

【搜索客社区日报】第2052期 (2025-06-10)
https://medium.com/%40nitishgo ... 04805
2. 你们也遇到过field映射的问题吗?(需要梯子)
https://medium.com/%40gireesha ... e1032
3. 来看看老司机是怎么无痛集群重启的(需要梯子)
https://medium.com/softtechas/ ... 99b0e
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40nitishgo ... 04805
2. 你们也遇到过field映射的问题吗?(需要梯子)
https://medium.com/%40gireesha ... e1032
3. 来看看老司机是怎么无痛集群重启的(需要梯子)
https://medium.com/softtechas/ ... 99b0e
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2051期 (2025-06-09)
https://mp.weixin.qq.com/s/tzCQHfRP7Yi8L-PKePAT_g
2、Elasticsearch与milvus作为RAG向量库怎么选
https://mp.weixin.qq.com/s/njh3mOed7SP_OmdWxVuWIQ
3、向量数据库--基于图的近似最近邻搜索
https://mp.weixin.qq.com/s/vDIwUq7xYG_d3KolI6Nhig
4、Qwen3新成员:Embedding系列模型登场!
https://mp.weixin.qq.com/s/ArLFeE6oTk0UwxwW5WHtjA
5、Response指南:为什么90%的多模态RAG,一做就会,一用就废?
https://mp.weixin.qq.com/s/ARKRV3No9orWPL9E_J7UJQ
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/tzCQHfRP7Yi8L-PKePAT_g
2、Elasticsearch与milvus作为RAG向量库怎么选
https://mp.weixin.qq.com/s/njh3mOed7SP_OmdWxVuWIQ
3、向量数据库--基于图的近似最近邻搜索
https://mp.weixin.qq.com/s/vDIwUq7xYG_d3KolI6Nhig
4、Qwen3新成员:Embedding系列模型登场!
https://mp.weixin.qq.com/s/ArLFeE6oTk0UwxwW5WHtjA
5、Response指南:为什么90%的多模态RAG,一做就会,一用就废?
https://mp.weixin.qq.com/s/ARKRV3No9orWPL9E_J7UJQ
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2050期 (2025-06-06)
https://mp.weixin.qq.com/s/2x_z04W-_mjKpqpWcmZPzA
2、私有知识库 Coco AI 实战(五):打造 ES 新特性查询助手
https://blog.csdn.net/yangmf20 ... 27174
3、私有知识库 Coco AI 实战(六):打造 ES Mapping 小助手
https://blog.csdn.net/yangmf20 ... 27210
4、向量配方:使用 OpenSearch 构建混合搜索应用
https://opensearch.org/blog/re ... earch
5、使用 Logstash 迁移 MongoDB 数据到 Easysearch
https://infinilabs.cn/blog/202 ... stash
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/2x_z04W-_mjKpqpWcmZPzA
2、私有知识库 Coco AI 实战(五):打造 ES 新特性查询助手
https://blog.csdn.net/yangmf20 ... 27174
3、私有知识库 Coco AI 实战(六):打造 ES Mapping 小助手
https://blog.csdn.net/yangmf20 ... 27210
4、向量配方:使用 OpenSearch 构建混合搜索应用
https://opensearch.org/blog/re ... earch
5、使用 Logstash 迁移 MongoDB 数据到 Easysearch
https://infinilabs.cn/blog/202 ... stash
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2049期 (2025-06-05)
https://lmsys.org/blog/2024-02-05-compressed-fsm/
2.Elasticsearch 中的大型文档分块 - 递归分块策略
https://www.elastic.co/search- ... lines
3.OpenTelemetry × Elastic Observability 系列(一):整体架构介绍
https://mp.weixin.qq.com/s/h8D1Z8_bI8GcM8kwyNlZeA
4.原理&图解vLLM Automatic Prefix Cache(RadixAttention): 首Token时延优化
https://zhuanlan.zhihu.com/p/693556044
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://lmsys.org/blog/2024-02-05-compressed-fsm/
2.Elasticsearch 中的大型文档分块 - 递归分块策略
https://www.elastic.co/search- ... lines
3.OpenTelemetry × Elastic Observability 系列(一):整体架构介绍
https://mp.weixin.qq.com/s/h8D1Z8_bI8GcM8kwyNlZeA
4.原理&图解vLLM Automatic Prefix Cache(RadixAttention): 首Token时延优化
https://zhuanlan.zhihu.com/p/693556044
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2048期 (2025-06-04)
https://mp.weixin.qq.com/s/pLoZODAnKsosxIuLpv1V0A
2.千亿级向量索引的秘密武器:一文详解蚂蚁集团的工程实践和开源突破
https://mp.weixin.qq.com/s/ksxfXCRqGas1gLAycr1P4A
3.还在用 ELK?你已经 Out 了
https://mp.weixin.qq.com/s/mOvHuL1gEid9sGcjRYKmKQ
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/pLoZODAnKsosxIuLpv1V0A
2.千亿级向量索引的秘密武器:一文详解蚂蚁集团的工程实践和开源突破
https://mp.weixin.qq.com/s/ksxfXCRqGas1gLAycr1P4A
3.还在用 ELK?你已经 Out 了
https://mp.weixin.qq.com/s/mOvHuL1gEid9sGcjRYKmKQ
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2046期 (2025-06-03)
https://dineshkumarnaik.medium ... 8e127
2. 被证书过期搞的欲仙欲死的是谁我不说(需要梯子)
https://faun.pub/dont-let-ssl- ... b5fc0
3. ES的自动扩容小助手好用不(需要梯子)
https://medium.com/%40holidu/e ... 2b69c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://dineshkumarnaik.medium ... 8e127
2. 被证书过期搞的欲仙欲死的是谁我不说(需要梯子)
https://faun.pub/dont-let-ssl- ... b5fc0
3. ES的自动扩容小助手好用不(需要梯子)
https://medium.com/%40holidu/e ... 2b69c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2045期 (2025-05-29)
https://mp.weixin.qq.com/s/1__uUX7xMoQ6q7HFXrP2Bw
2.vLLM 核心技术 PagedAttention 原理详解
https://mp.weixin.qq.com/s/94-kEyHui0BLO5S-80eAiw
3.【万字长文】大模型开源开发全景与趋势解读
https://mp.weixin.qq.com/s/2xwyGPZppdYmU_cDX3Xhyg
4.技术干货|深度剖析将 Kafka 构建在 S3 上的技术挑战与最佳实践
https://mp.weixin.qq.com/s/_WggDfOoXhiIgFBWWROXnQ
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/1__uUX7xMoQ6q7HFXrP2Bw
2.vLLM 核心技术 PagedAttention 原理详解
https://mp.weixin.qq.com/s/94-kEyHui0BLO5S-80eAiw
3.【万字长文】大模型开源开发全景与趋势解读
https://mp.weixin.qq.com/s/2xwyGPZppdYmU_cDX3Xhyg
4.技术干货|深度剖析将 Kafka 构建在 S3 上的技术挑战与最佳实践
https://mp.weixin.qq.com/s/_WggDfOoXhiIgFBWWROXnQ
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2044期 (2025-05-27)
https://satyadeepmaheshwari.me ... 9ff75
2. 用ES + OpenTelemetry构建可观测体系(需要梯子)
https://medium.com/%40davidsil ... 2fe48
3. 用minikube搞个ES全家桶(需要梯子)
https://medium.com/%40sariiers ... fd80b
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://satyadeepmaheshwari.me ... 9ff75
2. 用ES + OpenTelemetry构建可观测体系(需要梯子)
https://medium.com/%40davidsil ... 2fe48
3. 用minikube搞个ES全家桶(需要梯子)
https://medium.com/%40sariiers ... fd80b
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2043期 (2025-05-22)
https://mp.weixin.qq.com/s/jm-zUBEgtj5EJ9yFPLQcZQ
2.Cursor 如何快速索引代码库
https://mp.weixin.qq.com/s/42y0HORmB0xLpOyIDCUcFQ
3.GPU火焰图的探索-iaprof
https://mp.weixin.qq.com/s/-K4QkPXY1DKPd6bq5rdrKA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/jm-zUBEgtj5EJ9yFPLQcZQ
2.Cursor 如何快速索引代码库
https://mp.weixin.qq.com/s/42y0HORmB0xLpOyIDCUcFQ
3.GPU火焰图的探索-iaprof
https://mp.weixin.qq.com/s/-K4QkPXY1DKPd6bq5rdrKA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2042期 (2025-05-21)
https://medium.com/%40the_mano ... 583ed
2.A2A + MCP 如何助您构建实用的 AI 系统(搭梯)
https://medium.com/%40the_mano ... b027b
3.智能路由:10 倍强大 AI 系统背后的秘密(搭梯)
https://medium.com/%40the_mano ... 6813a
4.Python A2A、MCP 和 LangChain:构建下一代模块化 GenAI 系统(搭梯)
https://medium.com/%40the_mano ... 4efae
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/%40the_mano ... 583ed
2.A2A + MCP 如何助您构建实用的 AI 系统(搭梯)
https://medium.com/%40the_mano ... b027b
3.智能路由:10 倍强大 AI 系统背后的秘密(搭梯)
https://medium.com/%40the_mano ... 6813a
4.Python A2A、MCP 和 LangChain:构建下一代模块化 GenAI 系统(搭梯)
https://medium.com/%40the_mano ... 4efae
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【直播活动】全面解析 Coco AI,一款完全开源、跨平台的企业级智能搜索与助手系统
在 AI 浪潮中,如何高效管理海量信息、实现智能搜索与知识共享,已成为个人与企业共同面临的挑战。Coco AI —— 一款完全开源、跨平台的企业级智能搜索与助手系统,成为面对这一挑战的利器。
Coco AI 能够轻松连接本地文件数据源、S3 对象存储、Google Workspace、Dropbox、GitHub、Notion、Yuque、Hugo 等多种数据源,实现本地与云端数据的统一搜索与管理。无论是文档、代码、项目管理工具,还是团队协作平台,Coco AI 都能一键整合,让企业数据 “化零为整”,彻底打破信息孤岛的束缚。
Coco AI 采用了 RAG 技术,结合传统检索和生成模型的优势,提供基于内容检索的生成式答案。它不仅能够精准匹配关键词,还能基于实际内容生成详细且高质量的回答。
这个开源搜索工具背后的公司,是国内一家初创企业 —— 极限科技 / INFINI Labs。其创始人兼 CEO 曾勇现正带领团队专注于下一代实时搜索引擎与 AI 智能搜索相关技术的研发与创新。
5 月 23 日,极限科技 / INFINI Labs 创始人兼 CEO 曾勇、高级解决方案架构师杨帆将做客开源中国《技术领航》栏目直播间,全面解析 Coco AI ,探索其核心功能、技术架构及实际应用场景 。
值得期待的是,直播中还将详解如何用 Coco AI 打造 Elasticsearch 智能助手,解决版本查询、问题排查、DSL/API 支持等痛点问题。
🔥 微信扫码,预约直播:

🔥 直播亮点:
功能与价值解析
- 如何通过 Coco AI 实现多源数据(本地文件、云端存储、Notion、语雀等)的智能化统一搜索与知识管理。
- 开源架构与 AI 技术(RAG、大模型集成)如何提升搜索精度与知识管理效率。
应用场景实战
-
Demo 演示:展示 Coco AI 如何快速构建企业级知识库,打破信息孤岛。
- ES 智能助手案例:详解如何用 Coco AI 打造 Elasticsearch 智能助手,解决版本查询、问题排查、DSL/API 支持等痛点。
开源生态与未来展望
-
社区驱动的开源生态如何推动 Coco AI 持续创新。
- 下一代 AI 搜索工具的发展趋势与 Coco AI 的长期规划。
本次直播中的另一名分享嘉宾杨帆,技术十分过硬,拥有十余年金融行业服务工作经验,是《老杨玩搜索》栏目 B 站 UP 主,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
大家有什么问题,可以在直播间互动提问~
关于开源中国
OSCHINA(开源中国) 成立于 2008 年 8 月,经过 17 年的深耕,已发展成为中国最大的开源与 AI 技术社区之一,拥有超过 1100 万的注册用户。自成立以来,OSCHINA 始终致力于为开发者提供专业服务,推动中国开源领域的快速发展。在早期,OSCHINA 建立了完善的开源软件分类数据库,收录了全球超过 12 万个知名项目,涵盖数百个不同的分类。社区为中国开发者提供最新的开源资讯、软件更新信息,以及技术分享和交流的平台,成为国内领先的开源技术交流社区。
关于 INFINI Labs
极限科技,专业的开源搜索与实时数据分析整体解决方案提供商。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
关于 Coco AI
Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
项目主页:https://coco.rs
Gitee:https://gitee.com/infinilabs/coco-app
GitCode:https://gitcode.com/infinilabs/coco-app
Github:https://github.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
在 AI 浪潮中,如何高效管理海量信息、实现智能搜索与知识共享,已成为个人与企业共同面临的挑战。Coco AI —— 一款完全开源、跨平台的企业级智能搜索与助手系统,成为面对这一挑战的利器。
Coco AI 能够轻松连接本地文件数据源、S3 对象存储、Google Workspace、Dropbox、GitHub、Notion、Yuque、Hugo 等多种数据源,实现本地与云端数据的统一搜索与管理。无论是文档、代码、项目管理工具,还是团队协作平台,Coco AI 都能一键整合,让企业数据 “化零为整”,彻底打破信息孤岛的束缚。
Coco AI 采用了 RAG 技术,结合传统检索和生成模型的优势,提供基于内容检索的生成式答案。它不仅能够精准匹配关键词,还能基于实际内容生成详细且高质量的回答。
这个开源搜索工具背后的公司,是国内一家初创企业 —— 极限科技 / INFINI Labs。其创始人兼 CEO 曾勇现正带领团队专注于下一代实时搜索引擎与 AI 智能搜索相关技术的研发与创新。
5 月 23 日,极限科技 / INFINI Labs 创始人兼 CEO 曾勇、高级解决方案架构师杨帆将做客开源中国《技术领航》栏目直播间,全面解析 Coco AI ,探索其核心功能、技术架构及实际应用场景 。
值得期待的是,直播中还将详解如何用 Coco AI 打造 Elasticsearch 智能助手,解决版本查询、问题排查、DSL/API 支持等痛点问题。
🔥 微信扫码,预约直播:
🔥 直播亮点:
功能与价值解析
- 如何通过 Coco AI 实现多源数据(本地文件、云端存储、Notion、语雀等)的智能化统一搜索与知识管理。
- 开源架构与 AI 技术(RAG、大模型集成)如何提升搜索精度与知识管理效率。
应用场景实战
-
Demo 演示:展示 Coco AI 如何快速构建企业级知识库,打破信息孤岛。
- ES 智能助手案例:详解如何用 Coco AI 打造 Elasticsearch 智能助手,解决版本查询、问题排查、DSL/API 支持等痛点。
开源生态与未来展望
-
社区驱动的开源生态如何推动 Coco AI 持续创新。
- 下一代 AI 搜索工具的发展趋势与 Coco AI 的长期规划。
本次直播中的另一名分享嘉宾杨帆,技术十分过硬,拥有十余年金融行业服务工作经验,是《老杨玩搜索》栏目 B 站 UP 主,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
大家有什么问题,可以在直播间互动提问~
关于开源中国
OSCHINA(开源中国) 成立于 2008 年 8 月,经过 17 年的深耕,已发展成为中国最大的开源与 AI 技术社区之一,拥有超过 1100 万的注册用户。自成立以来,OSCHINA 始终致力于为开发者提供专业服务,推动中国开源领域的快速发展。在早期,OSCHINA 建立了完善的开源软件分类数据库,收录了全球超过 12 万个知名项目,涵盖数百个不同的分类。社区为中国开发者提供最新的开源资讯、软件更新信息,以及技术分享和交流的平台,成为国内领先的开源技术交流社区。
关于 INFINI Labs
极限科技,专业的开源搜索与实时数据分析整体解决方案提供商。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
关于 Coco AI
Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,能够连接并搜索多种数据源,包括应用程序、文件、谷歌网盘、Notion、语雀、Hugo 等本地与云端数据。通过接入 DeepSeek 等大模型,Coco AI 实现了智能化的个人知识库管理,注重隐私,支持私有部署,帮助用户快速、智能地访问信息。
项目主页:https://coco.rs
Gitee:https://gitee.com/infinilabs/coco-app
GitCode:https://gitcode.com/infinilabs/coco-app
Github:https://github.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
收起阅读 »
【搜索客社区日报】第2040期 (2025-05-20)
https://medium.com/%40muktimis ... 440b8
2. 你会不会用ELK聚合日志?(需要梯子)
https://medium.com/%40mohammad ... a40a8
3. 来,我来教你怎么一天搭一个AI agent出来(需要梯子)
https://medium.com/alphax0/how ... 028a8
https://medium.com/%40kacembou ... ba7b4
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40muktimis ... 440b8
2. 你会不会用ELK聚合日志?(需要梯子)
https://medium.com/%40mohammad ... a40a8
3. 来,我来教你怎么一天搭一个AI agent出来(需要梯子)
https://medium.com/alphax0/how ... 028a8
https://medium.com/%40kacembou ... ba7b4
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
ES 调优帖:关于索引合并参数 index.merge.policy.deletePctAllowed 的取值优化
最近发现了 lucene 9.5 版本把 merge 策略的默认参数改了。
* GITHUB#11761: TieredMergePolicy now allowed a maximum allowable deletes percentage of down to 5%, and the default
maximum allowable deletes percentage is changed from 33% to 20%. (Marc D'Mello)也就是 index.merge.policy.deletePctAllowed 最小值可以取 5%(原来是 20%),而默认值为 20%(原来是 33%)。
这是一个控制索引中已删除文档的占比的参数,简单来说,调低这个参数能够降低存储大小,同时也需要更多的 cpu 和内存资源来完成这个调优。
通过这个帖子的讨论,大家可以发现,“实践出真知”,这次的参数调整是 lucene 社区对于用户积极反馈的采纳。因此,对于老版本的用户,也可以在 deletepct 比较高的场景下,调优这个参数,当然一切生产调整都需要经过测试。
对于 ES 的新用户来说,这时候可能冒出了下面这些问题
- 这个参数反馈的已删除文档占比 deletepct 是什么?
- 它怎么计算的呢?较高的 deletepct 会有什么影响?
- 较低的 deletepct 为什么会有更多的资源消耗?
- 除了调优这个参数还有什么优化办法么?
伴随这些问题,来探讨一下这个参数的来源和作用。
deletePctAllowed:软删除的遗留
在 Lucene 中,软删除是一种标记文档以便后续逻辑删除的机制,而不是立即从索引中物理删除文档。
但是这些软删除文档又不是永久存在的,deletePctAllowed 表示索引中允许存在的软删除文档占总文档数的最大百分比。
当软删除文档的比例达到或超过 deletePctAllowed 所设定的阈值时,Lucene 会触发索引合并操作。这是因为在合并过程中,那些被软删除的文档会被物理地从索引中移除,从而减少索引的存储空间占用。
当 deletePctAllowed 设置过低时,会频繁触发索引合并,因合并操作需大量磁盘 I/O、CPU 和内存资源,会使写入性能显著下降,磁盘 I/O 压力增大。假设 deletePctAllowed 为 0,则每次写入都需要消耗额外的资源来做 segment 的合并。
deletePctAllowed 过高,索引会容纳大量软删除文档,占用过多磁盘空间,增加存储成本且可能导致磁盘空间不足。查询时要过滤大量软删除文档,使查询响应时间变长、性能下降。同时也观察到,在使用 soft-deleted 特性后,文档更新和 refresh 也会受到影响,deletePctAllowed 过高,文档更新/refresh 操作耗时也会明显上升。
deletePctAllowed 的实际效果
从上面的解释看,index.merge.policy.deletePctAllowed 这个参数仿佛并不难理解,但实际上这个参数是应用到各个 segment 级别的,并且 segment 对这个参数的触发条件也是有限制(过小的 segment 并不会因为这个参数触发合并操作)。在多分片多 segment 的条件下,索引对 deletePctAllowed 参数实际的应用效果并不完全一致。因此,可以做个实际测试来看 deletePctAllowed 对索引产生的效果。
这里创建一个一千万文档的索引,然后全量更新一遍,看最后 deletePctAllowed 会保留多少的被删除文档。
GET test_del/_count
{
"count": 10000000,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
}
}
# 查看 delete 文档数量
GET test_del/_stats
···
"primaries": {
"docs": {
"count": 10000000,
"deleted": 0
},
···
这里的 deletePctAllowed 还是使用的 33%。
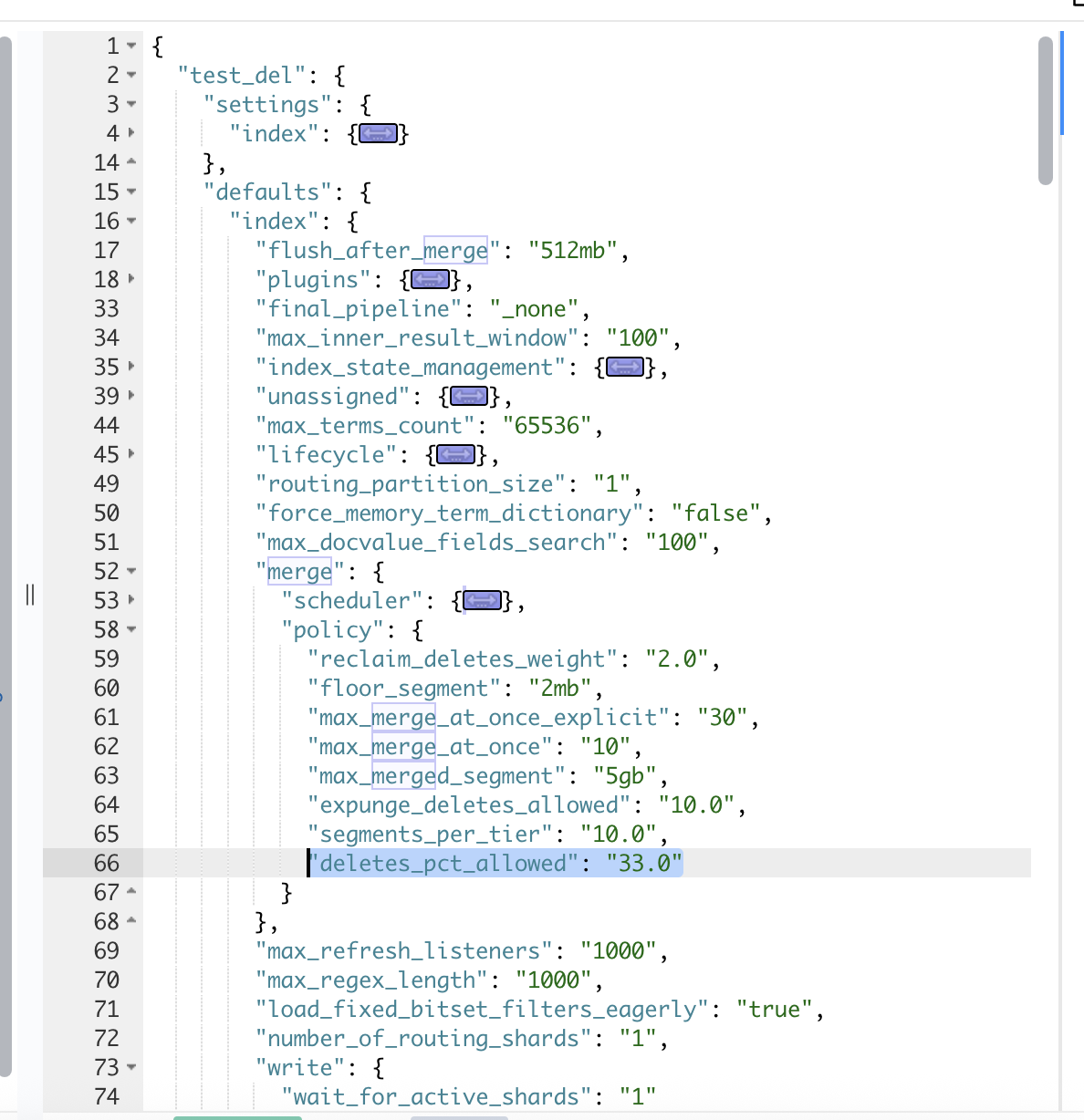
更新任务命令:
POST test_del/_update_by_query?wait_for_completion=false
{
"query": {
"match_all": {}
},
"script": {
"source": "ctx._source.field_name = 'new_value'",
"lang": "painless"
}
}完成后,
# 任务状态
···
"task": {
"node": "28HymM3xTESGMPRD3LvtCg",
"id": 10385666,
"type": "transport",
"action": "indices:data/write/update/byquery",
"status": {
"total": 10000000,
"updated": 10000000,# 这里可以看到全量更新
"created": 0,
"deleted": 0,
"batches": 10000,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0
}
···
# 索引的状态
GET test_del/_stats
···
"_all": {
"primaries": {
"docs": {
"count": 10000000,
"deleted": 809782
},
···实际删除文档与非删除文档的比例为 8.09%。
现在尝试调低 index.merge.policy.deletes_pct_allowed到 20%。
PUT test_del/_settings
{"index.merge.policy.deletes_pct_allowed":20}
由于之前删除文档占比过低,调整参数并不会触发新的 merge,因此需要重新全量更新数据查看一下是否有改变。
最终得到的索引状态如下:
GET test_del/_stats
···
"primaries": {
"docs": {
"count": 10000000,
"deleted": 190458
}
···这次得到的实际删除文档与非删除文档的比例为 1.9%
deletes_pct_allowed 默认值的调整
上面提到 deletePctAllowed 设置过低时,会频繁触发索引合并,而合并任务的线程使用线程类型是 SCALING 的,是一种动态扩展使用 cpu 的策略。

那么,当 deletePctAllowed 设置过低时,merge 任务增加,cpu 线程使用增加。集群的 cpu 和磁盘的使用会随着写入增加,deletePctAllowed 降低产生了放大效果。
所以,在没有大量数据支撑的条件下,ES 的使用者们往往会选择业务低峰期使用 forcemerge 来降低文档删除比,因为 forcemerge 的线程类型是 fixed,并且为 1,对 cpu 和磁盘的压力更加可控,同时 forcemerge 的 deletePctAllowed 默认阈值是 10%,更加低。
而社区中,大家的实际反馈则更倾向使用较低的 deletePctAllowed 阈值,特别是小索引小写入的情况下。
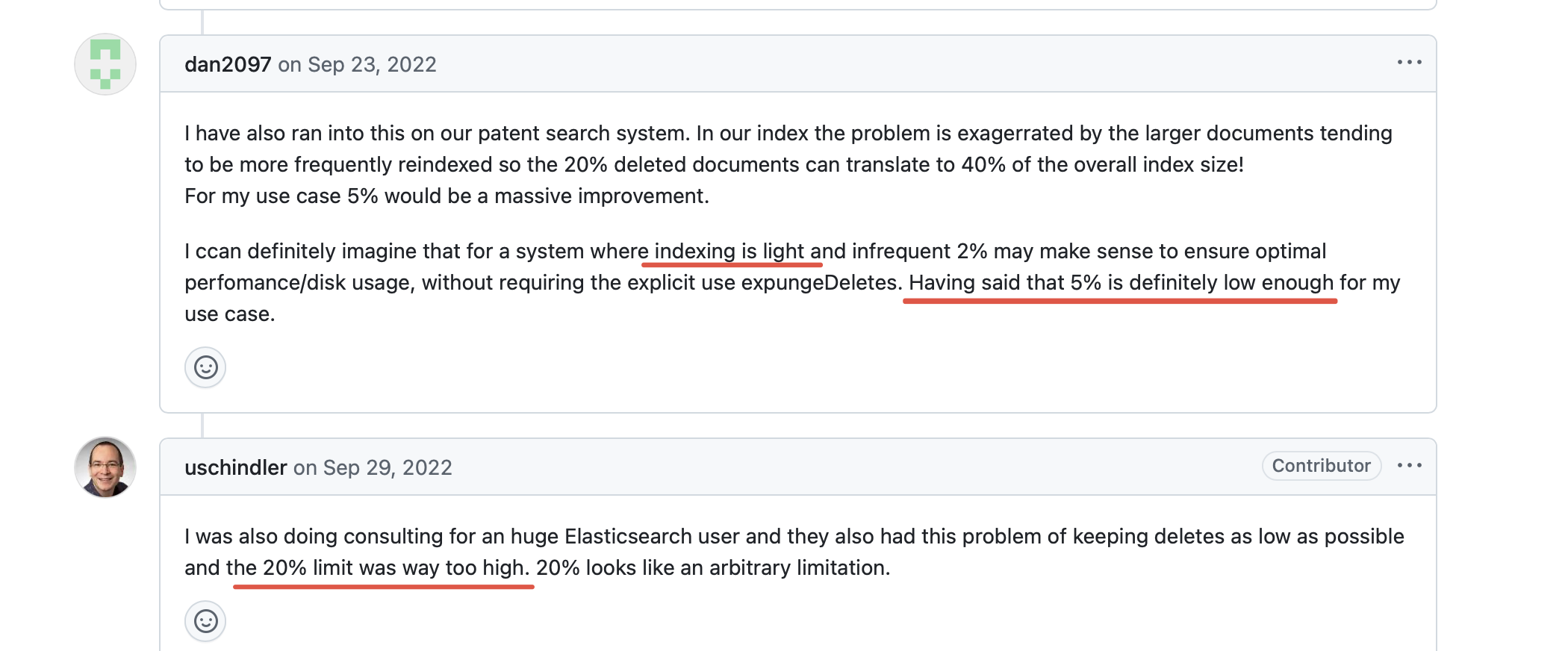
并且提供了相应的测试结果
#### RUN 1
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 50% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 39gb | 37gb |
| Deleted docs percent | 22% | 18% |
| Avg. CPU | (42 - 53)% | (43 - 55)% |
| Write throughput | 11 - 15 mbps | 11 - 17 mbps |
| Indexing latency | 0.15 - 0.36 ms | 0.15 - 0.39 ms |
| P90 search latency | 14.9 ms | 13.2 ms |
| P90 term query latency | 13.7 ms | 13.5 ms |
#### RUN 2
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 75% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 19.4gb | 17.7gb |
| Deleted docs percent | 22.8% | 15% |
| Avg. CPU | (43 - 53)% | (46 - 53)% |
| Write throughput | 9 - 14.5 mbps | 10 - 15.9 mbps |
| Indexing latency | 0.14 - 0.33 ms | 0.14 - 0.28 ms |
| P90 search latency | 15.9 ms | 13.5 ms |
| P90 term query latency | 15.7 ms | 13.9 ms |
#### RUN 3
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 80% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 15.9gb | 14.6gb |
| Deleted docs percent | 24% | 18% |
| Avg. CPU | (46 - 52)% | (47 - 52)% |
| Write throughput | 9 - 13 mbps | 10 - 15 mbps |
| Indexing latency | 0.14 - 0.28 ms | 0.13 - 0.26 ms |
| P90 search latency | 15.3 ms | 13.6 ms |
| P90 term query latency | 15.2 ms | 13.4 ms |
#### RUN 4
Test config:
Single node domain
Instance type: EC2 m5.2xlarge
Updates: 80% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 21.6gb | 17.8gb |
| Deleted docs percent | 30% | 18% |
| Avg. CPU | (71 - 89)% | (83 - 90)% |
| Write throughput | 6 - 12 mbps | 10 - 15 mbps |
| indexing latency | 0.21 - 0.30 ms | 0.20 - 0.31 ms |
| P90 search latency | 15.4 ms | 16.3 ms |
| P90 term query latency | 15.4 ms | 14.8 ms |
在测试中给出的结论是:
- CPU 和 IO 吞吐量没有明显增加。
- 由于索引中删除的文档数量较少,搜索延迟更少。
- 减少被删除文档占用的磁盘空间浪费
但是也需要注意,这里的测试索引和消耗资源并不大,有些业务量较大的索引还是需要重新做相关压力测试。
另一种调优思路
那除了降低 deletePctAllowed 和使用 forcemerge,还有其他方法么?
这里一个pr,提供一个综合性的解决方案,作者把两个 merge 策略进行了合并,在主动合并的间隙添加 forcemerge 检测方法,遇到可执行的时间段(资源使用率低),主动发起对单个 segment 的 forcemerge,这里 segment 得删选大小更加低,这样对 forcemerge 的任务耗时也更低,最终减少索引的删除文档占比。
简单的理解就是,利用了集群资源的“碎片时间”去完成主动的 forcemerge。也是一种可控且优质的调优方式。
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/index-merge-policy-deletepctallowed/
最近发现了 lucene 9.5 版本把 merge 策略的默认参数改了。
* GITHUB#11761: TieredMergePolicy now allowed a maximum allowable deletes percentage of down to 5%, and the default
maximum allowable deletes percentage is changed from 33% to 20%. (Marc D'Mello)也就是 index.merge.policy.deletePctAllowed 最小值可以取 5%(原来是 20%),而默认值为 20%(原来是 33%)。
这是一个控制索引中已删除文档的占比的参数,简单来说,调低这个参数能够降低存储大小,同时也需要更多的 cpu 和内存资源来完成这个调优。
通过这个帖子的讨论,大家可以发现,“实践出真知”,这次的参数调整是 lucene 社区对于用户积极反馈的采纳。因此,对于老版本的用户,也可以在 deletepct 比较高的场景下,调优这个参数,当然一切生产调整都需要经过测试。
对于 ES 的新用户来说,这时候可能冒出了下面这些问题
- 这个参数反馈的已删除文档占比 deletepct 是什么?
- 它怎么计算的呢?较高的 deletepct 会有什么影响?
- 较低的 deletepct 为什么会有更多的资源消耗?
- 除了调优这个参数还有什么优化办法么?
伴随这些问题,来探讨一下这个参数的来源和作用。
deletePctAllowed:软删除的遗留
在 Lucene 中,软删除是一种标记文档以便后续逻辑删除的机制,而不是立即从索引中物理删除文档。
但是这些软删除文档又不是永久存在的,deletePctAllowed 表示索引中允许存在的软删除文档占总文档数的最大百分比。
当软删除文档的比例达到或超过 deletePctAllowed 所设定的阈值时,Lucene 会触发索引合并操作。这是因为在合并过程中,那些被软删除的文档会被物理地从索引中移除,从而减少索引的存储空间占用。
当 deletePctAllowed 设置过低时,会频繁触发索引合并,因合并操作需大量磁盘 I/O、CPU 和内存资源,会使写入性能显著下降,磁盘 I/O 压力增大。假设 deletePctAllowed 为 0,则每次写入都需要消耗额外的资源来做 segment 的合并。
deletePctAllowed 过高,索引会容纳大量软删除文档,占用过多磁盘空间,增加存储成本且可能导致磁盘空间不足。查询时要过滤大量软删除文档,使查询响应时间变长、性能下降。同时也观察到,在使用 soft-deleted 特性后,文档更新和 refresh 也会受到影响,deletePctAllowed 过高,文档更新/refresh 操作耗时也会明显上升。
deletePctAllowed 的实际效果
从上面的解释看,index.merge.policy.deletePctAllowed 这个参数仿佛并不难理解,但实际上这个参数是应用到各个 segment 级别的,并且 segment 对这个参数的触发条件也是有限制(过小的 segment 并不会因为这个参数触发合并操作)。在多分片多 segment 的条件下,索引对 deletePctAllowed 参数实际的应用效果并不完全一致。因此,可以做个实际测试来看 deletePctAllowed 对索引产生的效果。
这里创建一个一千万文档的索引,然后全量更新一遍,看最后 deletePctAllowed 会保留多少的被删除文档。
GET test_del/_count
{
"count": 10000000,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
}
}
# 查看 delete 文档数量
GET test_del/_stats
···
"primaries": {
"docs": {
"count": 10000000,
"deleted": 0
},
···
这里的 deletePctAllowed 还是使用的 33%。
更新任务命令:
POST test_del/_update_by_query?wait_for_completion=false
{
"query": {
"match_all": {}
},
"script": {
"source": "ctx._source.field_name = 'new_value'",
"lang": "painless"
}
}完成后,
# 任务状态
···
"task": {
"node": "28HymM3xTESGMPRD3LvtCg",
"id": 10385666,
"type": "transport",
"action": "indices:data/write/update/byquery",
"status": {
"total": 10000000,
"updated": 10000000,# 这里可以看到全量更新
"created": 0,
"deleted": 0,
"batches": 10000,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0
}
···
# 索引的状态
GET test_del/_stats
···
"_all": {
"primaries": {
"docs": {
"count": 10000000,
"deleted": 809782
},
···实际删除文档与非删除文档的比例为 8.09%。
现在尝试调低 index.merge.policy.deletes_pct_allowed到 20%。
PUT test_del/_settings
{"index.merge.policy.deletes_pct_allowed":20}
由于之前删除文档占比过低,调整参数并不会触发新的 merge,因此需要重新全量更新数据查看一下是否有改变。
最终得到的索引状态如下:
GET test_del/_stats
···
"primaries": {
"docs": {
"count": 10000000,
"deleted": 190458
}
···这次得到的实际删除文档与非删除文档的比例为 1.9%
deletes_pct_allowed 默认值的调整
上面提到 deletePctAllowed 设置过低时,会频繁触发索引合并,而合并任务的线程使用线程类型是 SCALING 的,是一种动态扩展使用 cpu 的策略。
那么,当 deletePctAllowed 设置过低时,merge 任务增加,cpu 线程使用增加。集群的 cpu 和磁盘的使用会随着写入增加,deletePctAllowed 降低产生了放大效果。
所以,在没有大量数据支撑的条件下,ES 的使用者们往往会选择业务低峰期使用 forcemerge 来降低文档删除比,因为 forcemerge 的线程类型是 fixed,并且为 1,对 cpu 和磁盘的压力更加可控,同时 forcemerge 的 deletePctAllowed 默认阈值是 10%,更加低。
而社区中,大家的实际反馈则更倾向使用较低的 deletePctAllowed 阈值,特别是小索引小写入的情况下。
并且提供了相应的测试结果
#### RUN 1
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 50% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 39gb | 37gb |
| Deleted docs percent | 22% | 18% |
| Avg. CPU | (42 - 53)% | (43 - 55)% |
| Write throughput | 11 - 15 mbps | 11 - 17 mbps |
| Indexing latency | 0.15 - 0.36 ms | 0.15 - 0.39 ms |
| P90 search latency | 14.9 ms | 13.2 ms |
| P90 term query latency | 13.7 ms | 13.5 ms |
#### RUN 2
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 75% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 19.4gb | 17.7gb |
| Deleted docs percent | 22.8% | 15% |
| Avg. CPU | (43 - 53)% | (46 - 53)% |
| Write throughput | 9 - 14.5 mbps | 10 - 15.9 mbps |
| Indexing latency | 0.14 - 0.33 ms | 0.14 - 0.28 ms |
| P90 search latency | 15.9 ms | 13.5 ms |
| P90 term query latency | 15.7 ms | 13.9 ms |
#### RUN 3
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 80% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 15.9gb | 14.6gb |
| Deleted docs percent | 24% | 18% |
| Avg. CPU | (46 - 52)% | (47 - 52)% |
| Write throughput | 9 - 13 mbps | 10 - 15 mbps |
| Indexing latency | 0.14 - 0.28 ms | 0.13 - 0.26 ms |
| P90 search latency | 15.3 ms | 13.6 ms |
| P90 term query latency | 15.2 ms | 13.4 ms |
#### RUN 4
Test config:
Single node domain
Instance type: EC2 m5.2xlarge
Updates: 80% of the total request
Baseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"
| Metrics | Baseline | Target |
------------------------------------
| Store size | 21.6gb | 17.8gb |
| Deleted docs percent | 30% | 18% |
| Avg. CPU | (71 - 89)% | (83 - 90)% |
| Write throughput | 6 - 12 mbps | 10 - 15 mbps |
| indexing latency | 0.21 - 0.30 ms | 0.20 - 0.31 ms |
| P90 search latency | 15.4 ms | 16.3 ms |
| P90 term query latency | 15.4 ms | 14.8 ms |
在测试中给出的结论是:
- CPU 和 IO 吞吐量没有明显增加。
- 由于索引中删除的文档数量较少,搜索延迟更少。
- 减少被删除文档占用的磁盘空间浪费
但是也需要注意,这里的测试索引和消耗资源并不大,有些业务量较大的索引还是需要重新做相关压力测试。
另一种调优思路
那除了降低 deletePctAllowed 和使用 forcemerge,还有其他方法么?
这里一个pr,提供一个综合性的解决方案,作者把两个 merge 策略进行了合并,在主动合并的间隙添加 forcemerge 检测方法,遇到可执行的时间段(资源使用率低),主动发起对单个 segment 的 forcemerge,这里 segment 得删选大小更加低,这样对 forcemerge 的任务耗时也更低,最终减少索引的删除文档占比。
简单的理解就是,利用了集群资源的“碎片时间”去完成主动的 forcemerge。也是一种可控且优质的调优方式。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/index-merge-policy-deletepctallowed/
【搜索客社区日报】第2039期 (2025-05-16)
https://infinilabs.cn/blog/202 ... owed/
2、Elasticsearch 向量搜索实战:从基础到进阶
https://mp.weixin.qq.com/s/y3M2S_48Np1ump9q2ByoJA
3、向量搜索遇上过滤筛选,如何选择最优索引组合?
https://mp.weixin.qq.com/s/gc_3jLxI78z-OvhRKJfhXQ
4、【老杨玩搜索】17. Easysearch 可搜索快照
https://www.bilibili.com/video/BV1gpwpe5EBD
5、亿级核心表如何优雅扩展字段?中台团队实战经验揭秘
https://mp.weixin.qq.com/s/KcN7HhUZCWDm2rdHHRsIQQ
编辑:Fred
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... owed/
2、Elasticsearch 向量搜索实战:从基础到进阶
https://mp.weixin.qq.com/s/y3M2S_48Np1ump9q2ByoJA
3、向量搜索遇上过滤筛选,如何选择最优索引组合?
https://mp.weixin.qq.com/s/gc_3jLxI78z-OvhRKJfhXQ
4、【老杨玩搜索】17. Easysearch 可搜索快照
https://www.bilibili.com/video/BV1gpwpe5EBD
5、亿级核心表如何优雅扩展字段?中台团队实战经验揭秘
https://mp.weixin.qq.com/s/KcN7HhUZCWDm2rdHHRsIQQ
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2038期 (2025-05-15)
https://mp.weixin.qq.com/s/jrDTfuFM5-8X3CpNN4A3eg
2.宣布 OpenSearch 3.0 发布
https://mp.weixin.qq.com/s/B8fYm7fiBtk4erZWTdqf1A
3.a16z重磅预判:AI时代正在重写开发逻辑,这9个新范式将决定下一个技术十年
https://mp.weixin.qq.com/s/MGthNyHHlD4lERzDluMc1g
4.AI 推理 | vLLM 快速部署指南
https://mp.weixin.qq.com/s/rVW6jjLQabHGMMwnbIzB7Q
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/jrDTfuFM5-8X3CpNN4A3eg
2.宣布 OpenSearch 3.0 发布
https://mp.weixin.qq.com/s/B8fYm7fiBtk4erZWTdqf1A
3.a16z重磅预判:AI时代正在重写开发逻辑,这9个新范式将决定下一个技术十年
https://mp.weixin.qq.com/s/MGthNyHHlD4lERzDluMc1g
4.AI 推理 | vLLM 快速部署指南
https://mp.weixin.qq.com/s/rVW6jjLQabHGMMwnbIzB7Q
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »

