

【搜索客社区日报】第2062期 (2025-06-25)
https://blog.csdn.net/UbuntuTo ... 53095
2.利用智能系统构建自演化知识图谱(搭梯)
https://medium.com/%40communit ... 3592c
3.三个数据处理技巧,永远改变你的es搜索体验
https://cloud.tencent.com/deve ... 32219
4.利用 Elastic 优化大模型的的成本和内容审核
https://cloud.tencent.com/deve ... 22292
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 53095
2.利用智能系统构建自演化知识图谱(搭梯)
https://medium.com/%40communit ... 3592c
3.三个数据处理技巧,永远改变你的es搜索体验
https://cloud.tencent.com/deve ... 32219
4.利用 Elastic 优化大模型的的成本和内容审核
https://cloud.tencent.com/deve ... 22292
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2061期 (2025-06-24)
https://medium.com/%40oredata- ... a065c
2. ES/CK/doris 谁才是你可观测的最终选择(需要梯子)
https://medium.com/%40ApacheDo ... d2176
3. 采集k8s集群日志实战(需要梯子)
https://medium.com/%40kikuchid ... 77928
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40oredata- ... a065c
2. ES/CK/doris 谁才是你可观测的最终选择(需要梯子)
https://medium.com/%40ApacheDo ... d2176
3. 采集k8s集群日志实战(需要梯子)
https://medium.com/%40kikuchid ... 77928
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2060期 (2025-06-23)
https://infinilabs.cn/blog/202 ... cker/
2、使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建
https://infinilabs.cn/blog/202 ... pose/
3、上线3周:告警减少70%!AI巡检分级报告实战(一)
https://mp.weixin.qq.com/s/3s0Tvw8q5y6IpDNl3Y_7VA
4、开源: 和您的SQL聊聊天,自然语言SQL数据库查询系统
https://mp.weixin.qq.com/s/cfJ9jCQTc2zQPTav1tlyOA
5、为什么在 Kibana 中分配自定义数据视图 ID 很重要
https://mp.weixin.qq.com/s/USARC_EUXk_t-vrOCJDMxg
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... cker/
2、使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建
https://infinilabs.cn/blog/202 ... pose/
3、上线3周:告警减少70%!AI巡检分级报告实战(一)
https://mp.weixin.qq.com/s/3s0Tvw8q5y6IpDNl3Y_7VA
4、开源: 和您的SQL聊聊天,自然语言SQL数据库查询系统
https://mp.weixin.qq.com/s/cfJ9jCQTc2zQPTav1tlyOA
5、为什么在 Kibana 中分配自定义数据视图 ID 很重要
https://mp.weixin.qq.com/s/USARC_EUXk_t-vrOCJDMxg
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2059期 (2025-06-20)
https://mp.weixin.qq.com/s/fYISSlm1eRQW5p20PKJuMA
2、向量数据库--基于图的近似最近邻搜索
https://mp.weixin.qq.com/s/vDIwUq7xYG_d3KolI6Nhig
3、搭建持久化的 INFINI Console 与 Easysearch 容器环境
https://infinilabs.cn/blog/202 ... cker/
4、百度垂搜数据管理系统弹性调度优化实践
https://my.oschina.net/u/4939618/blog/18627327
5、私有知识库 Coco AI 实战(二):摄入 MongoDB 数据
https://infinilabs.cn/blog/202 ... on-2/
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/fYISSlm1eRQW5p20PKJuMA
2、向量数据库--基于图的近似最近邻搜索
https://mp.weixin.qq.com/s/vDIwUq7xYG_d3KolI6Nhig
3、搭建持久化的 INFINI Console 与 Easysearch 容器环境
https://infinilabs.cn/blog/202 ... cker/
4、百度垂搜数据管理系统弹性调度优化实践
https://my.oschina.net/u/4939618/blog/18627327
5、私有知识库 Coco AI 实战(二):摄入 MongoDB 数据
https://infinilabs.cn/blog/202 ... on-2/
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2058期 (2025-06-19)
https://mp.weixin.qq.com/s/C1wv_54hOnh3Q5yoq2NXSg
2.数据库老司机勇闯现代前端大观园
https://mp.weixin.qq.com/s/51dKs7wR6WCNiNWX5j_gWg
3.使用 Higress AI 网关代理 vLLM 推理服务
https://mp.weixin.qq.com/s/DsJ4aY1K6mEnwR_Ms8QvMA
4.AI Infra 和传统 Infra 断代了吗?聊聊 Infra “三大难题”,以及其中的关联
