

【搜索客社区日报】第2084期 (2025-07-29)
1. 是时候用ES全家把你的nodejs应用管起来了(需要梯子)
https://medium.com/%40mfehmial ... 7eceb
2. 新功能解锁,反向检索(需要梯子)
https://medium.com/%40halilbul ... eb044
3. ES 聚合不准咋个办?(需要梯子)
https://rafayqayyum.medium.com ... 00443
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 是时候用ES全家把你的nodejs应用管起来了(需要梯子)
https://medium.com/%40mfehmial ... 7eceb
2. 新功能解锁,反向检索(需要梯子)
https://medium.com/%40halilbul ... eb044
3. ES 聚合不准咋个办?(需要梯子)
https://rafayqayyum.medium.com ... 00443
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch 集成阿里云与 Ollama Embedding API,构建端到端的语义搜索系统
背景
在当前 AI 与搜索深度融合的时代,语义搜索已成为企业级应用的核心能力之一。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅具备高性能、高可用、弹性伸缩等企业级特性,更通过灵活的插件化架构,支持多种主流 Embedding 模型服务,包括 阿里云通义千问(DashScope) 和 本地化 Ollama 服务,实现对 OpenAI 接口规范的完美兼容。
本文将详细介绍如何在 Easysearch 中集成阿里云和 Ollama 的 Embedding API,构建端到端的语义搜索系统,并提供完整的配置示例与流程图解析。
一、为什么选择 Easysearch?
Easysearch 是由极限科技(INFINI Labs)自主研发的分布式近实时搜索型数据库,具备以下核心优势:
- ✅ 完全兼容 Elasticsearch 7.x API 及 8.x 常用操作
- ✅ 原生支持向量检索(kNN)、语义搜索、混合检索
- ✅ 内置数据摄入管道与搜索管道,支持 AI 模型集成
- ✅ 支持国产化部署、数据安全可控
- ✅ 高性能、低延迟、可扩展性强
尤其在 AI 增强搜索场景中,Easysearch 提供了强大的 text_embedding 和 semantic_query_enricher 处理器,允许无缝接入外部 Embedding 模型服务。
二、支持的 Embedding 服务
Easysearch 通过标准 OpenAI 兼容接口无缝集成各类第三方 Embedding 模型服务,理论上支持所有符合 OpenAI Embedding API 规范的模型。以下是已验证的典型服务示例:
| 服务类型 | 模型示例 | 接口协议 | 部署方式 | 特点 |
|---|---|---|---|---|
| 云端 SaaS | 阿里云 DashScope | OpenAI 兼容 | 云端 | 开箱即用,高可用性 |
OpenAI text-embedding-3 |
OpenAI 原生 | 云端 | ||
| 其他兼容 OpenAI 的云服务 | OpenAI 兼容 | 云端 | ||
| 本地部署 | Ollama (nomic-embed-text等) |
自定义 API | 本地/私有化 | 数据隐私可控 |
| 自建开源模型(如 BGE、M3E) | OpenAI 兼容 | 本地/私有化 | 灵活定制 |
核心优势:
-
广泛兼容性
支持任意实现 OpenAI Embedding API 格式(/v1/embeddings)的服务,包括:- 请求格式:
{ "input": "text", "model": "model_name" } - 响应格式:
{ "data": [{ "embedding": [...] }] }
- 请求格式:
-
即插即用
仅需配置服务端点的base_url和api_key即可快速接入新模型。 - 混合部署
可同时配置多个云端或本地模型,根据业务需求灵活切换。
三、结合 AI 服务流程图
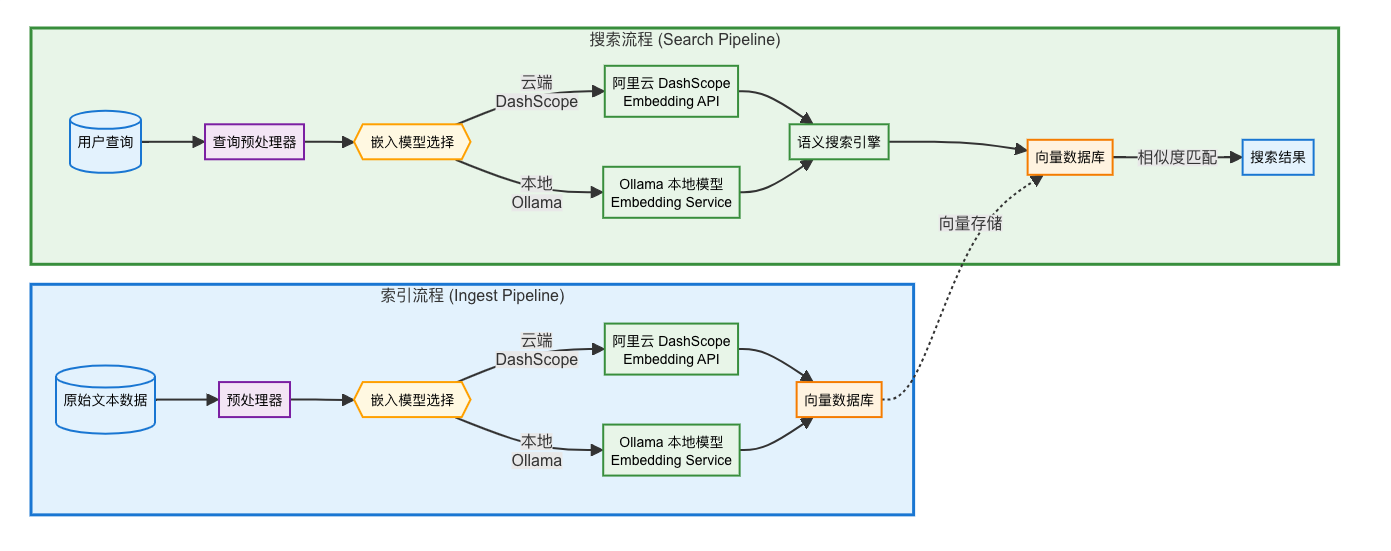
说明:
- 索引阶段:通过 Ingest Pipeline 调用 Embedding API,将文本转为向量并存储。
- 搜索阶段:通过 Search Pipeline 动态生成查询向量,执行语义相似度匹配。
- 所有 API 调用均兼容 OpenAI 接口格式,降低集成成本。
四、集成阿里云 DashScope(通义千问)
阿里云 DashScope 提供高性能文本嵌入模型 text-embedding-v4,支持 256 维向量输出,适用于中文语义理解任务。
1. 创建 Ingest Pipeline(索引时生成向量)
PUT _ingest/pipeline/text-embedding-aliyun
{
"description": "阿里云用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 256,
"batch_size": 5
}
}
]
}2. 创建索引并定义向量字段
PUT /my-index
{
"mappings": {
"properties": {
"input_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 256,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}3. 使用 Pipeline 批量写入数据
POST /_bulk?pipeline=text-embedding-aliyun&refresh=wait_for
{ "index": { "_index": "my-index", "_id": "1" } }
{ "input_text": "风急天高猿啸哀,渚清沙白鸟飞回..." }
{ "index": { "_index": "my-index", "_id": "2" } }
{ "input_text": "月落乌啼霜满天,江枫渔火对愁眠..." }
...4. 配置 Search Pipeline(搜索时动态生成向量)
PUT /_search/pipeline/search_model_aliyun
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "阿里云 search embedding model",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"text_vector": "text-embedding-v4"
}
}
}
]
}5. 设置索引默认搜索管道
PUT /my-index/_settings
{
"index.search.default_pipeline": "search_model_aliyun"
}6. 执行语义搜索
GET /my-index/_search
{
"_source": "input_text",
"query": {
"semantic": {
"text_vector": {
"query_text": "风急天高猿啸哀,渚清沙白鸟飞回...",
"candidates": 10,
"query_strategy": "LSH_COSINE"
}
}
}
}搜索结果示例:
"hits": [
{
"_id": "1",
"_score": 2.0,
"_source": { "input_text": "风急天高猿啸哀..." }
},
{
"_id": "4",
"_score": 1.75,
"_source": { "input_text": "白日依山尽..." }
},
...
]结果显示:相同诗句匹配得分最高,其他古诗按语义相似度排序,效果理想。
五、集成本地 Ollama 服务
Ollama 支持在本地运行开源 Embedding 模型(如 nomic-embed-text),适合对数据隐私要求高的场景。
1. 启动 Ollama 服务
ollama serve
ollama pull nomic-embed-text:latest2. 创建 Ingest Pipeline(使用 Ollama)
PUT _ingest/pipeline/ollama-embedding-pipeline
{
"description": "Ollama embedding 示例",
"processors": [
{
"text_embedding": {
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "nomic-embed-text:latest"
}
}
]
}3. 创建 Search Pipeline(搜索时使用 Ollama)
