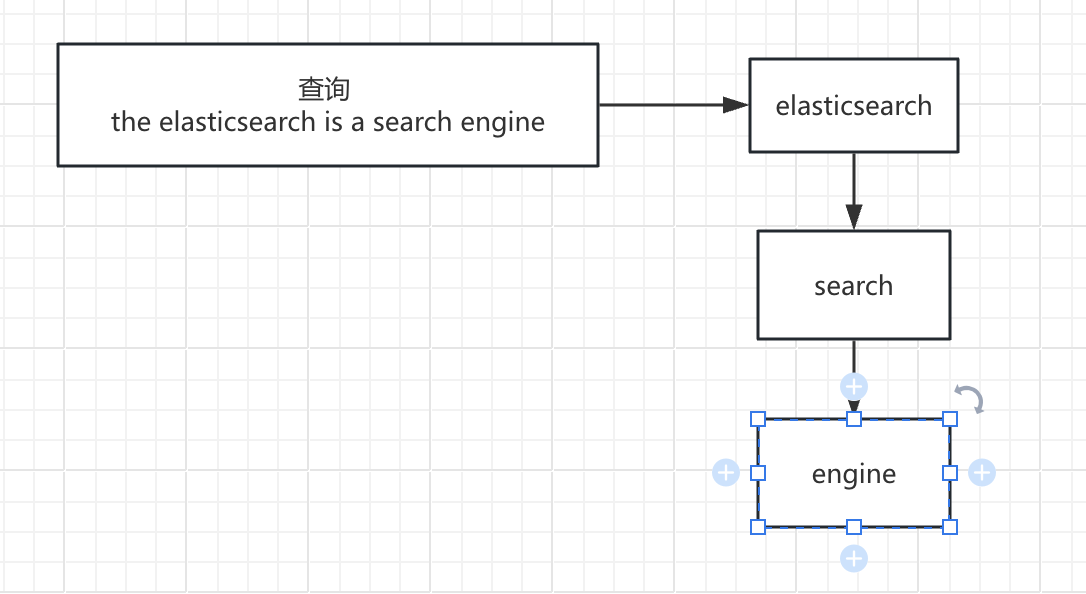
从 Elastic 的测试结果来看,新算法的优化让 term 查询加速了 3-7 倍。当然从场景背景可以看出,这个优化主要在大数据量下有明显效果(小数据量也不会有太多的日常高频词)。
默认开启 soft-delete 减少 translog
从 Elasticsearch 7.4 开始,副本的数据恢复,不再完全依赖 translog 了,而是通过索引的 soft-delete 特性(Elasticsearch 7.0 起所有新索引默认启用软删除 soft-deletes)。这样就可以缩小 translog 的使用场景,从而 translog 的保留大小也可以减少了。
那原来使用 translog 是什么样的呢?
translog 是 ES 用于保证数据安全性的重要工具。同时副分片进行恢复时,它也起着重要作用,只要副分片待获取的差异数据是在 translog 所保留的数据范围内,就可以只从 trasnlog 复制差异的部分数据,而不用拖取整个分片。在之前的版本中,Elasticsearch 默认会保留 512M 或 12 小时的 translog 用于副本恢复。
那现在使用的 soft-delete 是什么呢?