https://mp.weixin.qq.com/s/o8snj-WUbhfY1kcdPDHnPg
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/C1wv_54hOnh3Q5yoq2NXSg
2.数据库老司机勇闯现代前端大观园
https://mp.weixin.qq.com/s/51dKs7wR6WCNiNWX5j_gWg
3.使用 Higress AI 网关代理 vLLM 推理服务
https://mp.weixin.qq.com/s/DsJ4aY1K6mEnwR_Ms8QvMA
4.AI Infra 和传统 Infra 断代了吗?聊聊 Infra “三大难题”,以及其中的关联
https://mp.weixin.qq.com/s/o8snj-WUbhfY1kcdPDHnPg
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2057期 (2025-06-18)
https://mp.weixin.qq.com/s/ykExR8uTBW74Z6xBv1c3LA
2.向 AI Search 迈进,腾讯云 ES 自研 v-pack 向量增强插件揭秘
https://blog.csdn.net/UbuntuTo ... 92893
3.MCP(Model Context Protocol,模型上下文协议)的当前状态
https://blog.csdn.net/UbuntuTo ... 23169
4.Elasticsearch 合成原字段:Synthetic _source
https://blog.csdn.net/UbuntuTo ... 18147
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/ykExR8uTBW74Z6xBv1c3LA
2.向 AI Search 迈进,腾讯云 ES 自研 v-pack 向量增强插件揭秘
https://blog.csdn.net/UbuntuTo ... 92893
3.MCP(Model Context Protocol,模型上下文协议)的当前状态
https://blog.csdn.net/UbuntuTo ... 23169
4.Elasticsearch 合成原字段:Synthetic _source
https://blog.csdn.net/UbuntuTo ... 18147
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
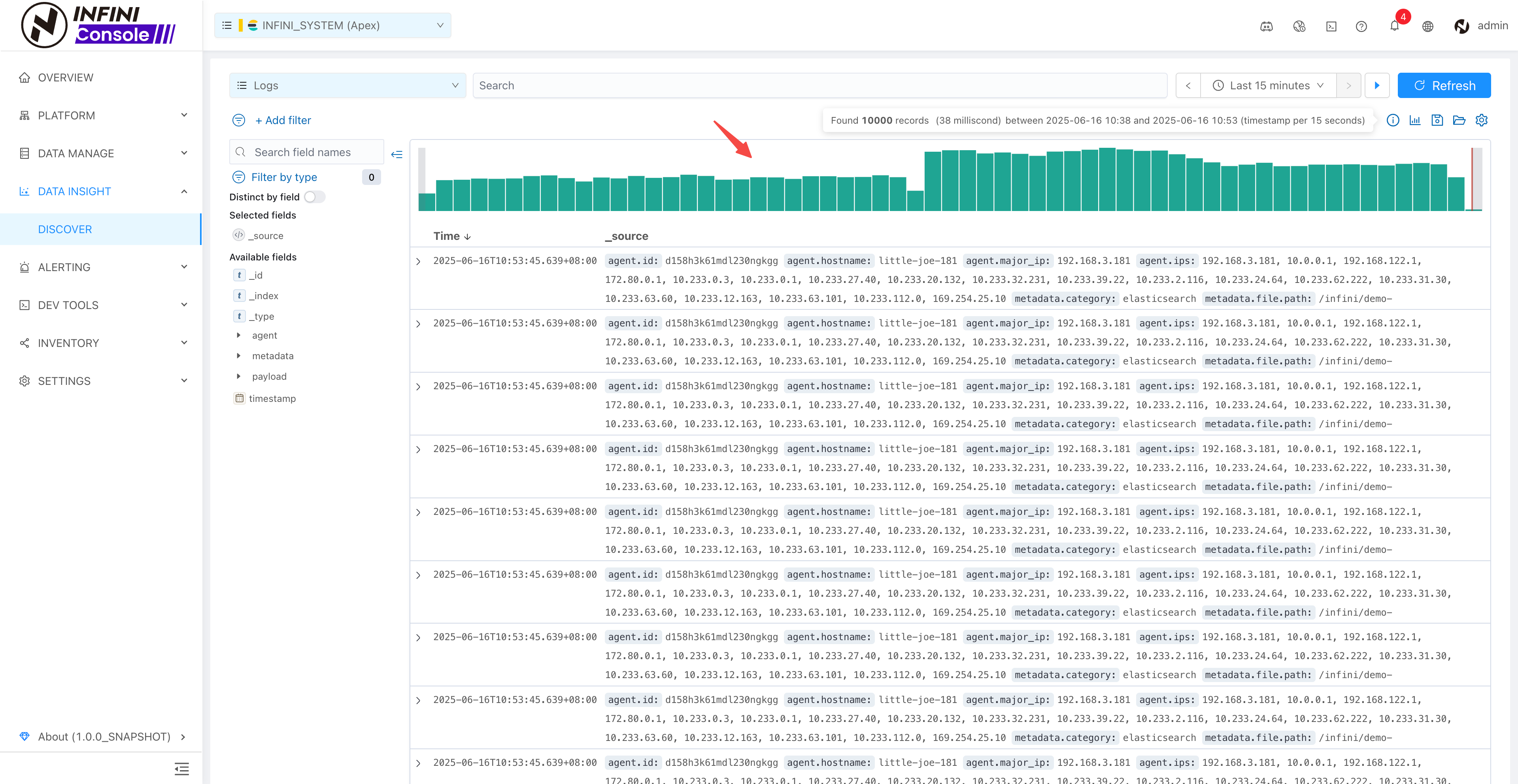
INFINI Labs 产品更新 | Easysearch 1.13.0 、Console 1.29.6 发布 – 优化监控图表异常毛刺等

INFINI Labs 产品更新发布!此次更新涵盖 Console 、Easysearch 等产品多项重要升级,重点优化监控图表异常毛刺。
- INFINI Easysearch v1.13.0 Rollup Job 支持自动更新操作索引 mapping 更新, 未完成 rollup 的源索引禁止被 ilm 进行清理。
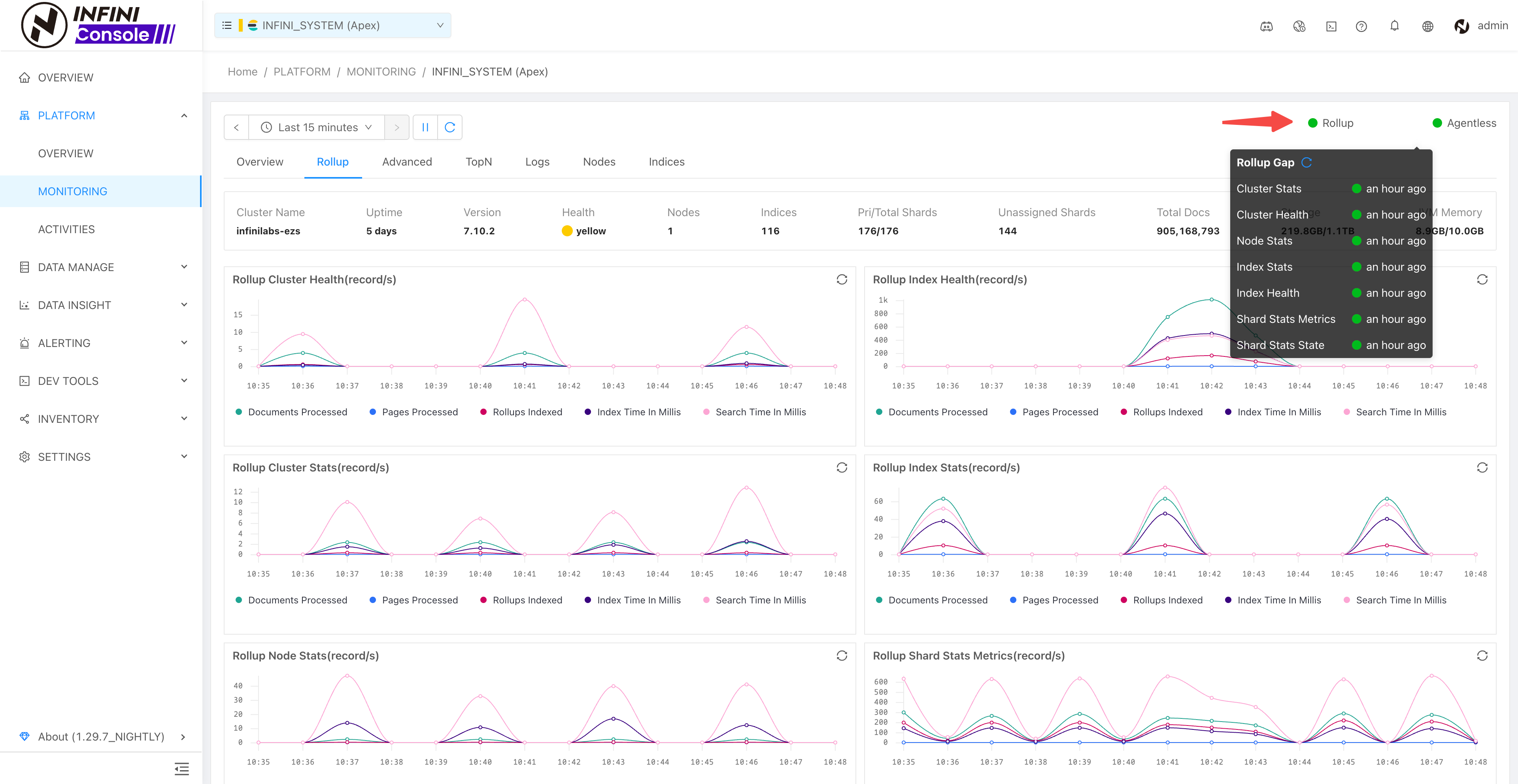
- INFINI Console v1.29.6 系统集群新增 Rollup Gap 指标,修复监控图表异常毛刺、历史数据 top 索引查询指标异常等问题。
INFINI Easysearch v1.13.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
- Rollup 新增对已创建 job 的 interval 和 page_size 参数更新的 api
- Rollup 索引数据增加 unique 字段标识当前 job 的数据
- Rollup 配置增加 window_start_time 字段,当重建 Rollup 时 会把历史 metadata 的最新时间戳写到 window_start_time 里
问题修复
优化改进
- Rollup 会自动检测源数据索引是否有新增字段,并更新到 metrics
- ILM 删除索引时 增加对 Rollup 的运行状态判断,未处理完的索引不会删除
INFINI Console v1.29.6
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验:
http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
功能更新
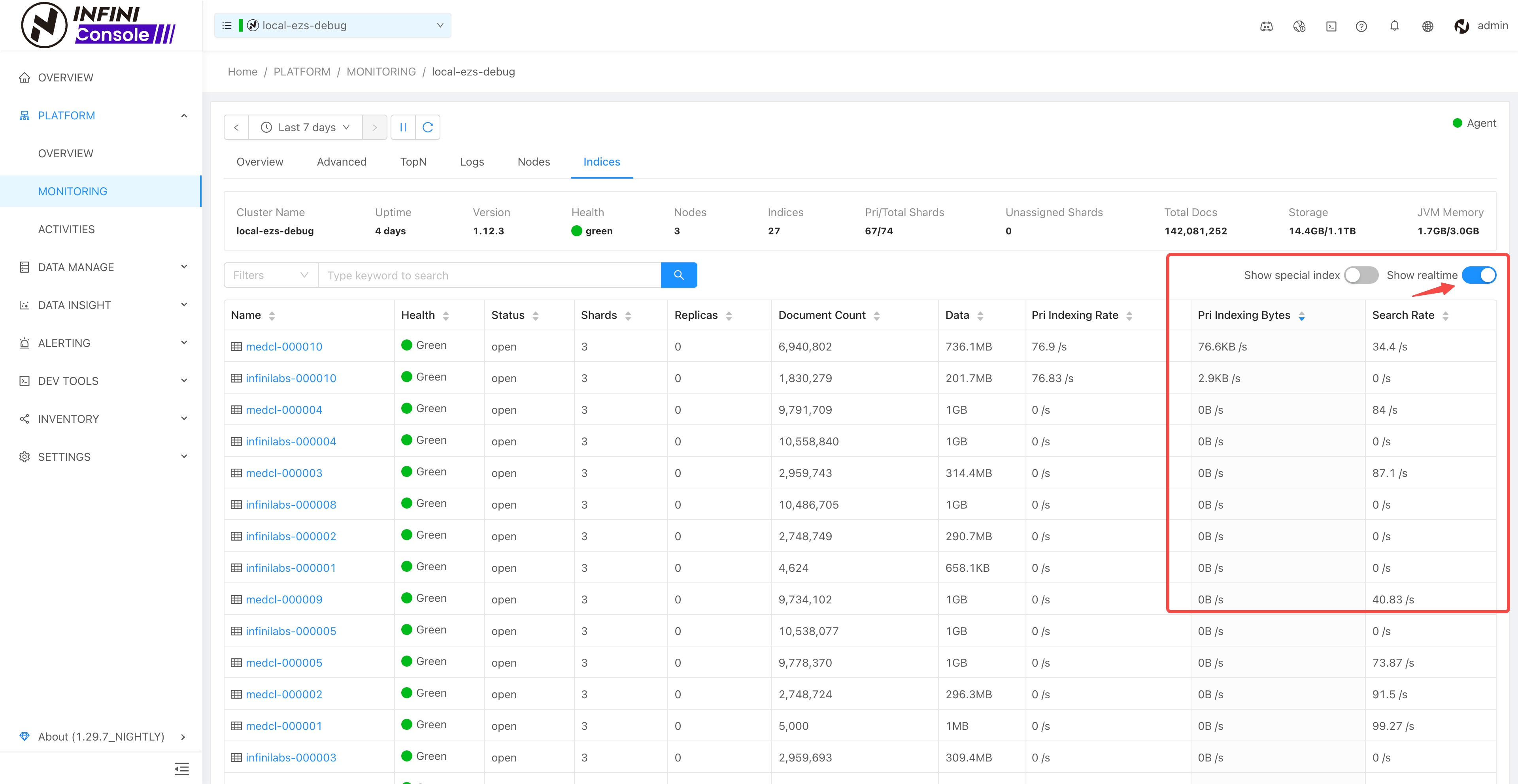
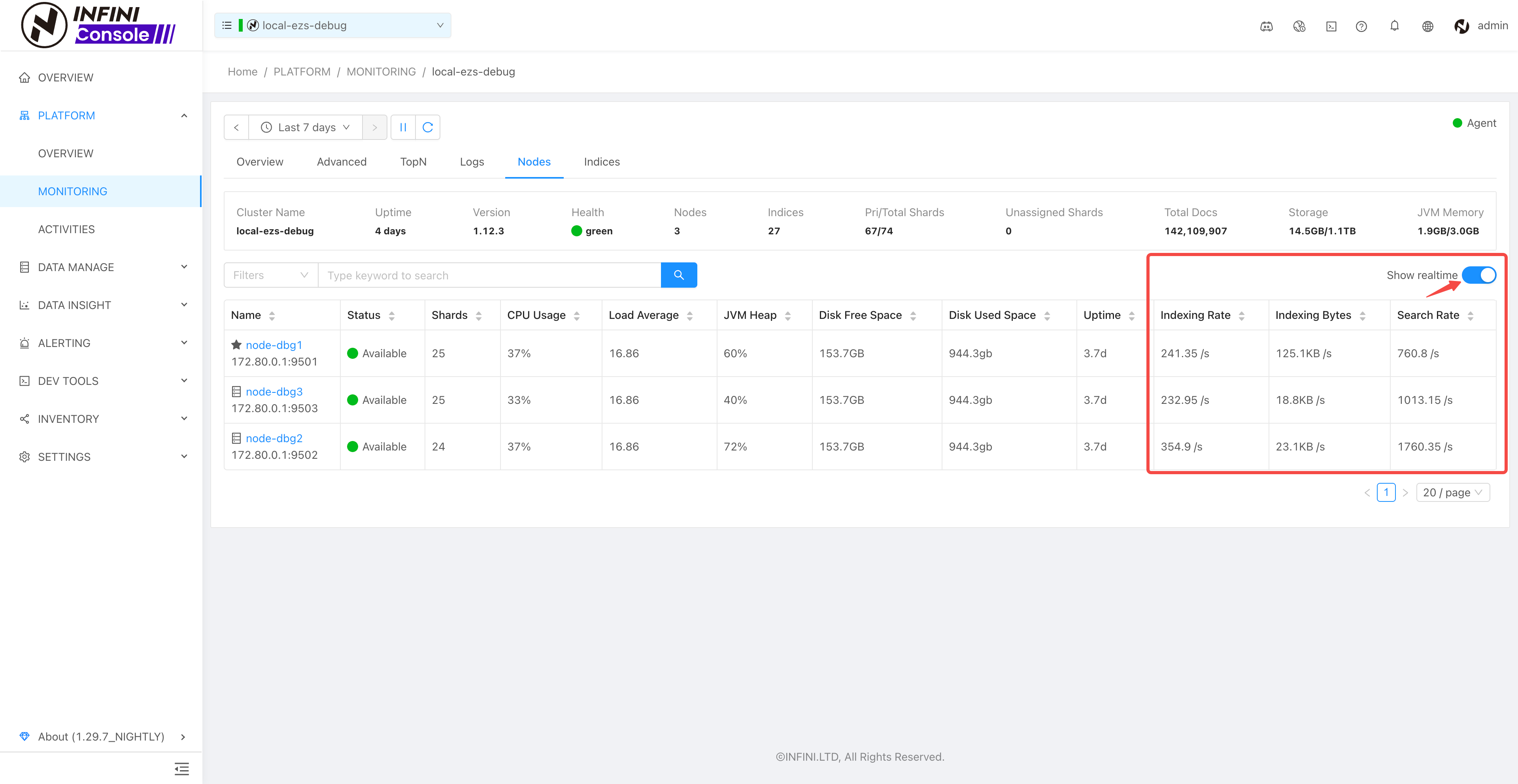
- 集群设置切换指标采集模式时增加确认操作
- 系统集群增加 Rollup 监控指标
- 监控页面支持查看 Rollup 处理进度
问题修复
- 修复告警详情页面查询事件记录时时间范围错误的问题
- 修复高级页面中索引 top 查询异常问题
优化改进
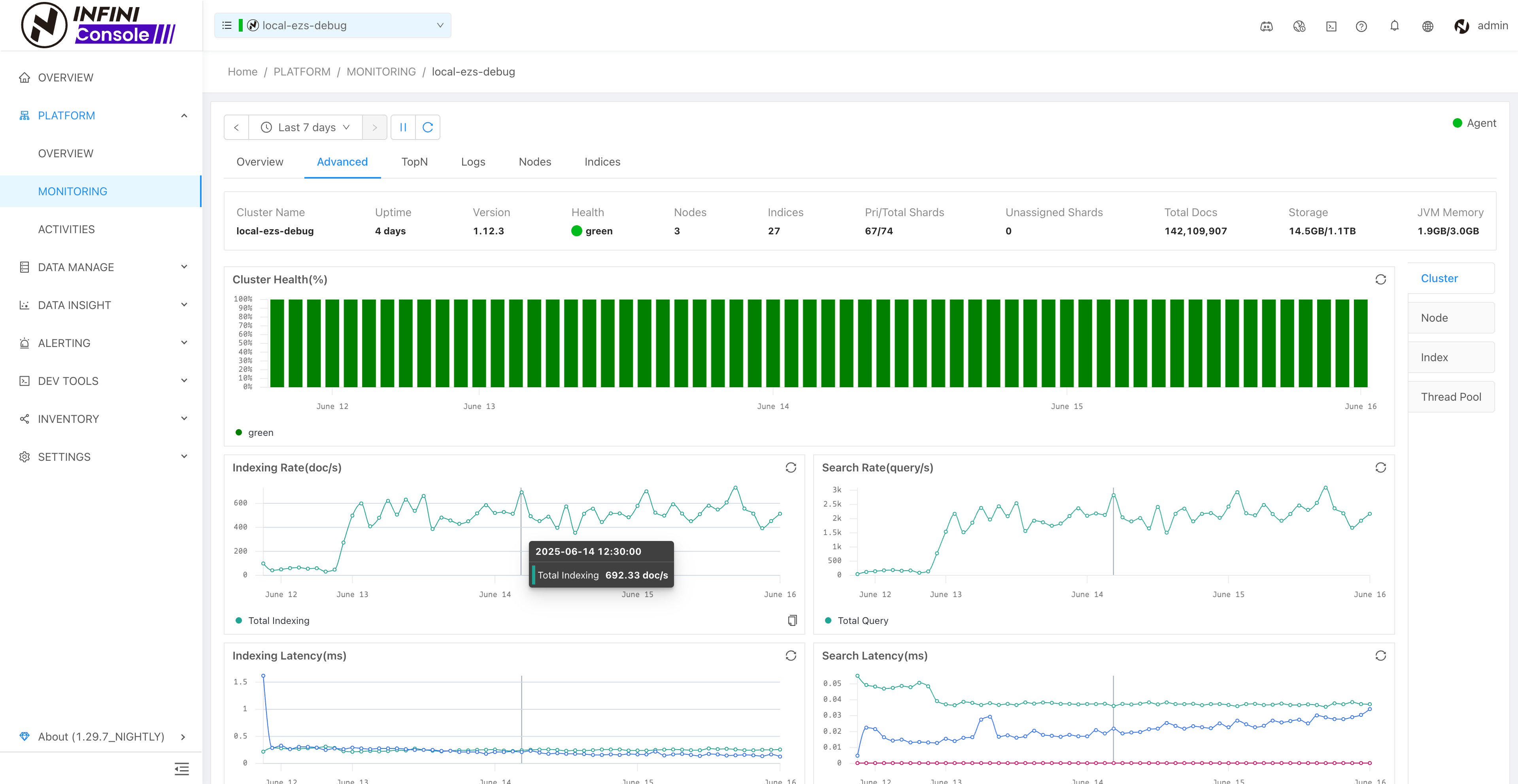
- 增强指标聚合功能
- 更新查询和过滤功能以支持范围
- 优化桶大小计算
- 数据探索默认展示图表
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新发布!此次更新涵盖 Console 、Easysearch 等产品多项重要升级,重点优化监控图表异常毛刺。
- INFINI Easysearch v1.13.0 Rollup Job 支持自动更新操作索引 mapping 更新, 未完成 rollup 的源索引禁止被 ilm 进行清理。
- INFINI Console v1.29.6 系统集群新增 Rollup Gap 指标,修复监控图表异常毛刺、历史数据 top 索引查询指标异常等问题。
INFINI Easysearch v1.13.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
- Rollup 新增对已创建 job 的 interval 和 page_size 参数更新的 api
- Rollup 索引数据增加 unique 字段标识当前 job 的数据
- Rollup 配置增加 window_start_time 字段,当重建 Rollup 时 会把历史 metadata 的最新时间戳写到 window_start_time 里
问题修复
优化改进
- Rollup 会自动检测源数据索引是否有新增字段,并更新到 metrics
- ILM 删除索引时 增加对 Rollup 的运行状态判断,未处理完的索引不会删除
INFINI Console v1.29.6
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验:
http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
功能更新
- 集群设置切换指标采集模式时增加确认操作
- 系统集群增加 Rollup 监控指标
- 监控页面支持查看 Rollup 处理进度
问题修复
- 修复告警详情页面查询事件记录时时间范围错误的问题
- 修复高级页面中索引 top 查询异常问题
优化改进
- 增强指标聚合功能
- 更新查询和过滤功能以支持范围
- 优化桶大小计算
- 数据探索默认展示图表
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »INFINI Labs 产品更新 | Coco AI 0.5 发布 – 无缝集成 AI 搜索能力、支持插件扩展、支持快照版本更新等
INFINI Labs 产品更新发布!此次更新涵盖 Coco AI 产品多项重要升级,重点提升 AI 搜索能力、易用性及企业级优化。
- Coco AI v0.5 无缝集成 AI 搜索能力,支持第三方插件,新增 AI Command 快速访问 AI 能力,支持快照版本更新,优化交互细节,提升整体稳定性与用户体验等。
- Coco AI Server v0.5 强化 API 能力与安全性,完善小助手配置,支持多用户登录。
Coco AI v0.5
Coco AI 是一个完全开源、跨平台的统一 AI 搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.5
功能更新
- 搜索模式支持快速 AI 访问
- 支持插件扩展
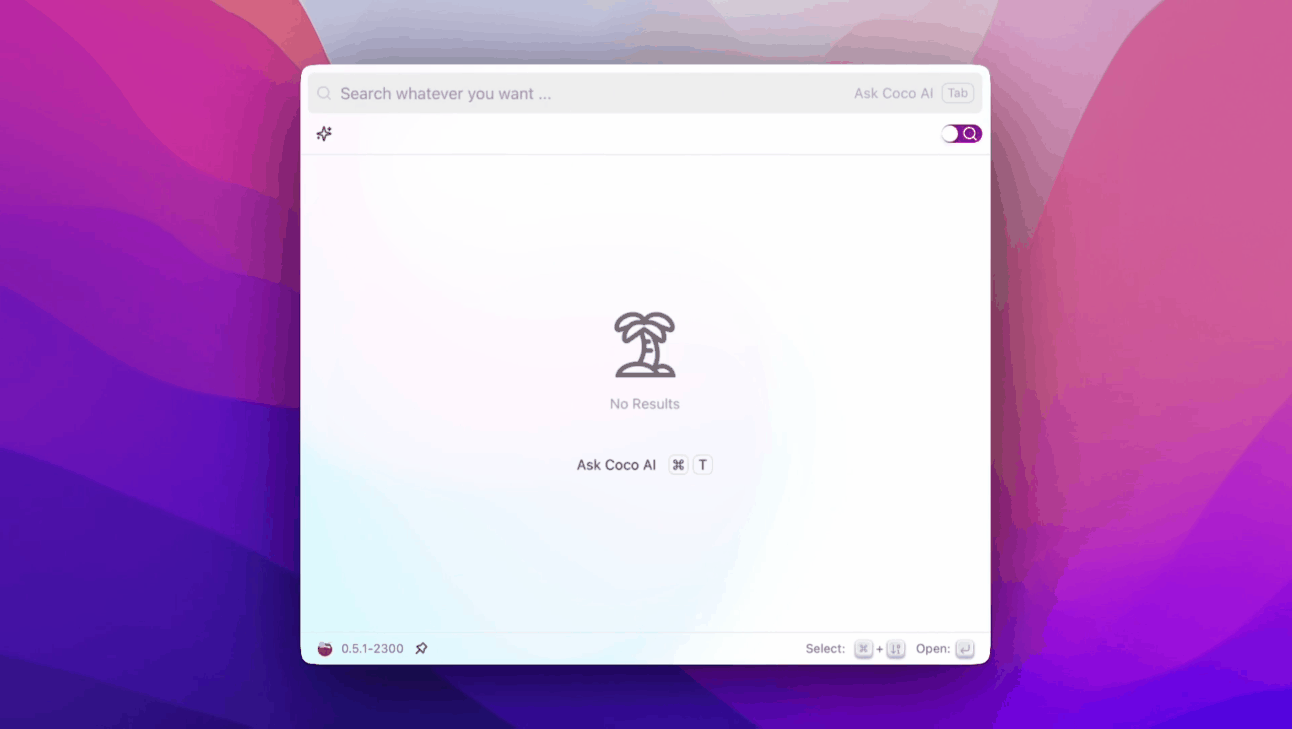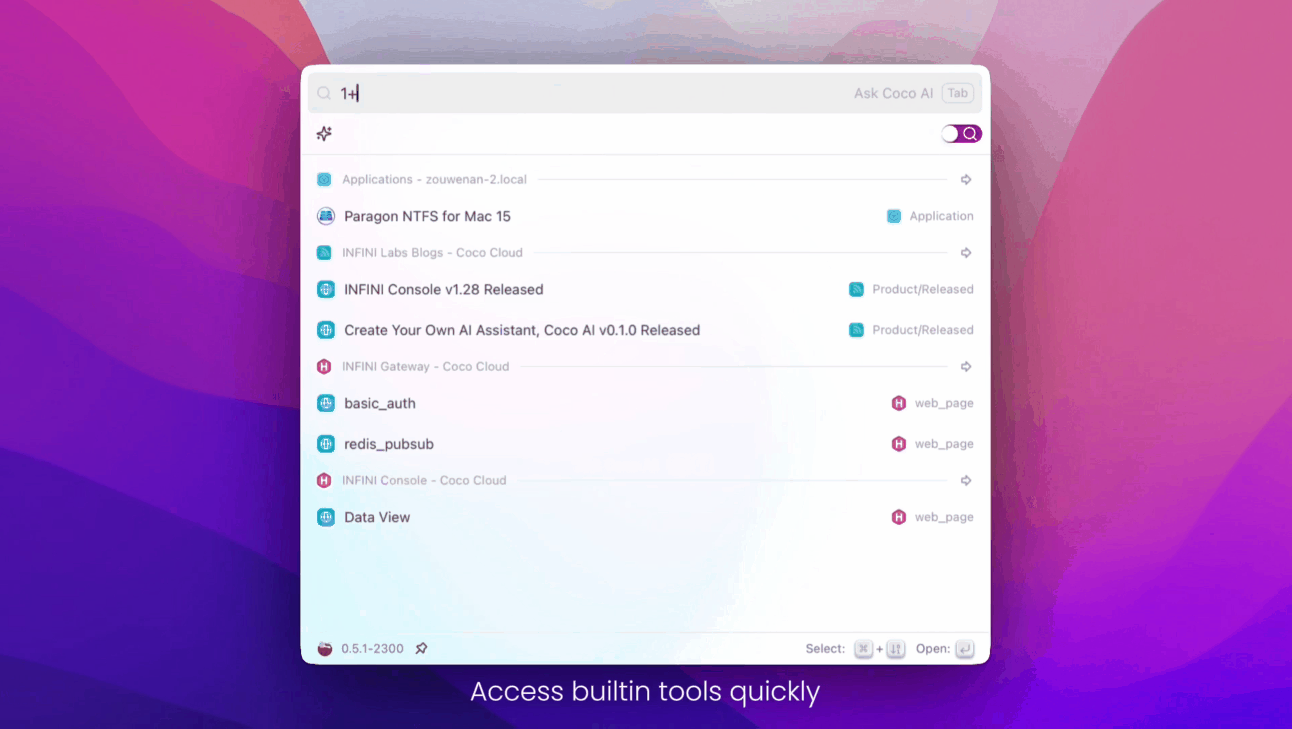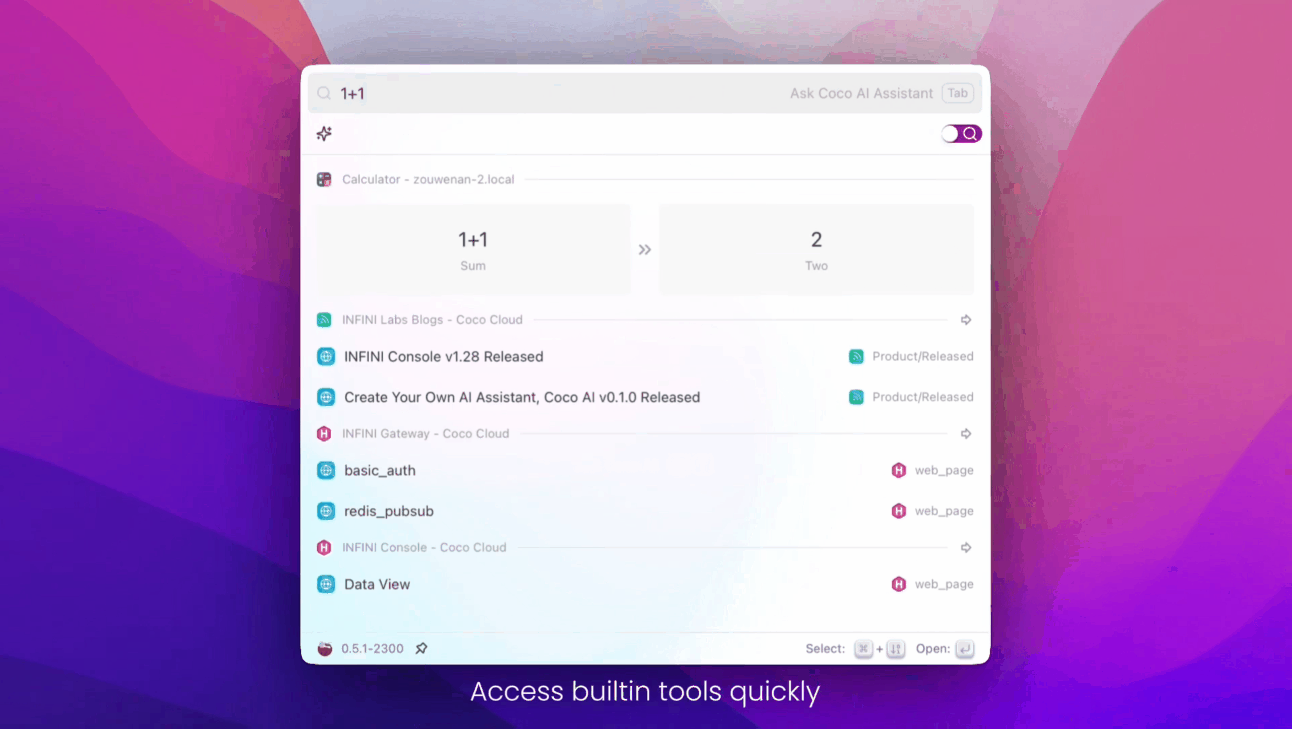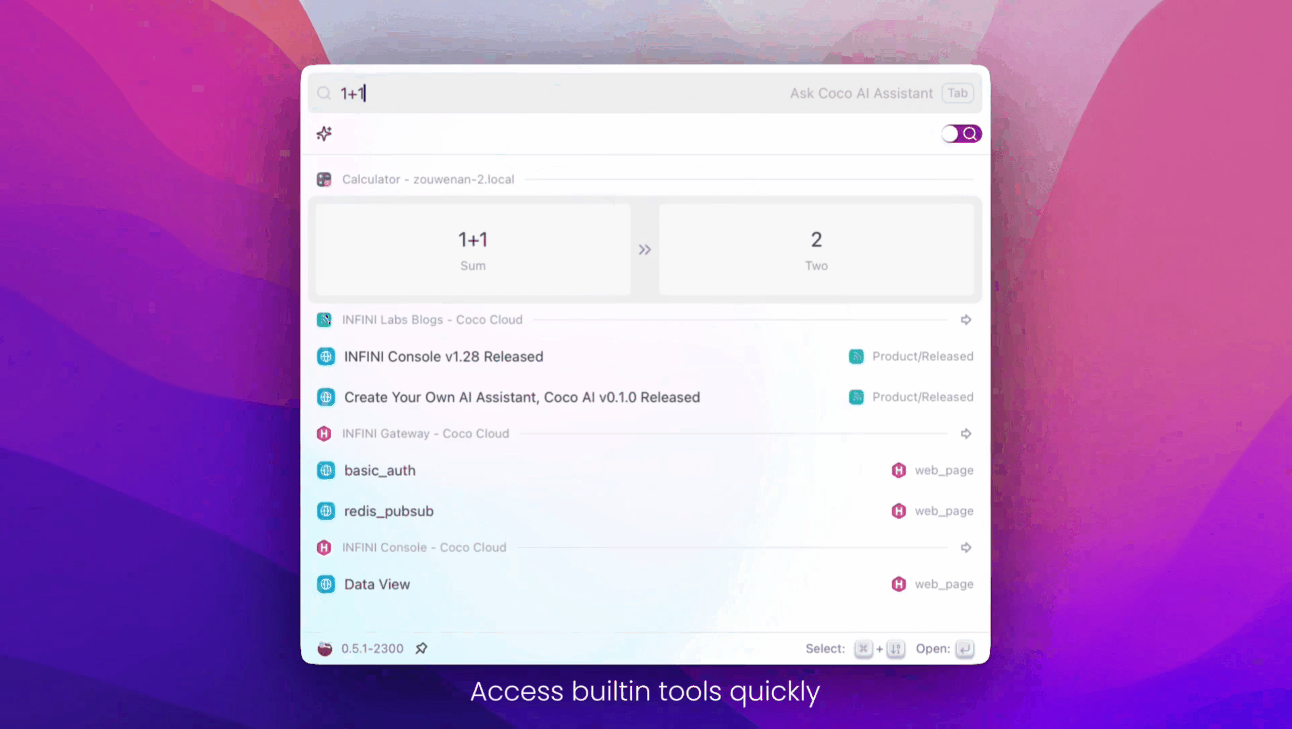
- 添加 AI 摘要组件
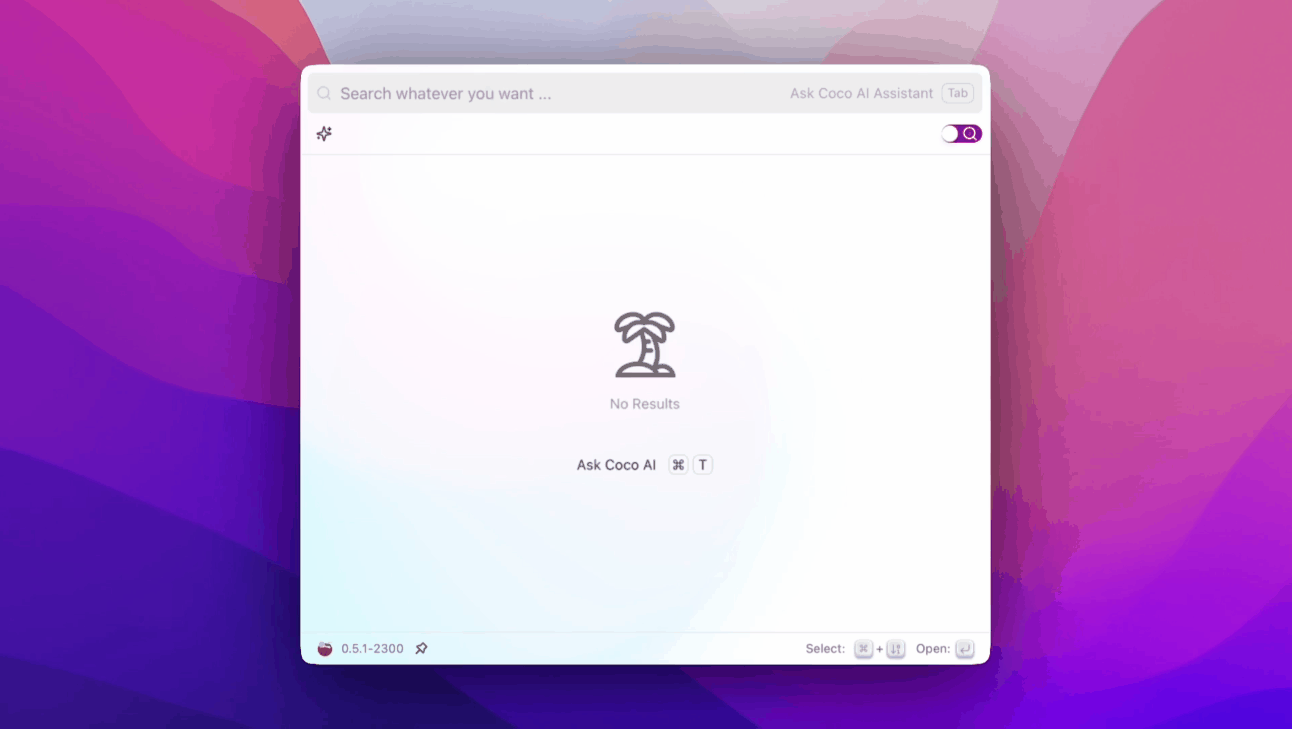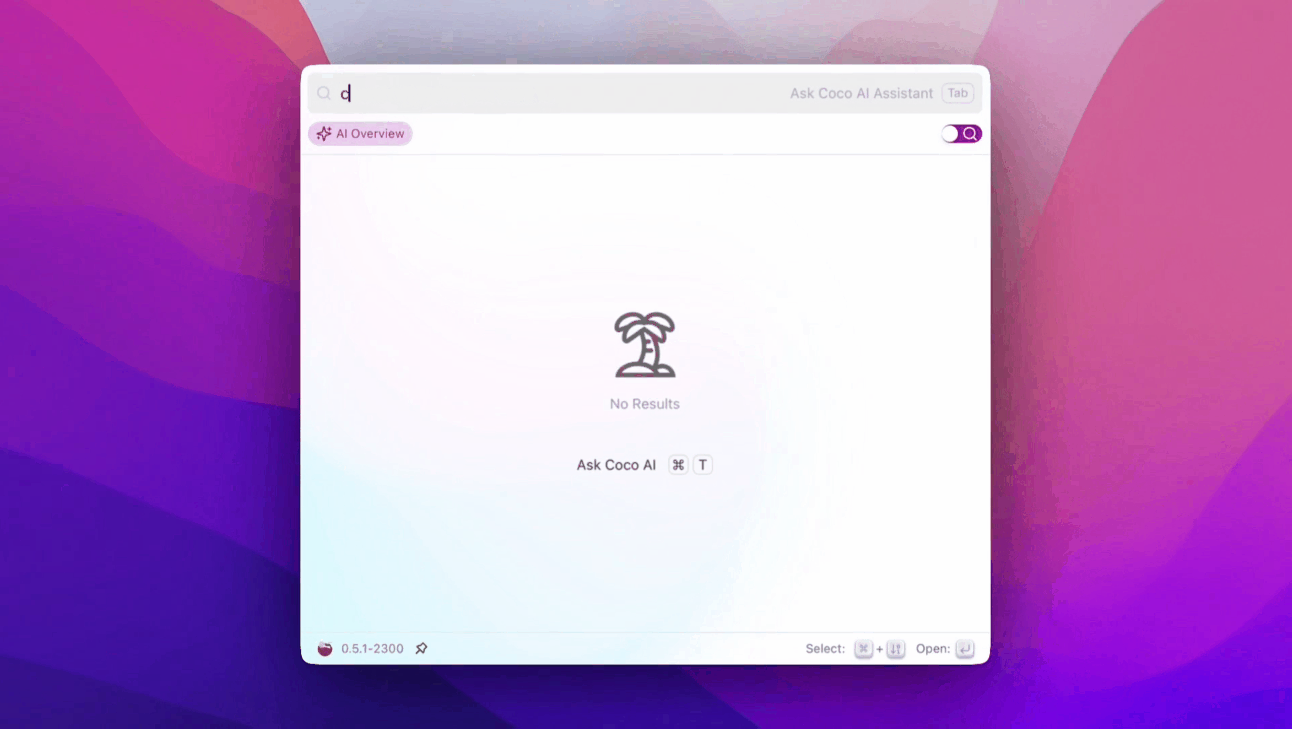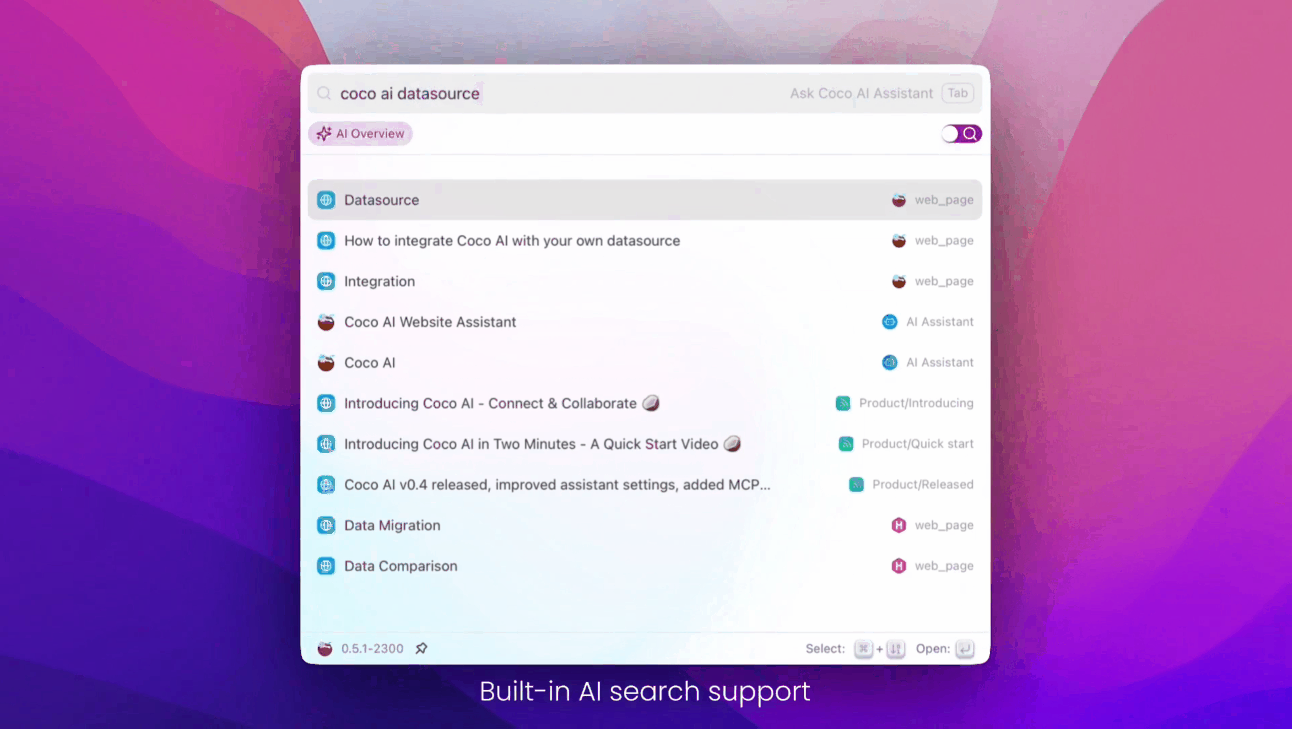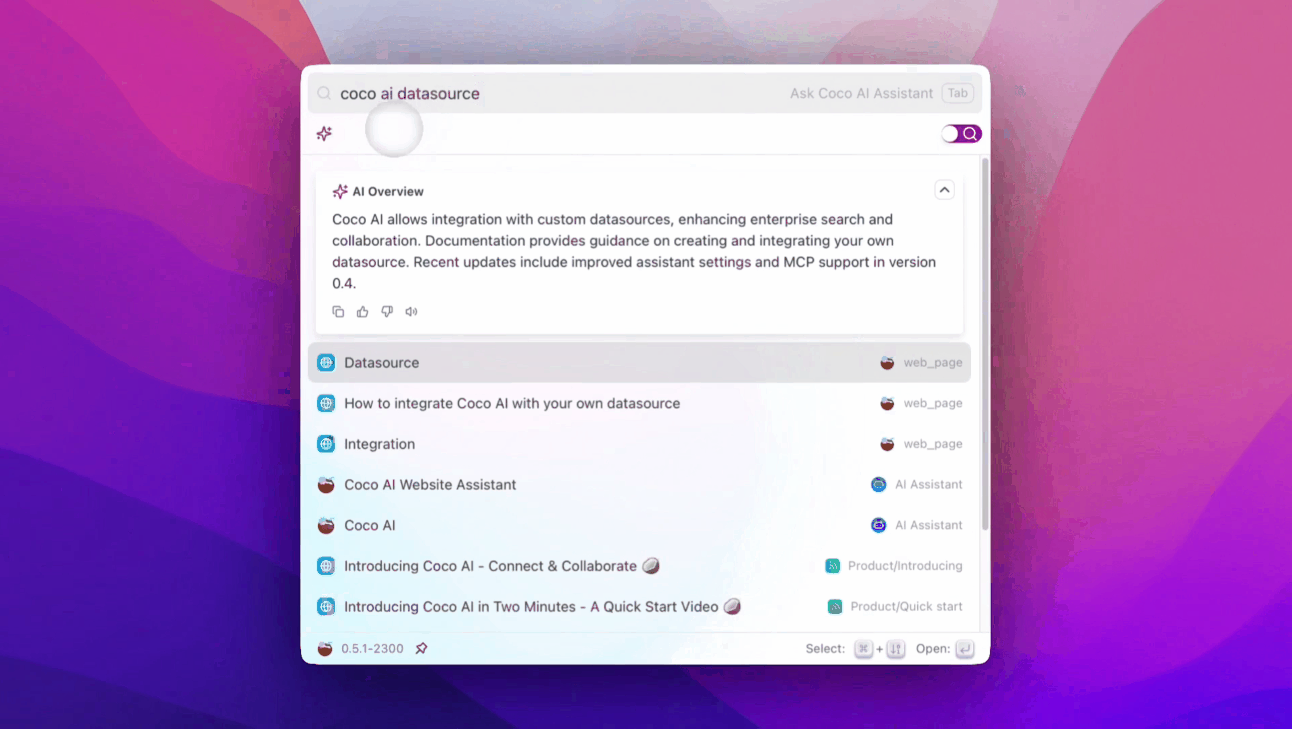
- 支持搜索二级页面
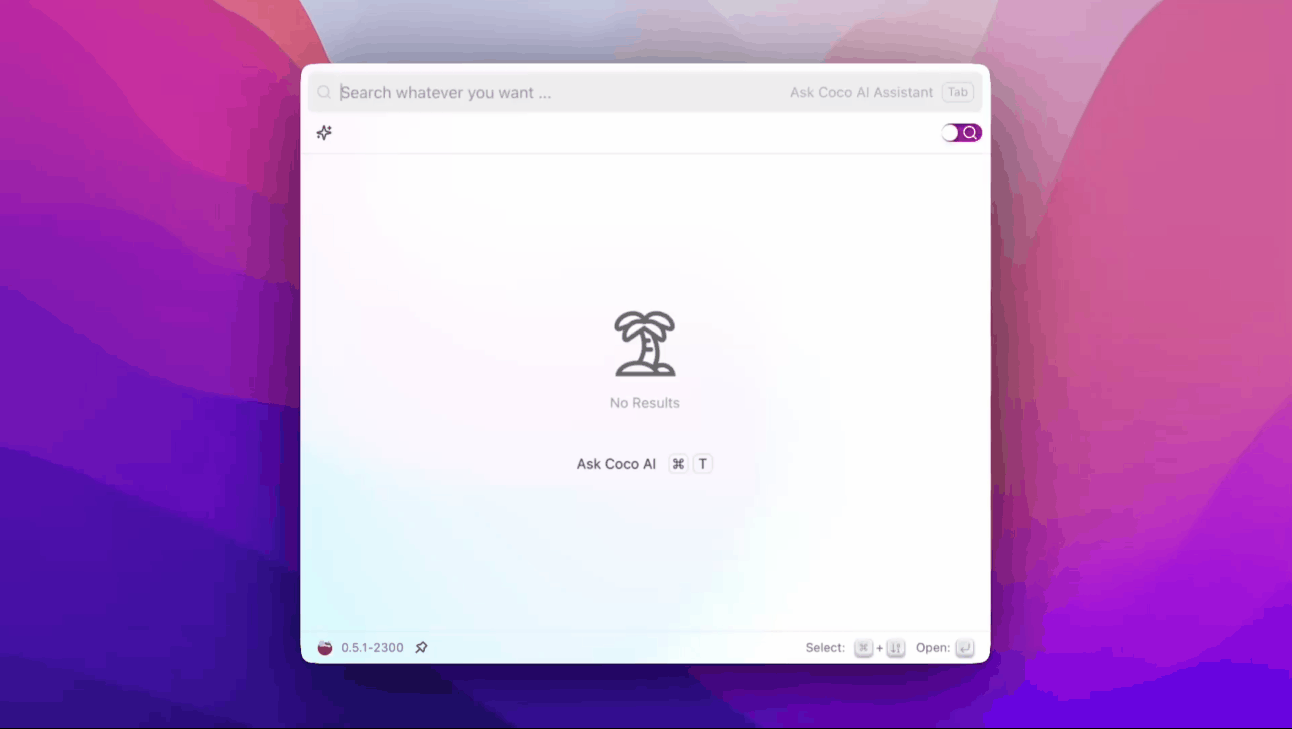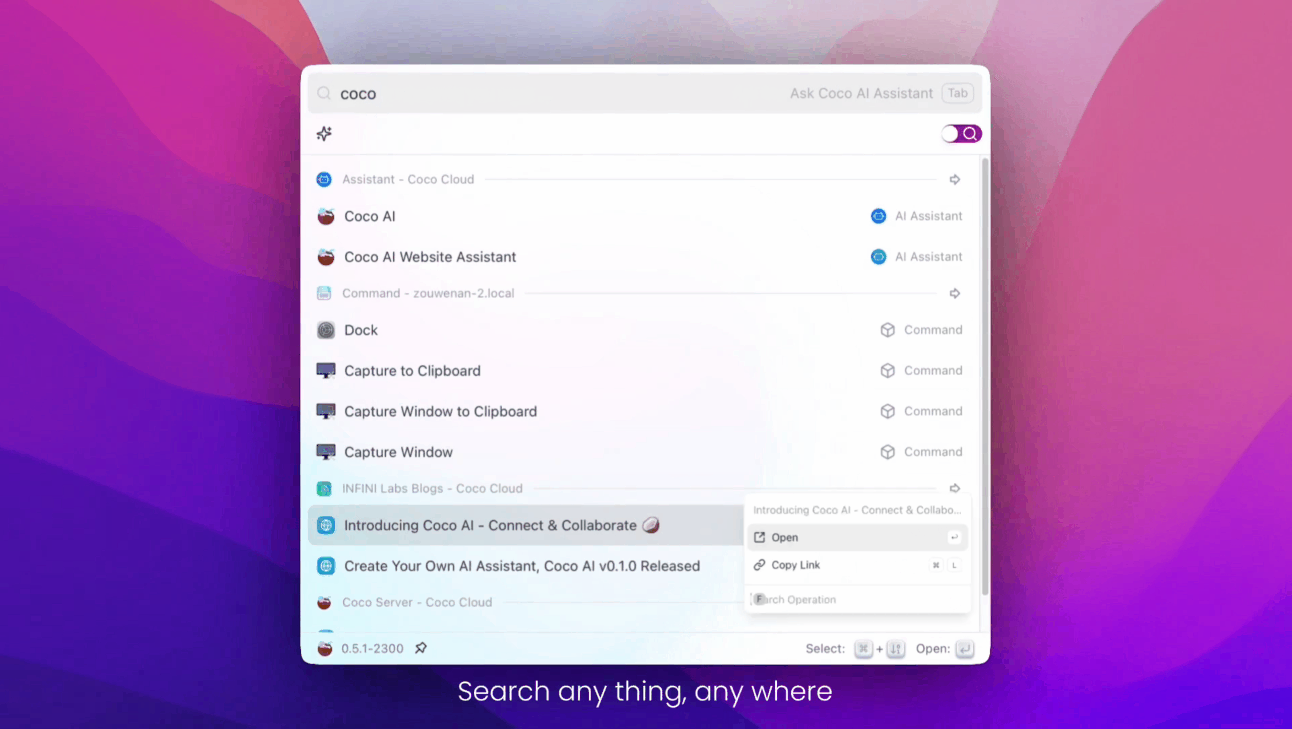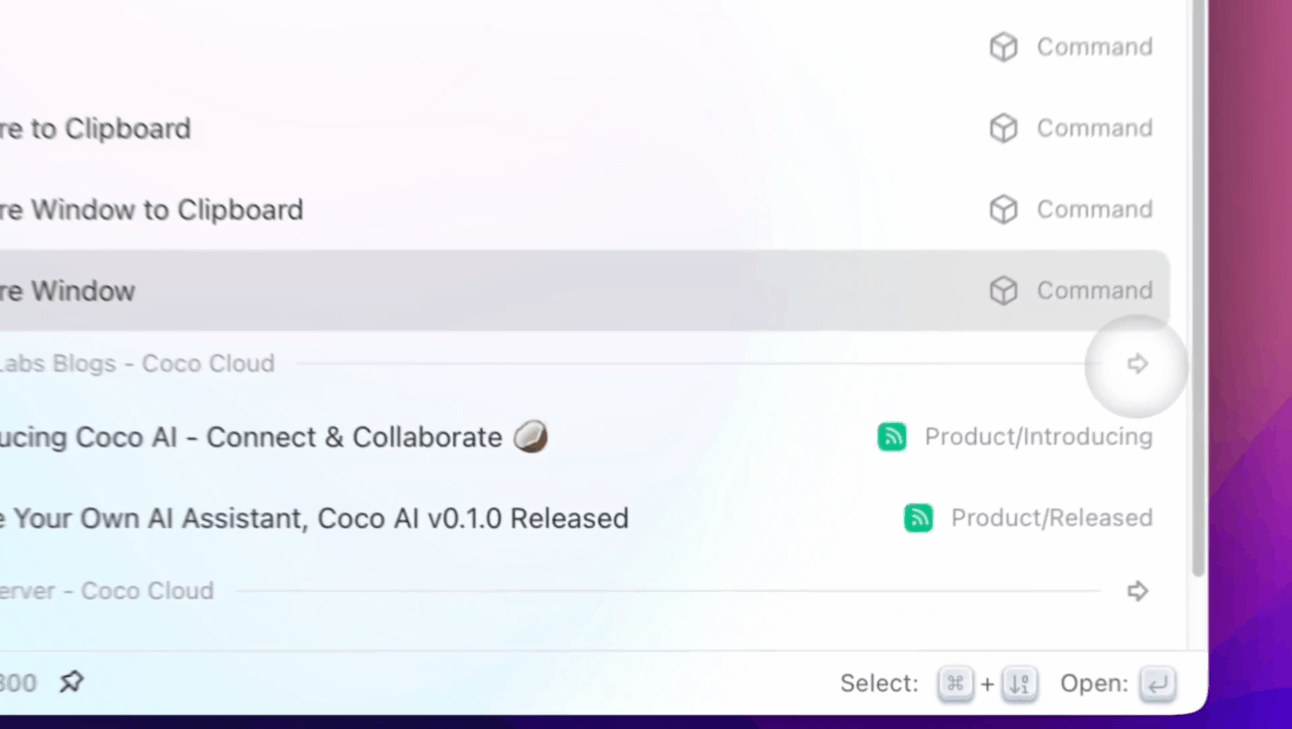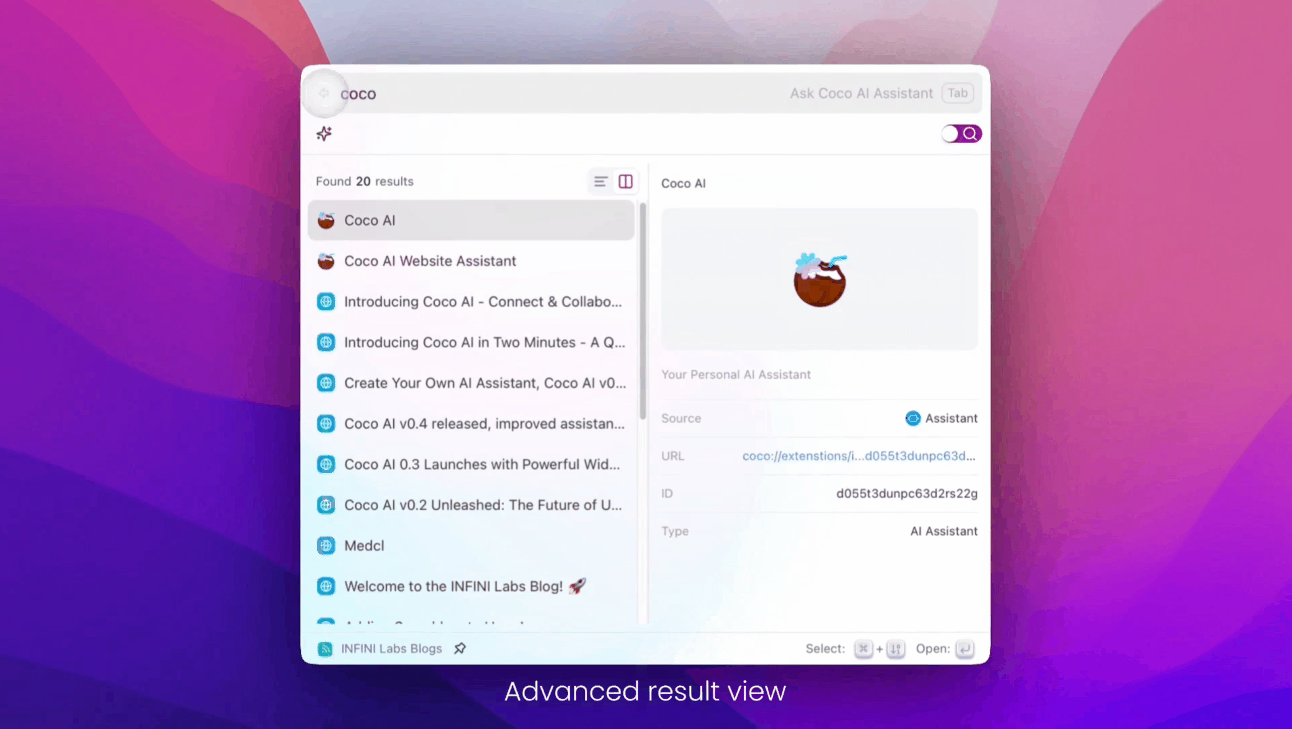
- 点击或回车关闭助手列表
- 为置顶窗口添加暗度设置
- 支持 Shift + Enter 输入框换行
- 支持快照版本更新
- 历史记录列表添加收起按钮
- 聊天输入框支持多行输入
- 将 ~/Applications 添加到搜索路径
- 聊天内容添加返回底部按钮
- 搜索输入框支持多行输入
- WebSocket 支持自签名 TLS
- 添加允许自签名证书选项
- 支持通过环境变量 COCO_LOG 动态设置日志级别
- 搜索结果重新排序
问题修复
- 修复为设置 API 添加缺失的 CORS 功能标志
- 修复数据源图标显示错误
- 修复处理 HugoSite 类型数据源中的空 URL 值
- 修复数据源和 MCP 选择问题
- 修复创建模型提供者时 crypto.randomUUID 的兼容性问题
- 修复服务器图像加载失败
- 修复在 Windows 系统上获取应用元数据时出现崩溃
- 修复服务切换错误
- 修复切换服务器助手后会话保持不变
- 修复历史列表高度的问题
- 修复二级页面无法被搜索到的问题
- 修复滚动按钮默认不显示
- 修复推荐列表位置
- 修复独立聊天窗口中没有数据的问题
- 修复继续聊天操作中的导航错误
优化改进
- 调整列表错误消息
- 修复解决在聊天中修改助手的问题
- 完善搜索失败的提示文案
- 搜索和 MCP 显示隐藏逻辑
- 问候语显示隐藏逻辑
- 重构实时获取设置中的应用列表
- UpdateApp 组件加载位置
- 添加清理监控和缓存计算以优化性能
- 重构优化代码
- 重构优化数字输入框的修改操作
- 修改搜索输入框样式
- 聊天输入图标显示
- 重构重构图标组件
- 重构优化 markdown 内容中的列表样式
- 添加文本朗读组件
- 历史组件样式
- 搜索错误样式
- 跳过未登录的注册服务器
- 重构服务信息相关组件
- 聊天内容可以被复制
- 重构修复搜索错误
- 添加助手消息计数
- 添加全局登录判断
- 在用户登出时标记服务器为离线状态
- 登出时更新服务器配置文件
- 小助手键盘事件和鼠标事件
- Web 组件起始页配置
- 小助手支持设置聊天输入占位符
- 重构输入框相关组件
- 在刷新信息时将不可用服务器标记为离线
- 在聊天模式中只显示可用服务器
- 重构搜索结果相关组件
Coco AI 服务端 v0.5
功能更新
- 支持将图标转换为 base64 格式
- 实现小助手问答 API
- 在聊天设置中添加占位符、分类和标签
- 在 provider info 中返回助手数量
- 添加小助手到搜索结果中
- 添加内置小助手
AI Overview - 添加带有请求指纹的限流过滤器
- 多用户登录支持
问题修复
- 修复为设置 API 添加缺失的 CORS 功能标志
- 修复数据源图标显示错误
- 修复处理 HugoSite 类型数据源中的空 URL 值
- 修复数据源和 MCP 选择问题
- 修复创建模型提供者时 crypto.randomUUID 的兼容性问题
- 修复嵌入组件起始页配置不起效的问题
优化改进
- 清理未使用的 LLM 设置代码
- 按创建时间排序聊天历史
- 为小助手编辑添加默认启用参数
- 密码支持更多特殊字符
- 重构聊天 API
- 忽略空消息
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。





INFINI Labs 产品更新发布!此次更新涵盖 Coco AI 产品多项重要升级,重点提升 AI 搜索能力、易用性及企业级优化。
- Coco AI v0.5 无缝集成 AI 搜索能力,支持第三方插件,新增 AI Command 快速访问 AI 能力,支持快照版本更新,优化交互细节,提升整体稳定性与用户体验等。
- Coco AI Server v0.5 强化 API 能力与安全性,完善小助手配置,支持多用户登录。
Coco AI v0.5
Coco AI 是一个完全开源、跨平台的统一 AI 搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.5
功能更新
- 搜索模式支持快速 AI 访问
- 支持插件扩展
- 添加 AI 摘要组件
- 支持搜索二级页面
- 点击或回车关闭助手列表
- 为置顶窗口添加暗度设置
- 支持 Shift + Enter 输入框换行
- 支持快照版本更新
- 历史记录列表添加收起按钮
- 聊天输入框支持多行输入
- 将 ~/Applications 添加到搜索路径
- 聊天内容添加返回底部按钮
- 搜索输入框支持多行输入
- WebSocket 支持自签名 TLS
- 添加允许自签名证书选项
- 支持通过环境变量 COCO_LOG 动态设置日志级别
- 搜索结果重新排序
问题修复
- 修复为设置 API 添加缺失的 CORS 功能标志
- 修复数据源图标显示错误
- 修复处理 HugoSite 类型数据源中的空 URL 值
- 修复数据源和 MCP 选择问题
- 修复创建模型提供者时 crypto.randomUUID 的兼容性问题
- 修复服务器图像加载失败
- 修复在 Windows 系统上获取应用元数据时出现崩溃
- 修复服务切换错误
- 修复切换服务器助手后会话保持不变
- 修复历史列表高度的问题
- 修复二级页面无法被搜索到的问题
- 修复滚动按钮默认不显示
- 修复推荐列表位置
- 修复独立聊天窗口中没有数据的问题
- 修复继续聊天操作中的导航错误
优化改进
- 调整列表错误消息
- 修复解决在聊天中修改助手的问题
- 完善搜索失败的提示文案
- 搜索和 MCP 显示隐藏逻辑
- 问候语显示隐藏逻辑
- 重构实时获取设置中的应用列表
- UpdateApp 组件加载位置
- 添加清理监控和缓存计算以优化性能
- 重构优化代码
- 重构优化数字输入框的修改操作
- 修改搜索输入框样式
- 聊天输入图标显示
- 重构重构图标组件
- 重构优化 markdown 内容中的列表样式
- 添加文本朗读组件
- 历史组件样式
- 搜索错误样式
- 跳过未登录的注册服务器
- 重构服务信息相关组件
- 聊天内容可以被复制
- 重构修复搜索错误
- 添加助手消息计数
- 添加全局登录判断
- 在用户登出时标记服务器为离线状态
- 登出时更新服务器配置文件
- 小助手键盘事件和鼠标事件
- Web 组件起始页配置
- 小助手支持设置聊天输入占位符
- 重构输入框相关组件
- 在刷新信息时将不可用服务器标记为离线
- 在聊天模式中只显示可用服务器
- 重构搜索结果相关组件
Coco AI 服务端 v0.5
功能更新
- 支持将图标转换为 base64 格式
- 实现小助手问答 API
- 在聊天设置中添加占位符、分类和标签
- 在 provider info 中返回助手数量
- 添加小助手到搜索结果中
- 添加内置小助手
AI Overview - 添加带有请求指纹的限流过滤器
- 多用户登录支持
问题修复
- 修复为设置 API 添加缺失的 CORS 功能标志
- 修复数据源图标显示错误
- 修复处理 HugoSite 类型数据源中的空 URL 值
- 修复数据源和 MCP 选择问题
- 修复创建模型提供者时 crypto.randomUUID 的兼容性问题
- 修复嵌入组件起始页配置不起效的问题
优化改进
- 清理未使用的 LLM 设置代码
- 按创建时间排序聊天历史
- 为小助手编辑添加默认启用参数
- 密码支持更多特殊字符
- 重构聊天 API
- 忽略空消息
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
活动预告 | Coco AI - 赋能企业搜索,打造专属智能助手【INFINI Workshop 第三期】

在生成式 AI 快速演进的今天,企业如何构建智能、高效、安全的搜索与交互系统,已成为提升信息利用效率与用户体验的关键。本次 Workshop 聚焦于极限科技推出的 Coco AI —— 一款完全开源、跨平台的企业级智能搜索与助手系统,带您深入了解其核心能力、技术架构与落地实践。
无论您是希望提升组织内部搜索效率的 IT 管理者,构建智能化办公系统的产品/研发团队,还是关注 AI 技术落地的开发者与创业者,本次活动都将带来满满干货,是一次不可错过的学习与交流机会。
活动时间:2025 年 7 月 10 日 13:30 ~ 17:30
活动地点:#腾讯会议:453-275-417
报名链接:https://hdxu.cn/1ffb5
内容摘要
- 企业多源异构数据的统一搜索方案
- Coco AI 如何构建类 ChatGPT 式智能问答助手
- Demo 演示:Coco AI 实现企业内部文档语义搜索与智能对话
- 案例实战:用 Coco AI 打造 Elasticsearch 智能助手
- 开源生态如何推动 Coco AI 持续创新
- 下一代企业 AI 搜索的演进趋势与 Coco AI 路线图
关于 Coco AI
Coco AI - 为现代团队打造的统一搜索与 AI 智能助手
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。

现代企业的三大痛点:
-
数据分散,信息孤岛严重 企业数据散落在本地文件系统、云存储(如 S3)、协作工具(如 Notion、Google Workspace)、知识平台(如语雀)、以及代码仓库(如 GitHub)等多个系统中。员工在多个平台之间频繁切换,导致信息获取效率低下,工作成本居高不下。
-
数据敏感,安全与隐私风险高 企业数据往往涉及敏感信息,不适合上云或调用公有云的大模型服务。像豆包、纳米搜索、Kimi 等流行 AI 工具由于无法部署在本地,难以在企业环境中落地使用。
- 数据沉睡,知识难以利用 企业多年积累的大量文档和资料,静静躺在角落却难以调用。传统知识管理依赖人工整理,效率低下,维护困难,知识资产无法真正发挥价值。
Coco AI 解决方案:
- 统一搜索入口,跨平台连接数据:支持连接本地与云端多种数据源,包括文件、协作平台、知识库、代码仓库等,一站式搜索和信息聚合。
- 私有化部署,保障数据安全:完全开源,自主可控,可私有部署,数据不出企业,满足高安全、高合规场景需求。
- 融合大模型,构建智能助手:接入 DeepSeek 等先进大模型,支持语义理解、自然语言问答、智能推荐,激活沉睡数据,打造真正“会思考”的企业知识中枢。
以下是 Coco AI 项目地址, 可以先睹为快, 欢迎 Star 转发分享~
项目主页:
开源地址:
参会提示
- 请务必自备电脑;
- 如有任何疑问可添加 INFINI Labs 小助手(微信号: INFINI-Labs)进行联系