PUT /_search/pipeline/ollama_model_pipeline
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "Sets the ollama model",
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"default_model_id": "nomic-embed-text:latest",
"vector_field_model_id": {
"text_vector": "nomic-embed-text:latest"
}
}
}
]
}后续步骤与阿里云一致:创建索引 → 写入数据 → 搜索查询。
六、安全性说明
Easysearch 在处理 API Key 时采取以下安全措施:
- 🔐 所有
api_key在返回时自动加密脱敏(如TfUmLjPg...infinilabs) - 🔒 支持密钥管理插件(如 Hashicorp Vault 集成)
- 🛡️ 支持 HTTPS、RBAC、审计日志等企业级安全功能
确保敏感信息不被泄露,满足合规要求。
七、总结
通过 Easysearch 的 Ingest Pipeline 与 Search Pipeline,我们可以轻松集成:
- ✅ 阿里云 DashScope(云端高性能)
- ✅ Ollama(本地私有化部署)
- ✅ 其他支持 OpenAI 接口的 Embedding 服务
无论是追求性能还是数据安全,Easysearch 都能提供灵活、高效的语义搜索解决方案。
八、下一步建议
- 尝试混合检索:结合关键词匹配与语义搜索
- 使用 Rerank 模型提升排序精度
- 部署多节点集群提升吞吐量
- 接入 INFINI Gateway 实现统一 API 网关管理
参考链接
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Integration-with-Alibaba-CloudOllama-Embedding-API/
背景
在当前 AI 与搜索深度融合的时代,语义搜索已成为企业级应用的核心能力之一。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅具备高性能、高可用、弹性伸缩等企业级特性,更通过灵活的插件化架构,支持多种主流 Embedding 模型服务,包括 阿里云通义千问(DashScope) 和 本地化 Ollama 服务,实现对 OpenAI 接口规范的完美兼容。
本文将详细介绍如何在 Easysearch 中集成阿里云和 Ollama 的 Embedding API,构建端到端的语义搜索系统,并提供完整的配置示例与流程图解析。
一、为什么选择 Easysearch?
Easysearch 是由极限科技(INFINI Labs)自主研发的分布式近实时搜索型数据库,具备以下核心优势:
- ✅ 完全兼容 Elasticsearch 7.x API 及 8.x 常用操作
- ✅ 原生支持向量检索(kNN)、语义搜索、混合检索
- ✅ 内置数据摄入管道与搜索管道,支持 AI 模型集成
- ✅ 支持国产化部署、数据安全可控
- ✅ 高性能、低延迟、可扩展性强
尤其在 AI 增强搜索场景中,Easysearch 提供了强大的 text_embedding 和 semantic_query_enricher 处理器,允许无缝接入外部 Embedding 模型服务。
二、支持的 Embedding 服务
Easysearch 通过标准 OpenAI 兼容接口无缝集成各类第三方 Embedding 模型服务,理论上支持所有符合 OpenAI Embedding API 规范的模型。以下是已验证的典型服务示例:
| 服务类型 | 模型示例 | 接口协议 | 部署方式 | 特点 |
|---|---|---|---|---|
| 云端 SaaS | 阿里云 DashScope | OpenAI 兼容 | 云端 | 开箱即用,高可用性 |
OpenAI text-embedding-3 |
OpenAI 原生 | 云端 | ||
| 其他兼容 OpenAI 的云服务 | OpenAI 兼容 | 云端 | ||
| 本地部署 | Ollama (nomic-embed-text等) |
自定义 API | 本地/私有化 | 数据隐私可控 |
| 自建开源模型(如 BGE、M3E) | OpenAI 兼容 | 本地/私有化 | 灵活定制 |
核心优势:
-
广泛兼容性
支持任意实现 OpenAI Embedding API 格式(/v1/embeddings)的服务,包括:- 请求格式:
{ "input": "text", "model": "model_name" } - 响应格式:
{ "data": [{ "embedding": [...] }] }
- 请求格式:
-
即插即用
仅需配置服务端点的base_url和api_key即可快速接入新模型。 - 混合部署
可同时配置多个云端或本地模型,根据业务需求灵活切换。
三、结合 AI 服务流程图
说明:
- 索引阶段:通过 Ingest Pipeline 调用 Embedding API,将文本转为向量并存储。
- 搜索阶段:通过 Search Pipeline 动态生成查询向量,执行语义相似度匹配。
- 所有 API 调用均兼容 OpenAI 接口格式,降低集成成本。
四、集成阿里云 DashScope(通义千问)
阿里云 DashScope 提供高性能文本嵌入模型 text-embedding-v4,支持 256 维向量输出,适用于中文语义理解任务。
1. 创建 Ingest Pipeline(索引时生成向量)
PUT _ingest/pipeline/text-embedding-aliyun
{
"description": "阿里云用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 256,
"batch_size": 5
}
}
]
}2. 创建索引并定义向量字段
PUT /my-index
{
"mappings": {
"properties": {
"input_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 256,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}3. 使用 Pipeline 批量写入数据
POST /_bulk?pipeline=text-embedding-aliyun&refresh=wait_for
{ "index": { "_index": "my-index", "_id": "1" } }
{ "input_text": "风急天高猿啸哀,渚清沙白鸟飞回..." }
{ "index": { "_index": "my-index", "_id": "2" } }
{ "input_text": "月落乌啼霜满天,江枫渔火对愁眠..." }
...4. 配置 Search Pipeline(搜索时动态生成向量)
PUT /_search/pipeline/search_model_aliyun
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "阿里云 search embedding model",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"text_vector": "text-embedding-v4"
}
}
}
]
}5. 设置索引默认搜索管道
PUT /my-index/_settings
{
"index.search.default_pipeline": "search_model_aliyun"
}6. 执行语义搜索
GET /my-index/_search
{
"_source": "input_text",
"query": {
"semantic": {
"text_vector": {
"query_text": "风急天高猿啸哀,渚清沙白鸟飞回...",
"candidates": 10,
"query_strategy": "LSH_COSINE"
}
}
}
}搜索结果示例:
"hits": [
{
"_id": "1",
"_score": 2.0,
"_source": { "input_text": "风急天高猿啸哀..." }
},
{
"_id": "4",
"_score": 1.75,
"_source": { "input_text": "白日依山尽..." }
},
...
]结果显示:相同诗句匹配得分最高,其他古诗按语义相似度排序,效果理想。
五、集成本地 Ollama 服务
Ollama 支持在本地运行开源 Embedding 模型(如 nomic-embed-text),适合对数据隐私要求高的场景。
1. 启动 Ollama 服务
ollama serve