soft-deletes 是 Lucene 中实现的特性。这个软删除有时候会和 lucene 本身的标记删除概念发生混淆。为了方便理解,我们在这里归纳一下,lucene 实现删除的方式是一种标记删除的方式,而这种标记删除可以分为硬删除和软删除。软删除和硬删除有一个明显的区分点是:硬删除,被删除的文档对应的文档号用索引文件 .liv 来描述。软删除 soft-delete,被标记为删除的文档不使用索引文件.liv 来描述,而是通过索引文件 .dvd .dvm 来描述。
这里再扩展一下,.liv 文件主要实现 fixedbitset 数据结构。而 .dvd .dvm 则组合实现了 docvalue 这种正排数据结构。
正排索引的数据结构助力了 translog 的‘减负’,副本可以相对简便的通过软删除中的数据标记来实现数据恢复的处理。
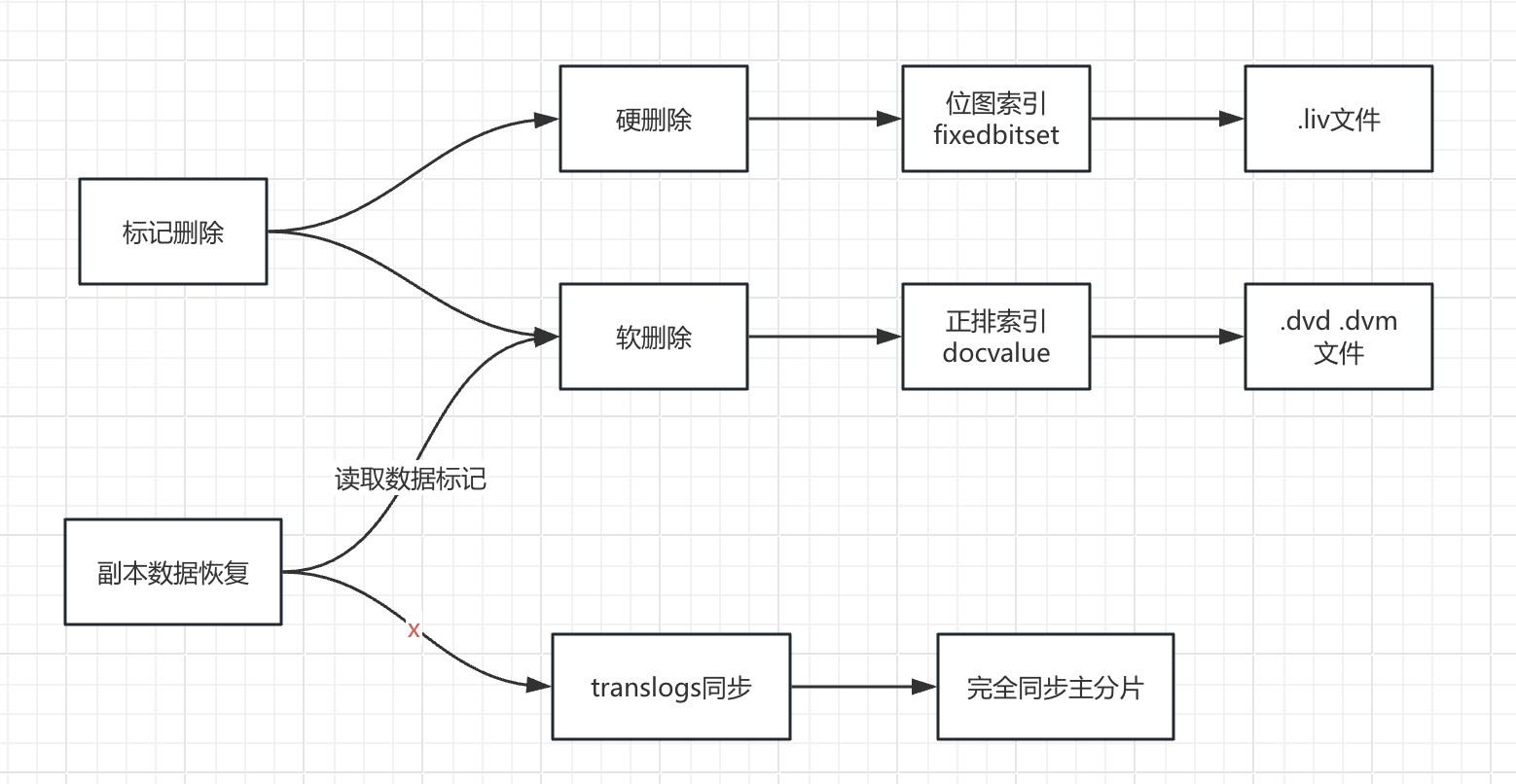
相比较简洁高效的位图索引,docvalue 虽然实现了更多的功能,满足更多的场景,也会带来更多的问题。最明显的就是对于 update 操作,会导致 refresh 变得慢,有些压力场景下 refresh 会达到 10s 以上。
数值/日期排序查询加速
Elasticsearch 7.6 版本提升了按日期或数值(即任何存储为有符号 64 位整数(long 类型)的字段)进行排序的查询性能。
这背后的优化原理和之前 top K 使用的 Block-Max WAND 算法有点相似,都是利用算法跳过非竞争性文档来实现加速。
实际效果可能因环境而异,受多种参数影响。在 Elastic 进行的测试场景下,可以达到 35 倍的速度优化。
FST 内存使用迁移到堆外
Elastic 7.3 版本实现了这个优化,是藏在 release note 里的彩蛋。
Also mmap terms index (.tip) files for hybridfs #43150 (issue: #42838)
看似不经意的一行,但是带来效果却不小。FST 从堆内转移到堆外后,JVM 的空间可以空余出很客观的一部分。

一直以来,ES 堆中常驻内存中占据比重最大是 FST,即 tip(terms index) 文件占据的空间,1TB 索引大约占用 2GB 或者更多的内存,因此为了节点稳定运行,业界通常认为一个节点 open 的索引不超过 5TB。现在,从 ES 7.3 版本开始,将 tip 文件修改为通过 mmap 的方式加载,这使 FST 占据的内存从堆内转移到了堆外由操作系统的 pagecache 管理。
存储字段压缩优化
Elasticsearch 7.10 基于 Apache Lucene 8.7 引入了对存储字段(stored fields)的更高压缩率优化。不管是对于基于 DEFLATE 的 index.codec: best_compression 还是基于 LZ4 的index.codec: default都有不错的表现,在 Elastic 的测试场景下,最大可达到 10%的存储空间减少。
对于数据压缩 lucene 这次主要做了两个优化。
-
Elastic 研究发现在存储数据的时候,底层的 block 越大,压缩效果越好,因为中间被压缩的重复数据可能越多。但是大块的 block 也可能因为解码重复数据降低查询速度。
-
block 间通过共享字典来维持检索效率和数据压缩之间的平衡。
2.1. 首先为压缩算法提供一个数据字典,它也可以用于字符串重复数据删除。如果在要压缩的数据流和字典之间有许多重复的字符串,那么最终可以得到更好的压缩比。在解压缩时也通过字典来快速补足。
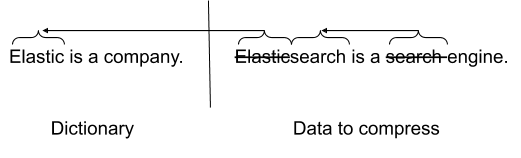
2.2. 同时,ES 使用更大的数据块,这些数据块本身被分成一个字典和 10 个子块,这些子块使用这个字典进行压缩。
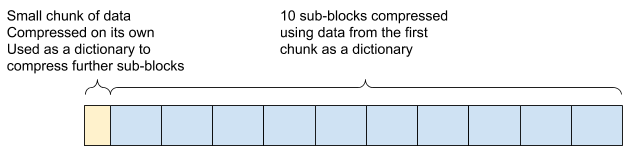
而对于实际业务场景中,日志和监控数据的重复率往往会很好,因此在这两个场景中的压缩效果也是最明显的。
小结
当然,除了这几项外,ES 在各个版本中也做了不少优化,比如:调整 search.max_buckets 增加到 65534;Date histogram 聚合性能优化等等。有兴趣的同学可以参照各个版本的 release highlight
参考资料:
- Save space and money with improved storage efficiency in Elasticsearch 7.10
- Elasticsearch 7.3 的 offheap 原理
- Elasticsearch 7.4 的 soft-deletes 是个什么鬼
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(2)- 字段类型篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/feature-evolution-from-elasticsearch-6.8-to-7.10-part-1/
前言
ES 7.10 可能是现在比较常见的 ES 版本。但是对于一些相迭代比较慢的早期业务系统来说,ES 6.8 是一个名副其实的“钉子户”。
借着工作内升级调研的任务东风,我整理从 ES 6.8 到 ES 7.10 ELastic 重点列出的新增功能和优化内容。将分为 6 个篇幅给大家详细阐述。
本系列文章主要针对 Elasticsearch 传统的使用功能和基础的模块,像是集群任务的管理、搜索、聚合还有字段类型这样的功能。对于付费功能或者全新的模块,比如:CCR、机器学习和数据流,这里不去深入探讨。
内容的主要来源于 Elastic 各个版本的发布信息,这里主要比对 ES 6.8 版本到 7.10 版本的差异,并不一一枚举各个新的功能点出现的时间版本。
下面是第一篇:关于 ES 性能的优化
ES 7.10 的性能优化
集群协调算法升级
基于 Elastic 博客提供的资料,Elasticsearch 7.0 的核心改进在于集群协调层的彻底重构,取代了旧版 Zen Discovery 的局限性,引入更健壮、自动化的分布式共识机制。从理论上来说这次优化有着不少的进步,可以显著提升了高可用性与运维效率
主要的优化点有下面三点:
-
消除分裂脑(Split Brain)风险:通过自动化计算,确保集群状态更新的安全性。旧版
minimum_master_nodes的手动配置被移除,避免人为误操作。 -
提升集群稳定性与恢复速度:节点故障时,集群更快达成一致,减少服务中断窗口。
- 简化运维复杂度:可以动态扩缩容无需手动调整配置,系统自动管理选举配置。同时提供更清晰的日志和错误提示,加速故障诊断。
| 旧版配置 | ES 7.0 配置 | 作用 |
|---|---|---|
discovery.zen.ping.unicast.hosts |
discovery.seed_hosts |
定义初始发现的种子节点列表(IP 或主机名) |
discovery.zen.minimum_master_nodes |
已移除 | 由系统自动管理法定人数 |
而在优化的原则里,Elastic 更强调安全第一。比如,在半数以上主节点永久丢失的风险场景下,ES 7.0 之前的集群会静默等待恢复,允许通过启动新空节点强制恢复,这样可能会导致数据不一致或丢失。在 Elasticsearch 7.0 以及更高版本中,这种不安全活动受到了更多限制。集群宁愿保持不可用状态,也不会冒这种风险(除非使用 elasticsearch-node 恢复工具)。
这次优化显著降低了人为错误的风险:移除脆弱的手动配置,减少运维使用的理解成本。同时提升关键业务连续性:快速故障恢复与明确的容错机制,能适合更多场景需求。
当然也并不是尽善尽美的,也会存在大集群下投票节点过多导致竞争激烈而无法选主的问题,这种情况下,建议部署独立的主节点,并且可以考虑适当增大 cluster.election.duration 的配置。
Top K 对检索的加速
这里的 Top K 主要是指在普通检索时展示前列的数据 Top K。也就是说 Elasticsearch 7.0 对检索数据的查询性能做了明显的改善。那是做了所有查询场景的提升么?
ELastic 做了这么一个场景假设:如果用户通常只关注搜索结果的第一页,且并不关心具体匹配的文档总数,对于超出一定数量的数据搜索引擎可以展示“超过 10,000 条结果”并提供分页浏览来优化搜索效率。但是在实际过程中用户常在查询中使用高频词(如“the”或“a”),这迫使 Elasticsearch 为大量文档计算评分,明显占用了查询资源的使用,即使这些常见词对相关性排序贡献甚微。
而现在,Elasticsearch 现在可以跳过那些在早期阶段就被判定为不会进入结果集顶部的低排名记录的评分计算,从而显著提升查询速度。这里主要涉及了 block-max WAND 算法的实现。这是一个复杂且漫长的优化过程,有兴趣的同学可以阅读一下这段Magic WAND: Faster Retrieval of Top Hits in Elasticsearch。
从 Elastic 的测试结果来看,新算法的优化让 term 查询加速了 3-7 倍。当然从场景背景可以看出,这个优化主要在大数据量下有明显效果(小数据量也不会有太多的日常高频词)。
默认开启 soft-delete 减少 translog
从 Elasticsearch 7.4 开始,副本的数据恢复,不再完全依赖 translog 了,而是通过索引的 soft-delete 特性(Elasticsearch 7.0 起所有新索引默认启用软删除 soft-deletes)。这样就可以缩小 translog 的使用场景,从而 translog 的保留大小也可以减少了。
那原来使用 translog 是什么样的呢?
translog 是 ES 用于保证数据安全性的重要工具。同时副分片进行恢复时,它也起着重要作用,只要副分片待获取的差异数据是在 translog 所保留的数据范围内,就可以只从 trasnlog 复制差异的部分数据,而不用拖取整个分片。在之前的版本中,Elasticsearch 默认会保留 512M 或 12 小时的 translog 用于副本恢复。
那现在使用的 soft-delete 是什么呢?
soft-deletes 是 Lucene 中实现的特性。这个软删除有时候会和 lucene 本身的标记删除概念发生混淆。为了方便理解,我们在这里归纳一下,lucene 实现删除的方式是一种标记删除的方式,而这种标记删除可以分为硬删除和软删除。软删除和硬删除有一个明显的区分点是:硬删除,被删除的文档对应的文档号用索引文件 .liv 来描述。软删除 soft-delete,被标记为删除的文档不使用索引文件.liv 来描述,而是通过索引文件 .dvd .dvm 来描述。
这里再扩展一下,.liv 文件主要实现 fixedbitset 数据结构。而 .dvd .dvm 则组合实现了 docvalue 这种正排数据结构。
正排索引的数据结构助力了 translog 的‘减负’,副本可以相对简便的通过软删除中的数据标记来实现数据恢复的处理。
相比较简洁高效的位图索引,docvalue 虽然实现了更多的功能,满足更多的场景,也会带来更多的问题。最明显的就是对于 update 操作,会导致 refresh 变得慢,有些压力场景下 refresh 会达到 10s 以上。
数值/日期排序查询加速
Elasticsearch 7.6 版本提升了按日期或数值(即任何存储为有符号 64 位整数(long 类型)的字段)进行排序的查询性能。
这背后的优化原理和之前 top K 使用的 Block-Max WAND 算法有点相似,都是利用算法跳过非竞争性文档来实现加速。
实际效果可能因环境而异,受多种参数影响。在 Elastic 进行的测试场景下,可以达到 35 倍的速度优化。
FST 内存使用迁移到堆外
Elastic 7.3 版本实现了这个优化,是藏在 release note 里的彩蛋。
Also mmap terms index (.tip) files for hybridfs #43150 (issue: #42838)
看似不经意的一行,但是带来效果却不小。FST 从堆内转移到堆外后,JVM 的空间可以空余出很客观的一部分。
一直以来,ES 堆中常驻内存中占据比重最大是 FST,即 tip(terms index) 文件占据的空间,1TB 索引大约占用 2GB 或者更多的内存,因此为了节点稳定运行,业界通常认为一个节点 open 的索引不超过 5TB。现在,从 ES 7.3 版本开始,将 tip 文件修改为通过 mmap 的方式加载,这使 FST 占据的内存从堆内转移到了堆外由操作系统的 pagecache 管理。
存储字段压缩优化
Elasticsearch 7.10 基于 Apache Lucene 8.7 引入了对存储字段(stored fields)的更高压缩率优化。不管是对于基于 DEFLATE 的 index.codec: best_compression 还是基于 LZ4 的index.codec: default都有不错的表现,在 Elastic 的测试场景下,最大可达到 10%的存储空间减少。
对于数据压缩 lucene 这次主要做了两个优化。
-
Elastic 研究发现在存储数据的时候,底层的 block 越大,压缩效果越好,因为中间被压缩的重复数据可能越多。但是大块的 block 也可能因为解码重复数据降低查询速度。
-
block 间通过共享字典来维持检索效率和数据压缩之间的平衡。
2.1. 首先为压缩算法提供一个数据字典,它也可以用于字符串重复数据删除。如果在要压缩的数据流和字典之间有许多重复的字符串,那么最终可以得到更好的压缩比。在解压缩时也通过字典来快速补足。
2.2. 同时,ES 使用更大的数据块,这些数据块本身被分成一个字典和 10 个子块,这些子块使用这个字典进行压缩。
而对于实际业务场景中,日志和监控数据的重复率往往会很好,因此在这两个场景中的压缩效果也是最明显的。
小结
当然,除了这几项外,ES 在各个版本中也做了不少优化,比如:调整 search.max_buckets 增加到 65534;Date histogram 聚合性能优化等等。有兴趣的同学可以参照各个版本的 release highlight
参考资料:
- Save space and money with improved storage efficiency in Elasticsearch 7.10
- Elasticsearch 7.3 的 offheap 原理
- Elasticsearch 7.4 的 soft-deletes 是个什么鬼
推荐阅读
- 谈谈 ES 6.8 到 7.10 的功能变迁(2)- 字段类型篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(4)- 聚合功能篇
- 谈谈 ES 6.8 到 7.10 的功能变迁(5)- 任务和集群管理
- 谈谈 ES 6.8 到 7.10 的功能变迁(6)- 其他
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/feature-evolution-from-elasticsearch-6.8-to-7.10-part-1/