在生成式 AI 快速演进的今天,企业如何构建智能、高效、安全的搜索与交互系统,已成为提升信息利用效率与用户体验的关键。本次 Workshop 聚焦于极限科技推出的 Coco AI —— 一款完全开源、跨平台的企业级智能搜索与助手系统,带您深入了解其核心能力、技术架构与落地实践。
无论您是希望提升组织内部搜索效率的 IT 管理者,构建智能化办公系统的产品/研发团队,还是关注 AI 技术落地的开发者与创业者,本次活动都将带来满满干货,是一次不可错过的学习与交流机会。
活动时间:2025 年 7 月 10 日 13:30 ~ 17:30
活动地点:#腾讯会议:453-275-417
报名链接:https://hdxu.cn/1ffb5
内容摘要
- 企业多源异构数据的统一搜索方案
- Coco AI 如何构建类 ChatGPT 式智能问答助手
- Demo 演示:Coco AI 实现企业内部文档语义搜索与智能对话
- 案例实战:用 Coco AI 打造 Elasticsearch 智能助手
- 开源生态如何推动 Coco AI 持续创新
- 下一代企业 AI 搜索的演进趋势与 Coco AI 路线图
关于 Coco AI
Coco AI - 为现代团队打造的统一搜索与 AI 智能助手
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
现代企业的三大痛点:
-
数据分散,信息孤岛严重 企业数据散落在本地文件系统、云存储(如 S3)、协作工具(如 Notion、Google Workspace)、知识平台(如语雀)、以及代码仓库(如 GitHub)等多个系统中。员工在多个平台之间频繁切换,导致信息获取效率低下,工作成本居高不下。
-
数据敏感,安全与隐私风险高 企业数据往往涉及敏感信息,不适合上云或调用公有云的大模型服务。像豆包、纳米搜索、Kimi 等流行 AI 工具由于无法部署在本地,难以在企业环境中落地使用。
- 数据沉睡,知识难以利用 企业多年积累的大量文档和资料,静静躺在角落却难以调用。传统知识管理依赖人工整理,效率低下,维护困难,知识资产无法真正发挥价值。
Coco AI 解决方案:
- 统一搜索入口,跨平台连接数据:支持连接本地与云端多种数据源,包括文件、协作平台、知识库、代码仓库等,一站式搜索和信息聚合。
- 私有化部署,保障数据安全:完全开源,自主可控,可私有部署,数据不出企业,满足高安全、高合规场景需求。
- 融合大模型,构建智能助手:接入 DeepSeek 等先进大模型,支持语义理解、自然语言问答、智能推荐,激活沉睡数据,打造真正“会思考”的企业知识中枢。
以下是 Coco AI 项目地址, 可以先睹为快, 欢迎 Star 转发分享~
项目主页:
开源地址:
参会提示
- 请务必自备电脑;
- 如有任何疑问可添加 INFINI Labs 小助手(微信号: INFINI-Labs)进行联系
Easysearch 索引备份之 Clone API
在日常运维 Easysearch 的过程中,备份数据是一项重要工作。为了确保数据安全和业务连续性,我们可能需要了解并掌握多种备份索引的方法,以便应对不同的场景。我们先梳理下常用的备份方法有哪些。
Snapshot
Easysearch 的 Snapshot(快照) 是一种官方支持的集群数据备份与恢复机制,通过将索引数据、集群状态(如设置、模板)和分片分配信息保存到外部存储仓库(如本地文件系统、AWS S3、华为云 OBS 等)实现全量或增量备份。其核心原理是复制索引的 Lucene 分片文件,并利用段文件(Segment)的不可变性实现增量存储优化。
快照的优点包括:
- 高效性:增量备份仅存储新增或修改的段文件,显著节省存储空间和网络传输成本;
- 可靠性:支持跨集群恢复和灾难性故障修复,避免直接拷贝数据目录导致的数据不一致风险;
- 灵活性:可指定备份特定索引,并支持版本兼容性恢复(需遵循版本匹配规则);
- 自动化:通过策略(Snapshot Policy)实现定时备份管理。
缺点则包括:
- 时效性限制:无法实现实时备份,是一种 PIT (Point in Time) 备份;
- 需预先配置:需预先注册仓库并确保存储系统可用性;
- 恢复约束:恢复时需关闭或删除目标索引,或恢复时修改索引名称;
- 依赖主分片状态:若主分片不可用(如节点故障),快照任务会失败。
总体而言,Snapshot 是生产环境首选的备份方案,尤其适合大规模数据归档和跨环境迁移,但需权衡备份频率与存储成本。详情可以参考文档。
Reindex
Easysearch 的 Reindex 是一种通过 API 将数据从一个索引复制到另一个索引的备份方法,适用于同集群或跨集群的数据迁移与重建。其核心操作是使用 POST _reindex 命令将源索引的文档批量读取并写入目标索引。备份时需确保目标索引的 Mapping 与源索引兼容(字段类型一致),并通过 size 参数控制批量处理量(如 "size": 2000)以优化性能。对于跨集群备份,需在目标集群配置文件中添加源集群 IP 白名单(reindex.remote.whitelist)并提供认证信息,详情可以参考文档。
优点:
- 灵活性:支持通过
query参数筛选特定数据备份(如仅迁移某字段值符合条件的数据); - 无缝整合:可在目标索引中修改索引结构(如分片数、字段类型);
- 并发及限流:支持设置并发度和限流阈值,适应不同的场景;
- 操作便捷:无需额外存储配置,适合临时备份或小规模迁移。
缺点:
- 资源消耗大:reindex 本质是数据写入,要占用 CPU、内存和磁盘 IO,可能影响集群性能;
- 网络依赖:跨集群备份依赖网络带宽,高延迟或带宽不足会显著拖慢速度;
- 中断风险:reindex 一旦中途报错,无法继续重试,只能从头再来;
- 时效性局限:备份完成后新增数据需手动触发二次迁移,无法实现实时同步。
建议在低峰期执行 Reindex,并优先采用快照(Snapshot)进行生产环境长期备份,Reindex 更适合索引结构调整或小规模数据迁移场景。
工具备份
还有些工具支持将 Easyearch 的索引数据备份成一个文件,比如 elasticsearch-dump、Logstash 等。数据量较大的情况下,这些工具可能会有效率问题,一般在特定场景下有用,在此不展开介绍。
Clone API
Easysearch 的 Clone API 并不是传统意义上的备份工具,其核心设计目标是通过复制索引的底层段文件(Segment)快速生成一个与原索引数据一致的新索引,包括源索引是 Mapping 和 Setting 也一起复制。
具体操作步骤如下:
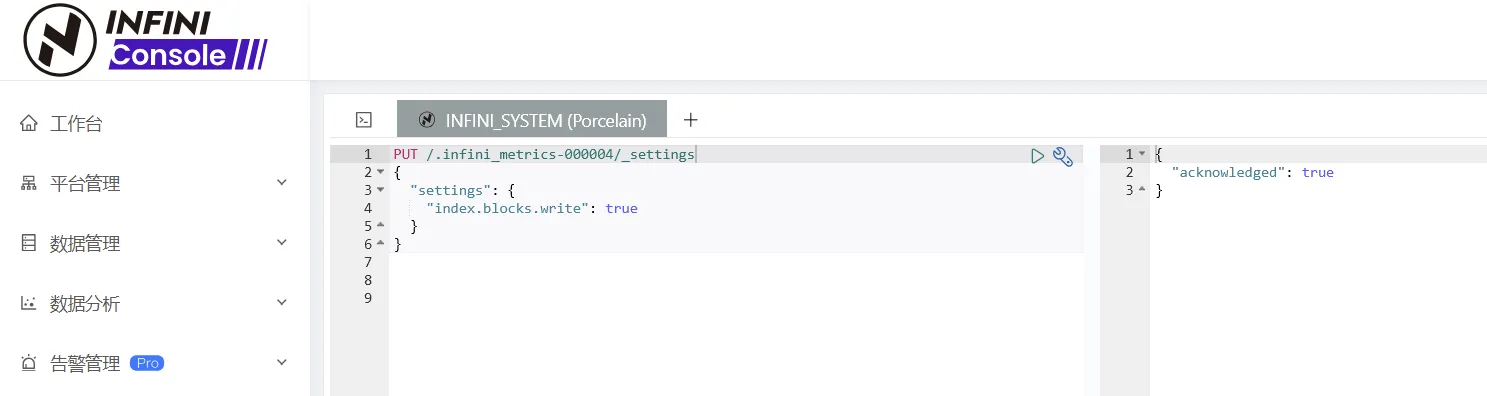
- 设置源索引为只读状态
PUT /.infini_metrics-000004/_settings
{
"settings": {
"index.blocks.write": true
}
}
- 执行 Clone 操作
POST .infini_metrics-000004/_clone/backup_infini_metrics-000004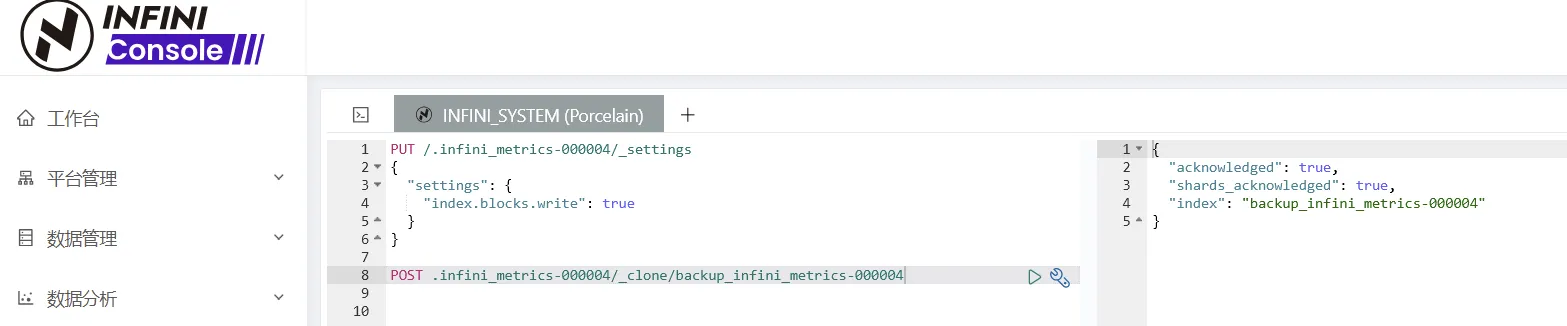
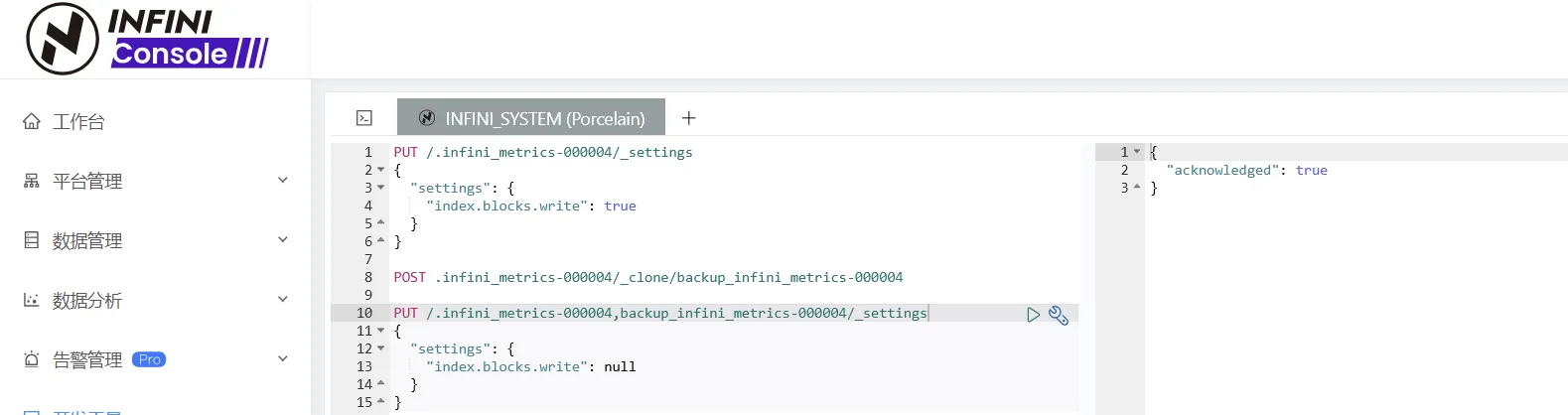
- 设置源索引和新索引为可读写状态
复制是新索引也会是只可读状态,大家根据需要选择是否都改成可读写状态。
PUT /.infini_metrics-000004,backup_infini_metrics-000004/_settings
{
"settings": {
"index.blocks.write": null
}
}
优点:
- 极速复制:直接复用底层段文件,无需重写数据,适用于大数据量快速复制。
- 保留定义: 直接使用源索引的 Setting 和 Mapping。
- 存储优化:可调整目标索引的副本数,节省资源。
缺点:
- 业务影响:克隆前需修改源索引为只可读,导致写入中断,影响服务可用性。
- 不够灵活:沿用源索引 Setting 和 Mapping 无法修改(副本数可修改)。
- 扩展性不足:不能跨集群,目标索引只能在本集群。
Clone API 有自己鲜明的特点,对比 Snapshot,它不用恢复过程,目标索引直接在集群中了。对比 Reindex,它无需重写数据和先创建索引,更加高效。在特定场景下非常有用,也可以搭配其他备份方法一起使用。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
原文:https://infinilabs.cn/blog/2025/easysearch-index-clone-api/
在日常运维 Easysearch 的过程中,备份数据是一项重要工作。为了确保数据安全和业务连续性,我们可能需要了解并掌握多种备份索引的方法,以便应对不同的场景。我们先梳理下常用的备份方法有哪些。
Snapshot
Easysearch 的 Snapshot(快照) 是一种官方支持的集群数据备份与恢复机制,通过将索引数据、集群状态(如设置、模板)和分片分配信息保存到外部存储仓库(如本地文件系统、AWS S3、华为云 OBS 等)实现全量或增量备份。其核心原理是复制索引的 Lucene 分片文件,并利用段文件(Segment)的不可变性实现增量存储优化。
快照的优点包括:
- 高效性:增量备份仅存储新增或修改的段文件,显著节省存储空间和网络传输成本;
- 可靠性:支持跨集群恢复和灾难性故障修复,避免直接拷贝数据目录导致的数据不一致风险;
- 灵活性:可指定备份特定索引,并支持版本兼容性恢复(需遵循版本匹配规则);
- 自动化:通过策略(Snapshot Policy)实现定时备份管理。
缺点则包括:
- 时效性限制:无法实现实时备份,是一种 PIT (Point in Time) 备份;
- 需预先配置:需预先注册仓库并确保存储系统可用性;
- 恢复约束:恢复时需关闭或删除目标索引,或恢复时修改索引名称;
- 依赖主分片状态:若主分片不可用(如节点故障),快照任务会失败。
总体而言,Snapshot 是生产环境首选的备份方案,尤其适合大规模数据归档和跨环境迁移,但需权衡备份频率与存储成本。详情可以参考文档。
Reindex
Easysearch 的 Reindex 是一种通过 API 将数据从一个索引复制到另一个索引的备份方法,适用于同集群或跨集群的数据迁移与重建。其核心操作是使用 POST _reindex 命令将源索引的文档批量读取并写入目标索引。备份时需确保目标索引的 Mapping 与源索引兼容(字段类型一致),并通过 size 参数控制批量处理量(如 "size": 2000)以优化性能。对于跨集群备份,需在目标集群配置文件中添加源集群 IP 白名单(reindex.remote.whitelist)并提供认证信息,详情可以参考文档。
优点:
- 灵活性:支持通过
query参数筛选特定数据备份(如仅迁移某字段值符合条件的数据); - 无缝整合:可在目标索引中修改索引结构(如分片数、字段类型);
- 并发及限流:支持设置并发度和限流阈值,适应不同的场景;
- 操作便捷:无需额外存储配置,适合临时备份或小规模迁移。
缺点:
- 资源消耗大:reindex 本质是数据写入,要占用 CPU、内存和磁盘 IO,可能影响集群性能;
- 网络依赖:跨集群备份依赖网络带宽,高延迟或带宽不足会显著拖慢速度;
- 中断风险:reindex 一旦中途报错,无法继续重试,只能从头再来;
- 时效性局限:备份完成后新增数据需手动触发二次迁移,无法实现实时同步。
建议在低峰期执行 Reindex,并优先采用快照(Snapshot)进行生产环境长期备份,Reindex 更适合索引结构调整或小规模数据迁移场景。
工具备份
还有些工具支持将 Easyearch 的索引数据备份成一个文件,比如 elasticsearch-dump、Logstash 等。数据量较大的情况下,这些工具可能会有效率问题,一般在特定场景下有用,在此不展开介绍。
Clone API
Easysearch 的 Clone API 并不是传统意义上的备份工具,其核心设计目标是通过复制索引的底层段文件(Segment)快速生成一个与原索引数据一致的新索引,包括源索引是 Mapping 和 Setting 也一起复制。
具体操作步骤如下:
- 设置源索引为只读状态
PUT /.infini_metrics-000004/_settings
{
"settings": {
"index.blocks.write": true
}
}
- 执行 Clone 操作
POST .infini_metrics-000004/_clone/backup_infini_metrics-000004
- 设置源索引和新索引为可读写状态
复制是新索引也会是只可读状态,大家根据需要选择是否都改成可读写状态。
PUT /.infini_metrics-000004,backup_infini_metrics-000004/_settings
{
"settings": {
"index.blocks.write": null
}
}
优点:
- 极速复制:直接复用底层段文件,无需重写数据,适用于大数据量快速复制。
- 保留定义: 直接使用源索引的 Setting 和 Mapping。
- 存储优化:可调整目标索引的副本数,节省资源。
缺点:
- 业务影响:克隆前需修改源索引为只可读,导致写入中断,影响服务可用性。
- 不够灵活:沿用源索引 Setting 和 Mapping 无法修改(副本数可修改)。
- 扩展性不足:不能跨集群,目标索引只能在本集群。
Clone API 有自己鲜明的特点,对比 Snapshot,它不用恢复过程,目标索引直接在集群中了。对比 Reindex,它无需重写数据和先创建索引,更加高效。在特定场景下非常有用,也可以搭配其他备份方法一起使用。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
收起阅读 »作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
原文:https://infinilabs.cn/blog/2025/easysearch-index-clone-api/
【搜索客社区日报】第2055期 (2025-06-16)
https://infinilabs.cn/blog/202 ... -api/
2、私有知识库 Coco AI 实战(一):Coco Server Linux 平台部署
https://infinilabs.cn/blog/202 ... on-1/、
3、风口|继MoE、MCP与A2A之后,下一个模型协作风口是MoA
https://mp.weixin.qq.com/s/_yv9gdBKv1yDK0rQNtbbiQ
4、干货:手把手搭建ElasticSearch日志监控告警
https://mp.weixin.qq.com/s/JH2AIAnxdFSPhsG7h-9y_g
5、搭建持久化的 INFINI Console 与 Easysearch 容器环境
https://infinilabs.cn/blog/202 ... cker/
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... -api/
2、私有知识库 Coco AI 实战(一):Coco Server Linux 平台部署
https://infinilabs.cn/blog/202 ... on-1/、
3、风口|继MoE、MCP与A2A之后,下一个模型协作风口是MoA
https://mp.weixin.qq.com/s/_yv9gdBKv1yDK0rQNtbbiQ
4、干货:手把手搭建ElasticSearch日志监控告警
https://mp.weixin.qq.com/s/JH2AIAnxdFSPhsG7h-9y_g
5、搭建持久化的 INFINI Console 与 Easysearch 容器环境
https://infinilabs.cn/blog/202 ... cker/
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2056期 (2025-06-17)
1. 搜索系统分布式事务实战(需要梯子)
https://godfreym.medium.com/cr ... 42509
https://godfreym.medium.com/cr ... 496c9
2. ES node 里的热线程了解下?(需要梯子)
https://medium.com/%40stefnest ... ab4e7
3. 拿Helm在K8S里装ES全家(需要梯子)
https://medium.com/%40mehmetka ... 37da6
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 搜索系统分布式事务实战(需要梯子)
https://godfreym.medium.com/cr ... 42509
https://godfreym.medium.com/cr ... 496c9
2. ES node 里的热线程了解下?(需要梯子)
https://medium.com/%40stefnest ... ab4e7
3. 拿Helm在K8S里装ES全家(需要梯子)
https://medium.com/%40mehmetka ... 37da6
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2054期 (2025-06-12)
https://mp.weixin.qq.com/s/PceGq8MIwda6tVYfoMy1iw
2.Prefix Caching 详解:实现 KV Cache 的跨请求高效复用
https://mp.weixin.qq.com/s/_FnXC7hiQtwyzU-ISvU0CA
3.MCP Server 之旅第 5 站:服务鉴权体系解密
https://mp.weixin.qq.com/s/C1d_uPAXQ38Pe1nFdrB1nQ
4.vLLM中的推测式解码技术
https://www.bilibili.com/video/BV1hMj4zDEax
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/PceGq8MIwda6tVYfoMy1iw
2.Prefix Caching 详解:实现 KV Cache 的跨请求高效复用
https://mp.weixin.qq.com/s/_FnXC7hiQtwyzU-ISvU0CA
3.MCP Server 之旅第 5 站:服务鉴权体系解密
https://mp.weixin.qq.com/s/C1d_uPAXQ38Pe1nFdrB1nQ
4.vLLM中的推测式解码技术
https://www.bilibili.com/video/BV1hMj4zDEax
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch 迁移数据之 Reindex From Remote
在之前的博客《从 Elasticsearch 迁移到 Easysearch 指引》中介绍过如何把索引从 Elasticsearch 迁移到 Easysearch。有时候想临时从 Elasticsearch 迁移点儿数据做测试,数据量不大,也可尝试使用 Reindex From Remote 的方法。
测试环境介绍
本次主要测试从远程集群索引数据,reindex 还有很多其他使用方式,详情请参考官方文档。
- Easysearch 版本:1.10.0,监听 localhost:9200
- Elasticsearch 版本:6.8.23,监听 localhost:9201
- INFINI Console 版本:1.25.1(运行 reindex 命令用)
Reindex API
Reindex 可以从本地或远程集群将源索引数据写入本地目标索引。使用简单,有以下注意点:
- 源索引启用 _source ,这个默认都是启用的
- 在调用 _reindex 之前,应该先创建、配置目标索引
- 如果源索引在远程集群,必须在 easysearch.yml 中配置 reindex.remote.whitelist 设置
- 使用 POST 调用
测试过程
我们先不设置白名单,直接从远程集群 reindex 看看会怎样。