ollama pull nomic-embed-text:latest2. 创建 Ingest Pipeline(使用 Ollama)
PUT _ingest/pipeline/ollama-embedding-pipeline
{
"description": "Ollama embedding 示例",
"processors": [
{
"text_embedding": {
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "nomic-embed-text:latest"
}
}
]
}3. 创建 Search Pipeline(搜索时使用 Ollama)
PUT /_search/pipeline/ollama_model_pipeline
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "Sets the ollama model",
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"default_model_id": "nomic-embed-text:latest",
"vector_field_model_id": {
"text_vector": "nomic-embed-text:latest"
}
}
}
]
}后续步骤与阿里云一致:创建索引 → 写入数据 → 搜索查询。
六、安全性说明
Easysearch 在处理 API Key 时采取以下安全措施:
- 🔐 所有
api_key在返回时自动加密脱敏(如TfUmLjPg...infinilabs) - 🔒 支持密钥管理插件(如 Hashicorp Vault 集成)
- 🛡️ 支持 HTTPS、RBAC、审计日志等企业级安全功能
确保敏感信息不被泄露,满足合规要求。
七、总结
通过 Easysearch 的 Ingest Pipeline 与 Search Pipeline,我们可以轻松集成:
- ✅ 阿里云 DashScope(云端高性能)
- ✅ Ollama(本地私有化部署)
- ✅ 其他支持 OpenAI 接口的 Embedding 服务
无论是追求性能还是数据安全,Easysearch 都能提供灵活、高效的语义搜索解决方案。
八、下一步建议
- 尝试混合检索:结合关键词匹配与语义搜索
- 使用 Rerank 模型提升排序精度
- 部署多节点集群提升吞吐量
- 接入 INFINI Gateway 实现统一 API 网关管理
参考链接
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
收起阅读 »作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Integration-with-Alibaba-CloudOllama-Embedding-API/
【搜索客社区日报】第2082期 (2025-07-24)
https://rlancemartin.github.io ... ring/
2.开源我的 Claude Code 配置:Vibe Coding 的终极工作流
https://mp.weixin.qq.com/s/QlqKEZoXJnxR1upn_U-wSg
3.如何利用pytorch memory snapshot进行显存分析
https://mp.weixin.qq.com/s/lJGkJ5fB62oKQdU8yhjAlA
4.谈谈Agentic AI对Infra的需求
https://mp.weixin.qq.com/s/es2ZIRDTQQ_Z0fifyKzodQ
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://rlancemartin.github.io ... ring/
2.开源我的 Claude Code 配置:Vibe Coding 的终极工作流
https://mp.weixin.qq.com/s/QlqKEZoXJnxR1upn_U-wSg
3.如何利用pytorch memory snapshot进行显存分析
https://mp.weixin.qq.com/s/lJGkJ5fB62oKQdU8yhjAlA
4.谈谈Agentic AI对Infra的需求
https://mp.weixin.qq.com/s/es2ZIRDTQQ_Z0fifyKzodQ
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2081期 (2025-07-23)
https://mp.weixin.qq.com/s/9yfWiDznPc8UMYuheALc-A
2.使用 Maximum Marginal Relevance 实现搜索结果多样化
https://zhuanlan.zhihu.com/p/1928403646300820102
3.归纳了一些最常见的向量搜索误区(搭梯)
https://medium.com/kx-systems/ ... b976d
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/9yfWiDznPc8UMYuheALc-A
2.使用 Maximum Marginal Relevance 实现搜索结果多样化
https://zhuanlan.zhihu.com/p/1928403646300820102
3.归纳了一些最常见的向量搜索误区(搭梯)
https://medium.com/kx-systems/ ... b976d
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2080期 (2025-07-22)
https://medium.com/%40Alexande ... 5c46d
2. 来看看老司机是怎么用ES做到devops一把梭的(需要梯子)
https://medium.com/%40valeront ... 452ef
3. 又是分片过量这个坏小子拖慢了我的集群!(需要梯子)
https://medium.com/%40ameersoh ... 07582
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40Alexande ... 5c46d
2. 来看看老司机是怎么用ES做到devops一把梭的(需要梯子)
https://medium.com/%40valeront ... 452ef
3. 又是分片过量这个坏小子拖慢了我的集群!(需要梯子)
https://medium.com/%40ameersoh ... 07582
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2079期 (2025-07-21)
https://elasticstack.blog.csdn ... 59222
2、AI 驱动的仪表板:从愿景到 Kibana
https://elasticstack.blog.csdn ... .5502
3、ES|QL(Elasticsearch 查询语言)入门
https://elasticstack.blog.csdn ... 99991
4、Elasticsearch 集群慢写入调优
https://mp.weixin.qq.com/s/wSe3lwGOxERQoM-qfDlmpw
5、逐层推理:单张24G显卡推理Qwen3-14B
https://mp.weixin.qq.com/s/dHLg_aX7hvuna-QI6Rhh-w
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 59222
2、AI 驱动的仪表板:从愿景到 Kibana
https://elasticstack.blog.csdn ... .5502
3、ES|QL(Elasticsearch 查询语言)入门
https://elasticstack.blog.csdn ... 99991
4、Elasticsearch 集群慢写入调优
https://mp.weixin.qq.com/s/wSe3lwGOxERQoM-qfDlmpw
5、逐层推理:单张24G显卡推理Qwen3-14B
https://mp.weixin.qq.com/s/dHLg_aX7hvuna-QI6Rhh-w
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
TDBC 2025 大会聚焦 AI 与数据库融合,极限科技发布新一代 Coco AI 搜索平台
2025 年 7 月 17 日 在北京召开的 TDBC 2025 可信数据库发展大会·人工智能与数据库融合发展分论坛 上,国内领先的搜索数据库及解决方案提供商 极限科技(INFINI Labs)正式发布其创新产品 —— Coco AI,一款面向企业的 AI 智能搜索与高效协作平台。极限数据(北京)科技有限公司创始人曾勇在《下一代企业搜索与 AI 的融合探索》主题演讲中,深入探讨了企业搜索的未来趋势及 Coco AI 的核心价值。

破解企业数据困境:多平台孤岛与隐私安全挑战
随着企业数据呈爆发式增长,信息分散在本地文件系统、云存储(如 S3)、协作工具(如内网 Wiki、工单系统、 CRM、ERP 等)及代码仓库(如 Gitcode、Gitee 等)等多个平台,员工往往需要频繁切换系统进行检索,效率低下。同时,企业对数据隐私和安全的高标准要求,使得直接使用公有云 AI 工具或上云存储存在潜在风险。此外,企业内部积累的海量知识未能有效转化为生产力,传统知识库管理依赖人工维护,效果有限。

Coco AI 的推出,正是为了帮助企业解决这些痛点,通过统一搜索、AI 增强、隐私优先的设计理念,打造一站式智能搜索中心,提升知识利用效率与协作体验。
Coco AI 核心功能:重新定义企业搜索与协作

- 跨平台统一搜索
- 支持本地文件、云端应用或自研各业务系统及第三方平台的无缝搜索,提供“本地搜”“云端搜”“混合搜”及“多模态搜”(文本、语音、图像、视频)能力,彻底告别数据碎片化。
- 无缝 AI 集成
- 基于语义搜索与生成式 AI 技术,支持快速提取企业内部知识,并接入 OpenAI、DeepSeek 等主流大模型。
- 相比集中式知识库,采用联邦数据连接方式,降低维护成本。
- 提供高度可定制的 RAG(检索增强生成)管道,让 AI 回答更精准、更贴合业务需求。
- 隐私优先设计
- 支持自托管部署,数据全程加密,提供企业级权限控制与动态脱敏功能,确保敏感信息不外泄,满足金融、医疗等高合规性行业需求。
- 灵活扩展性
- 通过 MCP 协议、Connector 及 Remote Search Adapter(RSA)对接企业自有数据源,支持 API 和插件扩展,适配多样化业务场景。
轻量级体验,高效团队协作
Coco AI 以“轻量级、无存在感”为设计理念,内置实用工具(如计算器、便签)及团队协作功能,支持快速定位共享资源。其智能助手可在搜索中实时总结结果,提升决策效率。此外,APP 端支持多服务器连接,实现跨域协作而无需集中同步数据,兼顾便利性与安全性。
技术架构与生态兼容
Coco AI Server 基于极限科技的搜索型数据库的 Easysearch 即可运行,支持从单机到 PB 级分布式扩展,并针对中文语义进行了深度优化。其开放生态兼容 MCP 协议、主流大模型及第三方工具,企业可灵活集成现有系统,降低迁移成本。
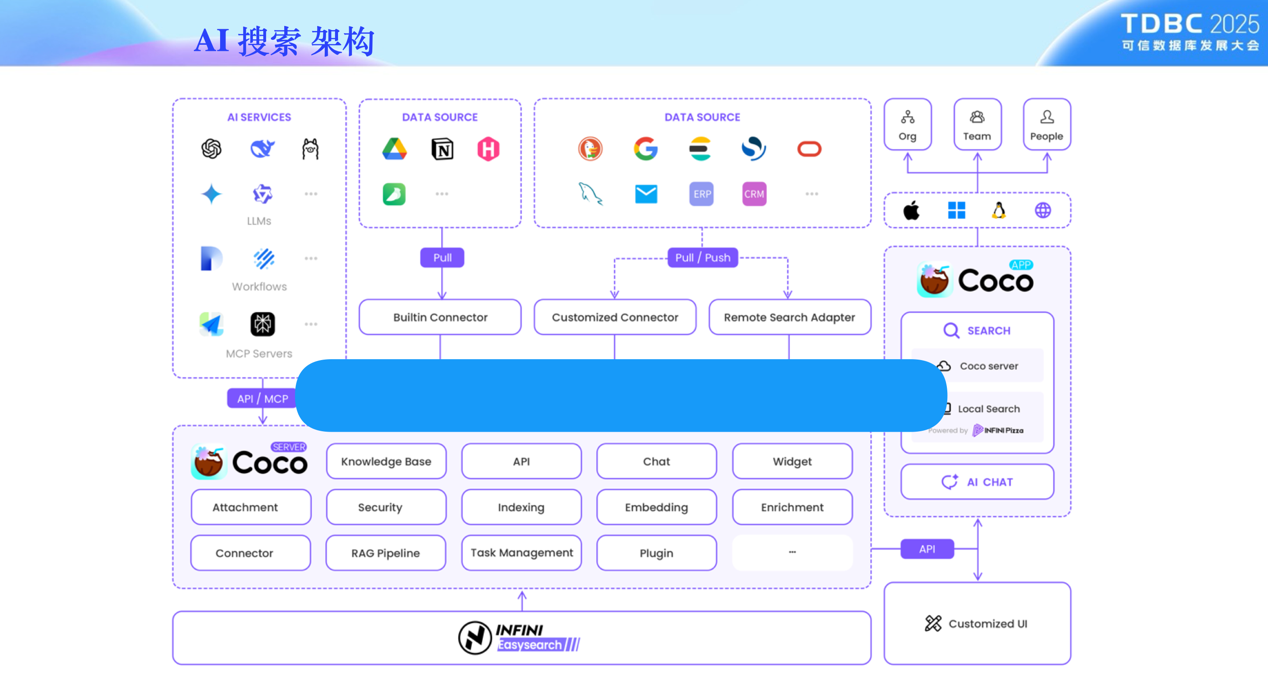
开源共建,赋能开发者生态
极限科技始终秉持开放合作理念,Coco AI 已正式开源,并邀请全球开发者共同参与生态建设。用户可通过 GitHub/Gitee/GitCode 来获取代码、提交贡献,或加入官方社群获取技术支持。

曾勇表示:“Coco AI 的诞生,不仅是极限科技在搜索与 AI 融合领域的一次重大突破,更是我们对‘让搜索更简单’这一使命的践行。未来,我们将持续优化产品,助力企业释放数据价值,迈向智能化搜索新未来。”
2025 年 7 月 17 日 在北京召开的 TDBC 2025 可信数据库发展大会·人工智能与数据库融合发展分论坛 上,国内领先的搜索数据库及解决方案提供商 极限科技(INFINI Labs)正式发布其创新产品 —— Coco AI,一款面向企业的 AI 智能搜索与高效协作平台。极限数据(北京)科技有限公司创始人曾勇在《下一代企业搜索与 AI 的融合探索》主题演讲中,深入探讨了企业搜索的未来趋势及 Coco AI 的核心价值。
破解企业数据困境:多平台孤岛与隐私安全挑战
随着企业数据呈爆发式增长,信息分散在本地文件系统、云存储(如 S3)、协作工具(如内网 Wiki、工单系统、 CRM、ERP 等)及代码仓库(如 Gitcode、Gitee 等)等多个平台,员工往往需要频繁切换系统进行检索,效率低下。同时,企业对数据隐私和安全的高标准要求,使得直接使用公有云 AI 工具或上云存储存在潜在风险。此外,企业内部积累的海量知识未能有效转化为生产力,传统知识库管理依赖人工维护,效果有限。
Coco AI 的推出,正是为了帮助企业解决这些痛点,通过统一搜索、AI 增强、隐私优先的设计理念,打造一站式智能搜索中心,提升知识利用效率与协作体验。
Coco AI 核心功能:重新定义企业搜索与协作
- 跨平台统一搜索
- 支持本地文件、云端应用或自研各业务系统及第三方平台的无缝搜索,提供“本地搜”“云端搜”“混合搜”及“多模态搜”(文本、语音、图像、视频)能力,彻底告别数据碎片化。
- 无缝 AI 集成
- 基于语义搜索与生成式 AI 技术,支持快速提取企业内部知识,并接入 OpenAI、DeepSeek 等主流大模型。
- 相比集中式知识库,采用联邦数据连接方式,降低维护成本。
- 提供高度可定制的 RAG(检索增强生成)管道,让 AI 回答更精准、更贴合业务需求。
- 隐私优先设计
- 支持自托管部署,数据全程加密,提供企业级权限控制与动态脱敏功能,确保敏感信息不外泄,满足金融、医疗等高合规性行业需求。
- 灵活扩展性
- 通过 MCP 协议、Connector 及 Remote Search Adapter(RSA)对接企业自有数据源,支持 API 和插件扩展,适配多样化业务场景。
轻量级体验,高效团队协作
Coco AI 以“轻量级、无存在感”为设计理念,内置实用工具(如计算器、便签)及团队协作功能,支持快速定位共享资源。其智能助手可在搜索中实时总结结果,提升决策效率。此外,APP 端支持多服务器连接,实现跨域协作而无需集中同步数据,兼顾便利性与安全性。
技术架构与生态兼容
Coco AI Server 基于极限科技的搜索型数据库的 Easysearch 即可运行,支持从单机到 PB 级分布式扩展,并针对中文语义进行了深度优化。其开放生态兼容 MCP 协议、主流大模型及第三方工具,企业可灵活集成现有系统,降低迁移成本。
开源共建,赋能开发者生态
极限科技始终秉持开放合作理念,Coco AI 已正式开源,并邀请全球开发者共同参与生态建设。用户可通过 GitHub/Gitee/GitCode 来获取代码、提交贡献,或加入官方社群获取技术支持。
曾勇表示:“Coco AI 的诞生,不仅是极限科技在搜索与 AI 融合领域的一次重大突破,更是我们对‘让搜索更简单’这一使命的践行。未来,我们将持续优化产品,助力企业释放数据价值,迈向智能化搜索新未来。”
收起阅读 »极限科技亮相 TDBC 2025 可信数据库发展大会——联合创始人曾嘉毅分享搜索型数据库生态建设新成果
2025 年 7 月 17 日 在北京召开的 TDBC 2025 可信数据库发展大会·数据库生态及国际化分论坛 上,全球数据库领域专家、学者与企业代表齐聚。极限数据(北京)科技有限公司联合创始人曾嘉毅发表《搜索型数据库生态建设及展望》主题演讲,剖析技术创新与实践,为行业提供高效数据检索与智能应用方案。

破解数据检索挑战,AI 赋能搜索升级
首先,我们需要面对结构化数据。典型处理方式是使用传统关系型数据库。但是,关系型数据库的设计初衷就决定了它面对的挑战:关系型数据库优先保证事务性,其数据分层结构导致查询需要层层下钻,同时传统关系型数据库能够处理的数据规模也是受限的。搜索型数据库针对以上挑战可以实现读写分离、多表聚合查询、数据库加速等。
与此同时,企业数据中大约 85% 为非结构化或半结构化数据,如图片、视频等,传统数据库处理困难。极限科技运用语义解析与 AI 向量化技术,语义解析深入理解数据语义并转化为结构化信息,AI 向量化将其映射到高维空间实现向量化表示,二者结合完成非结构化数据的标签提取与索引构建,提升检索准确性与效率。

针对中文文本,极限科技进行字段化处理研究。中文语法复杂、语义丰富,传统方法难以满足检索需求。公司通过自研算法精准分词与字段提取,结合向量化技术提升中文数据检索效果。同时,融合向量化全量搜索与模糊搜索,前者快速定位相似数据,后者处理用户输入的不准确信息,提高搜索容错性。
平台化建设与工具开源:打造全链路能力
极限科技构建的管控平台功能强大。支持多集群元原生编排和管理,企业可依业务场景和用户需求灵活调整集群资源,同时实现一键升级、备份管理等;提供统一监控、统一身份管理服务,实时监控系统组件与运行状态,及时预警问题。该平台兼容多厂商环境,企业可无缝集成现有系统,降低迁移成本与风险。公司开发的搜索服务网关针对检索服务提供流量分发与链路加速能力,进而实现查询分析、干预等高阶功能。

此外,极限科技积极推动搜索周边工具开源贡献。数据迁移工具 ESM 助力企业快速安全迁移数据至自家搜索型数据库,缩短迁移周期、降低风险;性能压测工具 Loadgen 模拟复杂场景测试系统性能,评估性能瓶颈与承载能力;中文分词工具 IK/Pinyin 支持多种分词模式与自定义词典,满足不同用户需求。开源工具促进技术交流创新,支持行业生态发展。
“Coco” AI 搜索与智能体结合模式:重构搜索体验
Coco AI 采用获得国家专利设计的人机交互体验,将搜索与 AI 进行无缝结合。传统 RAG 存在大模型直接回答搜索问题存在训练成本高、回答不精准问题。 Coco AI 后台灵活,支持为不同类型问题分配专属“小助手”。“小助手”针对特定问题优化配置,精准理解用户意图、提供准确回答,降低训练成本、提升回答精准度与效率。可以快速量身打造企业专属的 AI 智能体工具箱。

Coco AI 结合本地与云端协同搜索技术,连接本地文件、数据库及外部应用系统数据源。用户搜索时,可以同时对本地和外部 Coco Server 引擎同时处理查询请求,然后对结果进行打分与整合去重排序,结合大模型总结分析最终结果,实现意图理解与统一信息获取,打破信息孤岛,提供全面准确高效的搜索服务。
展望未来:AI 搜索与开放生态
极限科技对搜索型数据库未来有清晰规划。下一代 AI 搜索架构将深度融合向量检索与智能体技术。向量检索已发挥重要作用,智能体技术能自主感知、决策与行动。二者融合使 AI 搜索系统更智能理解用户需求,主动提供个性化服务,如依历史记录推荐信息,面对复杂任务自主分解协调资源处理。
在企业数据应用场景上,下一代架构将进一步优化拓展。除传统文档检索、数据查询,还将深入生产、运营、管理等环节,提供全面深入的数据分析与决策支持。如在生产制造中实时分析设备数据、提前发现故障隐患;在市场营销中深度挖掘客户数据、制定精准营销策略。

为推动行业发展,极限科技将持续推进开源战略,通过 GitHub/Gitee/GitCode 等平台共享核心技术代码与文档,与全球开发者紧密合作。吸引更多开发者参与研发创新,共同解决技术难题。同时积极参与行业标准制定推广,促进市场规范化标准化发展,构建开放共享共赢的搜索型数据库生态。
此次分享展示了极限科技的技术实力与创新成果,为行业发展提供新思路方向。相信未来,极限科技将秉持创新、开放、合作理念,推动技术发展应用,为企业数字化转型与行业发展注入新动力。
2025 年 7 月 17 日 在北京召开的 TDBC 2025 可信数据库发展大会·数据库生态及国际化分论坛 上,全球数据库领域专家、学者与企业代表齐聚。极限数据(北京)科技有限公司联合创始人曾嘉毅发表《搜索型数据库生态建设及展望》主题演讲,剖析技术创新与实践,为行业提供高效数据检索与智能应用方案。
破解数据检索挑战,AI 赋能搜索升级
首先,我们需要面对结构化数据。典型处理方式是使用传统关系型数据库。但是,关系型数据库的设计初衷就决定了它面对的挑战:关系型数据库优先保证事务性,其数据分层结构导致查询需要层层下钻,同时传统关系型数据库能够处理的数据规模也是受限的。搜索型数据库针对以上挑战可以实现读写分离、多表聚合查询、数据库加速等。
与此同时,企业数据中大约 85% 为非结构化或半结构化数据,如图片、视频等,传统数据库处理困难。极限科技运用语义解析与 AI 向量化技术,语义解析深入理解数据语义并转化为结构化信息,AI 向量化将其映射到高维空间实现向量化表示,二者结合完成非结构化数据的标签提取与索引构建,提升检索准确性与效率。
针对中文文本,极限科技进行字段化处理研究。中文语法复杂、语义丰富,传统方法难以满足检索需求。公司通过自研算法精准分词与字段提取,结合向量化技术提升中文数据检索效果。同时,融合向量化全量搜索与模糊搜索,前者快速定位相似数据,后者处理用户输入的不准确信息,提高搜索容错性。
平台化建设与工具开源:打造全链路能力
极限科技构建的管控平台功能强大。支持多集群元原生编排和管理,企业可依业务场景和用户需求灵活调整集群资源,同时实现一键升级、备份管理等;提供统一监控、统一身份管理服务,实时监控系统组件与运行状态,及时预警问题。该平台兼容多厂商环境,企业可无缝集成现有系统,降低迁移成本与风险。公司开发的搜索服务网关针对检索服务提供流量分发与链路加速能力,进而实现查询分析、干预等高阶功能。
此外,极限科技积极推动搜索周边工具开源贡献。数据迁移工具 ESM 助力企业快速安全迁移数据至自家搜索型数据库,缩短迁移周期、降低风险;性能压测工具 Loadgen 模拟复杂场景测试系统性能,评估性能瓶颈与承载能力;中文分词工具 IK/Pinyin 支持多种分词模式与自定义词典,满足不同用户需求。开源工具促进技术交流创新,支持行业生态发展。
“Coco” AI 搜索与智能体结合模式:重构搜索体验
Coco AI 采用获得国家专利设计的人机交互体验,将搜索与 AI 进行无缝结合。传统 RAG 存在大模型直接回答搜索问题存在训练成本高、回答不精准问题。 Coco AI 后台灵活,支持为不同类型问题分配专属“小助手”。“小助手”针对特定问题优化配置,精准理解用户意图、提供准确回答,降低训练成本、提升回答精准度与效率。可以快速量身打造企业专属的 AI 智能体工具箱。
Coco AI 结合本地与云端协同搜索技术,连接本地文件、数据库及外部应用系统数据源。用户搜索时,可以同时对本地和外部 Coco Server 引擎同时处理查询请求,然后对结果进行打分与整合去重排序,结合大模型总结分析最终结果,实现意图理解与统一信息获取,打破信息孤岛,提供全面准确高效的搜索服务。
展望未来:AI 搜索与开放生态
极限科技对搜索型数据库未来有清晰规划。下一代 AI 搜索架构将深度融合向量检索与智能体技术。向量检索已发挥重要作用,智能体技术能自主感知、决策与行动。二者融合使 AI 搜索系统更智能理解用户需求,主动提供个性化服务,如依历史记录推荐信息,面对复杂任务自主分解协调资源处理。
在企业数据应用场景上,下一代架构将进一步优化拓展。除传统文档检索、数据查询,还将深入生产、运营、管理等环节,提供全面深入的数据分析与决策支持。如在生产制造中实时分析设备数据、提前发现故障隐患;在市场营销中深度挖掘客户数据、制定精准营销策略。
为推动行业发展,极限科技将持续推进开源战略,通过 GitHub/Gitee/GitCode 等平台共享核心技术代码与文档,与全球开发者紧密合作。吸引更多开发者参与研发创新,共同解决技术难题。同时积极参与行业标准制定推广,促进市场规范化标准化发展,构建开放共享共赢的搜索型数据库生态。
此次分享展示了极限科技的技术实力与创新成果,为行业发展提供新思路方向。相信未来,极限科技将秉持创新、开放、合作理念,推动技术发展应用,为企业数字化转型与行业发展注入新动力。
收起阅读 »【搜索客社区日报】第2078期 (2025-07-18)
https://my.oschina.net/u/7209245/blog/18684967
2、Coco AI 快速构建本地文档知识库增强检索+智能问答系统
https://mp.weixin.qq.com/s/fcchZQm_FLuW_jhrZVwJlQ
3、一文了解 - Elasticsearch 搜索的底层原理-解析
https://mp.weixin.qq.com/s/06e_iIN43BgKVYJNAnmoLA
4、本地 RAG 实战:用 Easysearch + Ollama SDK 半小时搭建检索增强问答系统
https://mp.weixin.qq.com/s/G4Wk_A7G7QiZIQpjCYJ1kw
5、会 Vibe Coding(氛围编程) 的同事:我一个人干掉整个技术部!
https://mp.weixin.qq.com/s/1nV-3YCPBJcnpNasb_fN3A
编辑:Fred
更多资讯:http://news.searchkit.cn
https://my.oschina.net/u/7209245/blog/18684967
2、Coco AI 快速构建本地文档知识库增强检索+智能问答系统
https://mp.weixin.qq.com/s/fcchZQm_FLuW_jhrZVwJlQ
3、一文了解 - Elasticsearch 搜索的底层原理-解析
https://mp.weixin.qq.com/s/06e_iIN43BgKVYJNAnmoLA
4、本地 RAG 实战:用 Easysearch + Ollama SDK 半小时搭建检索增强问答系统
https://mp.weixin.qq.com/s/G4Wk_A7G7QiZIQpjCYJ1kw
5、会 Vibe Coding(氛围编程) 的同事:我一个人干掉整个技术部!
https://mp.weixin.qq.com/s/1nV-3YCPBJcnpNasb_fN3A
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
极限科技亮相 TDBC 2025 可信数据库发展大会,连续三年荣誉入选信通院《中国数据库产业图谱》
2025 年 7 月 16 日,由中国通信标准化协会主办、中国信息通信研究院(以下简称“中国信通院”)承办的“TDBC 2025 可信数据库发展大会”在北京隆重召开。作为我国数据库领域的年度权威盛会,本次大会以“自主·创新·引领”为主题,聚焦数据库技术创新与产业实践,发布了多项前沿研究成果,并深入探讨了行业发展趋势。极限科技受邀参会,并凭借在搜索型数据库领域的突出表现,连续三年荣誉入选《中国数据库产业图谱(2025 年)》,再次彰显其技术实力与市场影响力。

权威盛会聚焦技术前沿,共绘产业新蓝图
TDBC 2025 可信数据库发展大会是我国数据库行业规格最高、影响力最广的年度盛会之一。本届大会汇聚了政府主管部门、行业领袖、科研机构及企业代表,围绕数据库核心技术突破、行业应用落地、生态协同发展等议题展开深度交流。中国信通院在会上发布了一系列重磅研究成果,其中《中国数据库产业图谱》作为全面展示国内数据库产业生态的权威报告,备受业界关注。
极限科技连续三年入选产业图谱,搜索型数据库代表获权威认可
《中国数据库产业图谱(2025 年)》由中国信通院基于产品技术能力、产业服务水平、市场表现及生态建设等多维度综合评估编制,旨在为行业用户提供选型参考,推动资源向优质企业集聚。极限科技作为搜索型数据库的代表企业之一,凭借其自主研发的分布式搜索分析引擎、高性能实时数据处理能力,以及在金融、政务、能源等关键行业的深度实践,连续三年荣誉入选图谱,并收录于搜索型数据库及数据库生态社区技术社区版块,成为数据库产业生态中的标杆企业。
 图:极限科技荣誉入选中国信通院《中国数据库产业图谱(2025 年)》
图:极限科技荣誉入选中国信通院《中国数据库产业图谱(2025 年)》
极限科技相关负责人表示:“连续三年入选产业图谱,既是行业对极限科技技术实力的肯定,也是我们持续深耕搜索型数据库领域的动力。未来,我们将继续坚持自主创新,深化技术突破,为行业客户提供更高效、更智能的数据检索与分析解决方案。”
以自主创新为引擎,引领搜索型数据库高质量发展
当前,随着企业数字化转型的加速,海量数据的实时检索与智能分析已成为刚需。极限科技聚焦搜索型数据库核心技术,通过分布式架构、AI 融合、云原生等技术创新,打造了覆盖数据全生命周期的产品矩阵。其核心产品支持 PB 级数据秒级响应,并具备高可用、弹性扩展等特性,已在多个国家级项目中落地应用,助力客户实现数据治理能力与业务效能的双重提升。

此次大会上,极限科技还与业界同仁共同探讨了搜索型数据库如何支撑数字经济高质量发展。与会专家指出,随着数据要素价值的加速释放,搜索型数据库作为挖掘数据价值的关键工具,其自主创新水平直接关系到国家数据安全与产业竞争力。极限科技的实践为行业提供了可复制的范本,彰显了中国数据库企业的责任与担当。
展望未来:携手生态伙伴,共筑可信数据底座
极限科技表示,未来将持续深化与中国信通院等权威机构的合作,积极参与标准制定与生态共建,推动搜索型数据库技术与产业需求的深度融合。同时,公司将加大研发投入,探索数据库与人工智能等新技术的协同创新,为构建安全、高效、智能的数据基础设施贡献力量。
TDBC 2025 可信数据库发展大会的圆满落幕,标志着我国数据库产业迈向更高水平的自主创新阶段。极限科技将以此次入选产业图谱为契机,携手行业伙伴,共同书写中国数据库产业的新篇章。
2025 年 7 月 16 日,由中国通信标准化协会主办、中国信息通信研究院(以下简称“中国信通院”)承办的“TDBC 2025 可信数据库发展大会”在北京隆重召开。作为我国数据库领域的年度权威盛会,本次大会以“自主·创新·引领”为主题,聚焦数据库技术创新与产业实践,发布了多项前沿研究成果,并深入探讨了行业发展趋势。极限科技受邀参会,并凭借在搜索型数据库领域的突出表现,连续三年荣誉入选《中国数据库产业图谱(2025 年)》,再次彰显其技术实力与市场影响力。
权威盛会聚焦技术前沿,共绘产业新蓝图
TDBC 2025 可信数据库发展大会是我国数据库行业规格最高、影响力最广的年度盛会之一。本届大会汇聚了政府主管部门、行业领袖、科研机构及企业代表,围绕数据库核心技术突破、行业应用落地、生态协同发展等议题展开深度交流。中国信通院在会上发布了一系列重磅研究成果,其中《中国数据库产业图谱》作为全面展示国内数据库产业生态的权威报告,备受业界关注。
极限科技连续三年入选产业图谱,搜索型数据库代表获权威认可
《中国数据库产业图谱(2025 年)》由中国信通院基于产品技术能力、产业服务水平、市场表现及生态建设等多维度综合评估编制,旨在为行业用户提供选型参考,推动资源向优质企业集聚。极限科技作为搜索型数据库的代表企业之一,凭借其自主研发的分布式搜索分析引擎、高性能实时数据处理能力,以及在金融、政务、能源等关键行业的深度实践,连续三年荣誉入选图谱,并收录于搜索型数据库及数据库生态社区技术社区版块,成为数据库产业生态中的标杆企业。
图:极限科技荣誉入选中国信通院《中国数据库产业图谱(2025 年)》
极限科技相关负责人表示:“连续三年入选产业图谱,既是行业对极限科技技术实力的肯定,也是我们持续深耕搜索型数据库领域的动力。未来,我们将继续坚持自主创新,深化技术突破,为行业客户提供更高效、更智能的数据检索与分析解决方案。”
以自主创新为引擎,引领搜索型数据库高质量发展
当前,随着企业数字化转型的加速,海量数据的实时检索与智能分析已成为刚需。极限科技聚焦搜索型数据库核心技术,通过分布式架构、AI 融合、云原生等技术创新,打造了覆盖数据全生命周期的产品矩阵。其核心产品支持 PB 级数据秒级响应,并具备高可用、弹性扩展等特性,已在多个国家级项目中落地应用,助力客户实现数据治理能力与业务效能的双重提升。
此次大会上,极限科技还与业界同仁共同探讨了搜索型数据库如何支撑数字经济高质量发展。与会专家指出,随着数据要素价值的加速释放,搜索型数据库作为挖掘数据价值的关键工具,其自主创新水平直接关系到国家数据安全与产业竞争力。极限科技的实践为行业提供了可复制的范本,彰显了中国数据库企业的责任与担当。
展望未来:携手生态伙伴,共筑可信数据底座
极限科技表示,未来将持续深化与中国信通院等权威机构的合作,积极参与标准制定与生态共建,推动搜索型数据库技术与产业需求的深度融合。同时,公司将加大研发投入,探索数据库与人工智能等新技术的协同创新,为构建安全、高效、智能的数据基础设施贡献力量。
TDBC 2025 可信数据库发展大会的圆满落幕,标志着我国数据库产业迈向更高水平的自主创新阶段。极限科技将以此次入选产业图谱为契机,携手行业伙伴,共同书写中国数据库产业的新篇章。
收起阅读 »【搜索客社区日报】第2077期 (2025-07-17)
https://mp.weixin.qq.com/s/9l1Uupthv9zBqvo5v_N94g
2.AWS Kiro 最懂程序员的IDE - SPEC模式初体验,稳得出人意料!
https://www.bilibili.com/video/BV18vgwzYEri/
3.Chunked-Prefills 分块预填充机制详解
https://mp.weixin.qq.com/s/JIvbYapMMtC8JkBEXHsG-A
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/9l1Uupthv9zBqvo5v_N94g
2.AWS Kiro 最懂程序员的IDE - SPEC模式初体验,稳得出人意料!
https://www.bilibili.com/video/BV18vgwzYEri/
3.Chunked-Prefills 分块预填充机制详解
https://mp.weixin.qq.com/s/JIvbYapMMtC8JkBEXHsG-A
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2076期 (2025-07-16)
https://mp.weixin.qq.com/s/fC3iNOSWlSnofRM804RYOQ
2.森马服饰从 Elasticsearch 到阿里云 SelectDB 的架构演进之路
https://zhuanlan.zhihu.com/p/1927036355139045220
3.RAG 的最佳 PDF 提取器是什么?(搭梯)
https://levelup.gitconnected.c ... b06e0
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/fC3iNOSWlSnofRM804RYOQ
2.森马服饰从 Elasticsearch 到阿里云 SelectDB 的架构演进之路
https://zhuanlan.zhihu.com/p/1927036355139045220
3.RAG 的最佳 PDF 提取器是什么?(搭梯)
https://levelup.gitconnected.c ... b06e0
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2075期 (2025-07-15)
https://medium.com/%40imadsadd ... 90485
2. 10亿记录一秒返回,干就完了(需要梯子)
https://medium.com/%40ApacheDo ... e3a12
3. 我在Trendyol我们是这样用ES做聚合的(需要梯子)
https://medium.com/trendyol-te ... 1c4b2
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40imadsadd ... 90485
2. 10亿记录一秒返回,干就完了(需要梯子)
https://medium.com/%40ApacheDo ... e3a12
3. 我在Trendyol我们是这样用ES做聚合的(需要梯子)
https://medium.com/trendyol-te ... 1c4b2
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
TDBC 2025 可信数据库发展大会,极限科技邀您来赴约!

2025 年 7 月 16-17 日,「TDBC 2025 可信数据库发展大会」将在北京朝阳悠唐皇冠假日酒店隆重召开。大会由中国通信标准化协会主办,中国信息通信研究院、中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)承办。
本次大会 极限科技 再度受邀,创始人兼总经理曾勇、联合创始人曾嘉毅 将分别于「人工智能与数据库融合发展分论坛」、「数据库生态及国际化分论坛」发表主题演讲,与大家共同探讨 AI 与企业搜索融合发展的技术突破和应用实践,以及企业搜索的发展新方向与海外市场开拓。与此同时我们也特设 展台(展位号 B09) 和大家线下相见!
演讲主题一:《重构信息获取方式:下一代企业搜索与 AI 的融合探索》

演讲主题二:《搜索型数据库生态建设和展望》

展位福利
除了精彩演讲,极限科技专家团队将于 B09 (记住展位号,不迷路!)与大家近距离交流。大家可以深入了解搜索型数据库与 AI 搜索的产品技术、行业解决方案,并与技术专家一对一探讨实际业务场景中的搜索应用问题。
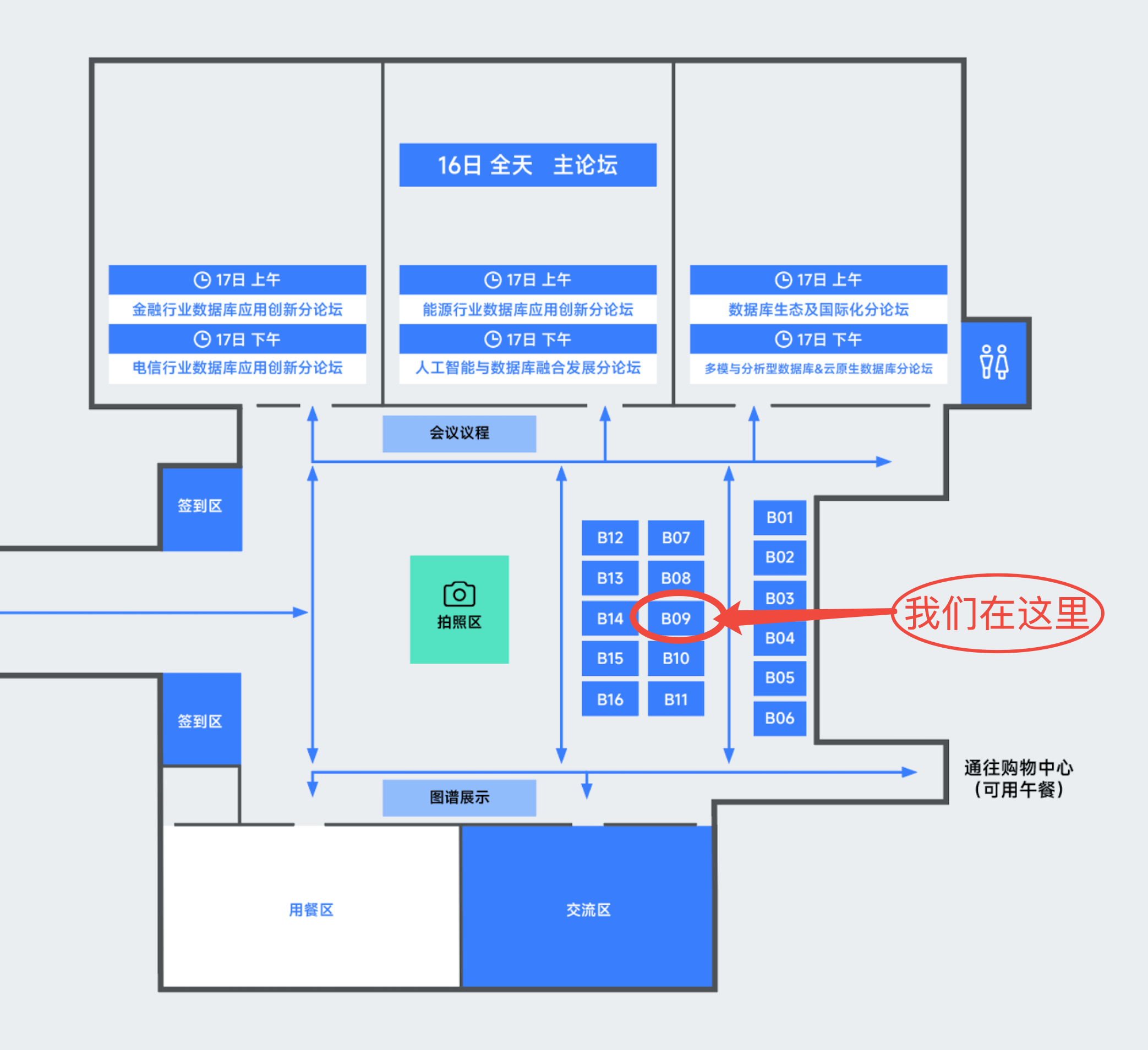
此外,我们还精心准备了多款 INFINI Labs 定制周边礼品,只要来到展位参与互动就有机会获得,真诚欢迎各位新老朋友前来 B09 展位打卡交流!
大会议程
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
2025 年 7 月 16-17 日,「TDBC 2025 可信数据库发展大会」将在北京朝阳悠唐皇冠假日酒店隆重召开。大会由中国通信标准化协会主办,中国信息通信研究院、中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)承办。
本次大会 极限科技 再度受邀,创始人兼总经理曾勇、联合创始人曾嘉毅 将分别于「人工智能与数据库融合发展分论坛」、「数据库生态及国际化分论坛」发表主题演讲,与大家共同探讨 AI 与企业搜索融合发展的技术突破和应用实践,以及企业搜索的发展新方向与海外市场开拓。与此同时我们也特设 展台(展位号 B09) 和大家线下相见!
演讲主题一:《重构信息获取方式:下一代企业搜索与 AI 的融合探索》
演讲主题二:《搜索型数据库生态建设和展望》
展位福利
除了精彩演讲,极限科技专家团队将于 B09 (记住展位号,不迷路!)与大家近距离交流。大家可以深入了解搜索型数据库与 AI 搜索的产品技术、行业解决方案,并与技术专家一对一探讨实际业务场景中的搜索应用问题。
此外,我们还精心准备了多款 INFINI Labs 定制周边礼品,只要来到展位参与互动就有机会获得,真诚欢迎各位新老朋友前来 B09 展位打卡交流!
大会议程
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第2074期 (2025-07-14)
https://elasticstack.blog.csdn ... 73363
2、使用 Maximum Marginal Relevance 实现搜索结果多样化
https://elasticstack.blog.csdn ... 69341
3、上下文更长 ≠ 更好:为什么 RAG 仍然重要
https://elasticstack.blog.csdn ... 88509
4、Logstash 9.x 与早期版本差异及常见问题解决方案
https://mp.weixin.qq.com/s/08dzlC5wKsfi_5JkaSN26Q
5、ChatBI:让数据分析像聊天一样简单!
https://mp.weixin.qq.com/s/W8sEEIphNE7ot5T2oY5qVA
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 73363
2、使用 Maximum Marginal Relevance 实现搜索结果多样化
https://elasticstack.blog.csdn ... 69341
3、上下文更长 ≠ 更好:为什么 RAG 仍然重要
https://elasticstack.blog.csdn ... 88509
4、Logstash 9.x 与早期版本差异及常见问题解决方案
https://mp.weixin.qq.com/s/08dzlC5wKsfi_5JkaSN26Q
5、ChatBI:让数据分析像聊天一样简单!
https://mp.weixin.qq.com/s/W8sEEIphNE7ot5T2oY5qVA
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »