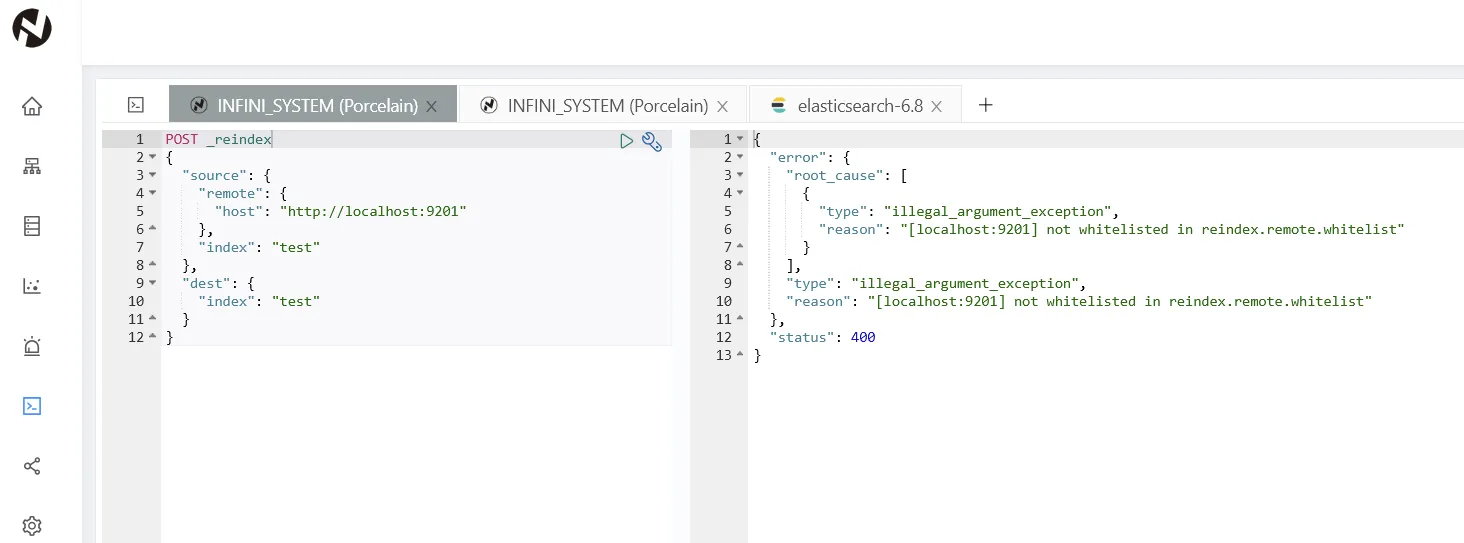
报错提示 localhost:9201 不在 reindex.remote.whitelist 中。
正常操作步骤
- 编辑 Easysearch 配置文件 easysearch.yml,添加白名单,重启生效。
reindex.remote.whitelist: [localhost:9201]- 建立目标索引,指定 setting 和 mapping
reindex 不会复制源索引的 setting 和 mapping,需要提前创建目标索引,否则会使用默认设置。
- 执行 reindex 命令
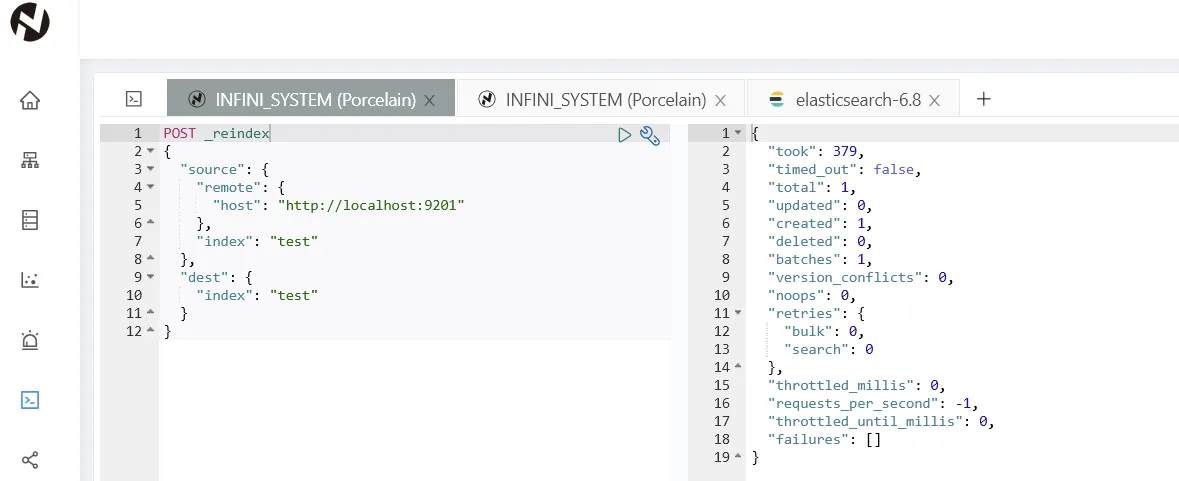
执行成功。需要注意的是,如果数据量比较大,reindex 命令会超时,这个没关系,任务会继续在后台执行。也可以在执行 reindex 的时候添加参数 wait_for_completion=false 不等待执行完成,直接返回任务 id。
POST _reindex?wait_for_completion=false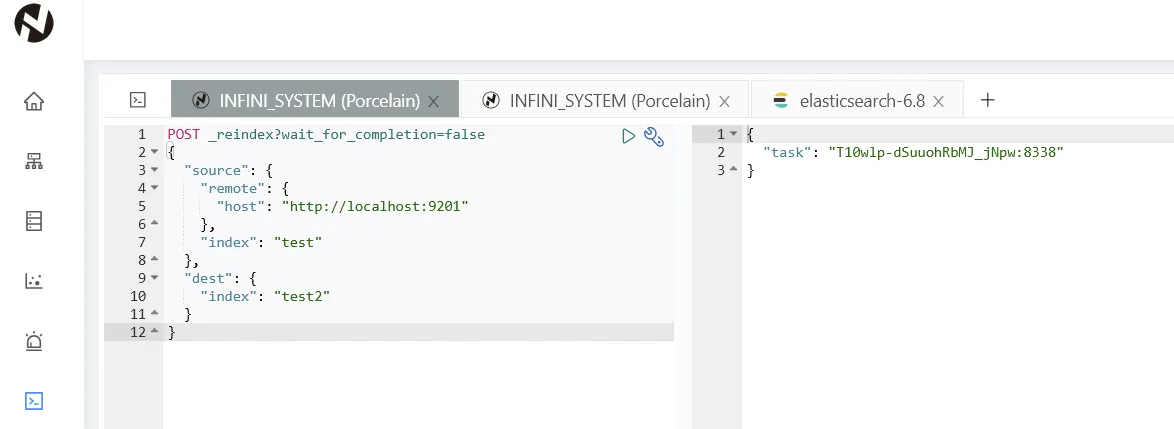
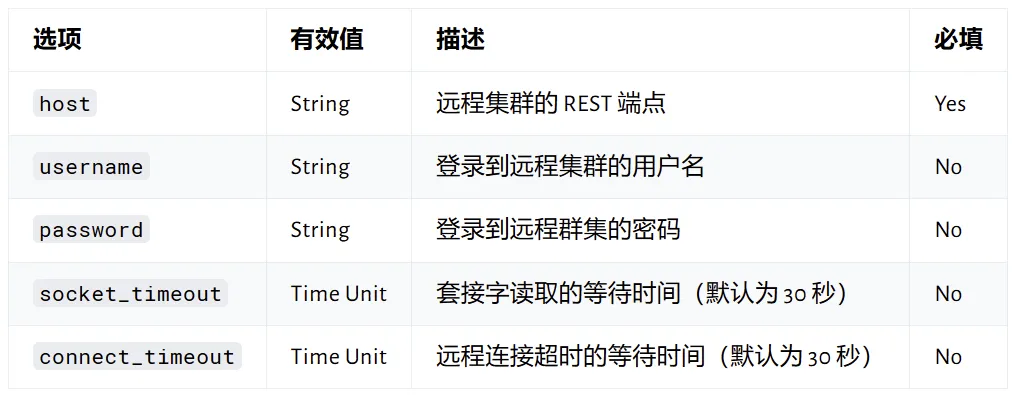
针对有认证的集群,reindex 可以指定以下选项:
总结
针对临时数据量不大的场景可尝试使用 reindex 迁移数据。如果数据量大了,reindex 迁移速度不是很高效,而且如果中途出现错误迁移中断了,需要重新 reindex 不方便,建议使用 INFINI Console 进行数据迁移。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
原文:https://infinilabs.cn/blog/2025/easysearch-reindex-from-remote/
在之前的博客《从 Elasticsearch 迁移到 Easysearch 指引》中介绍过如何把索引从 Elasticsearch 迁移到 Easysearch。有时候想临时从 Elasticsearch 迁移点儿数据做测试,数据量不大,也可尝试使用 Reindex From Remote 的方法。
测试环境介绍
本次主要测试从远程集群索引数据,reindex 还有很多其他使用方式,详情请参考官方文档。
- Easysearch 版本:1.10.0,监听 localhost:9200
- Elasticsearch 版本:6.8.23,监听 localhost:9201
- INFINI Console 版本:1.25.1(运行 reindex 命令用)
Reindex API
Reindex 可以从本地或远程集群将源索引数据写入本地目标索引。使用简单,有以下注意点:
- 源索引启用 _source ,这个默认都是启用的
- 在调用 _reindex 之前,应该先创建、配置目标索引
- 如果源索引在远程集群,必须在 easysearch.yml 中配置 reindex.remote.whitelist 设置
- 使用 POST 调用
测试过程
我们先不设置白名单,直接从远程集群 reindex 看看会怎样。
报错提示 localhost:9201 不在 reindex.remote.whitelist 中。
正常操作步骤
- 编辑 Easysearch 配置文件 easysearch.yml,添加白名单,重启生效。
reindex.remote.whitelist: [localhost:9201]- 建立目标索引,指定 setting 和 mapping
reindex 不会复制源索引的 setting 和 mapping,需要提前创建目标索引,否则会使用默认设置。
- 执行 reindex 命令
执行成功。需要注意的是,如果数据量比较大,reindex 命令会超时,这个没关系,任务会继续在后台执行。也可以在执行 reindex 的时候添加参数 wait_for_completion=false 不等待执行完成,直接返回任务 id。
POST _reindex?wait_for_completion=false
针对有认证的集群,reindex 可以指定以下选项:
总结
针对临时数据量不大的场景可尝试使用 reindex 迁移数据。如果数据量大了,reindex 迁移速度不是很高效,而且如果中途出现错误迁移中断了,需要重新 reindex 不方便,建议使用 INFINI Console 进行数据迁移。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
收起阅读 »作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
原文:https://infinilabs.cn/blog/2025/easysearch-reindex-from-remote/
【搜索客社区日报】第2053期 (2025-06-11)
https://mp.weixin.qq.com/s/jweFzFp9GN56KbV7ChlLkQ
2.运维快看!如何基于Deepseek打造日志分析智能系统?
https://mp.weixin.qq.com/s/nzgbFqorPE2bNvGQ0lcSkA
3.节省 90% 存储!源码级揭秘腾讯云 ES 向量搜索的优化之道
https://blog.csdn.net/UbuntuTo ... 63465
4.ES8 向量功能窥探系列(一):混合搜索功能初探与增强
https://blog.csdn.net/UbuntuTo ... 09817
5.ES8 向量功能窥探系列(二):向量数据的存储与优化
https://blog.csdn.net/UbuntuTo ... 10255
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/jweFzFp9GN56KbV7ChlLkQ
2.运维快看!如何基于Deepseek打造日志分析智能系统?
https://mp.weixin.qq.com/s/nzgbFqorPE2bNvGQ0lcSkA
3.节省 90% 存储!源码级揭秘腾讯云 ES 向量搜索的优化之道
https://blog.csdn.net/UbuntuTo ... 63465
4.ES8 向量功能窥探系列(一):混合搜索功能初探与增强
https://blog.csdn.net/UbuntuTo ... 09817
5.ES8 向量功能窥探系列(二):向量数据的存储与优化
https://blog.csdn.net/UbuntuTo ... 10255
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »

