

【搜索客社区日报】第2074期 (2025-07-14)
https://elasticstack.blog.csdn ... 73363
2、使用 Maximum Marginal Relevance 实现搜索结果多样化
https://elasticstack.blog.csdn ... 69341
3、上下文更长 ≠ 更好:为什么 RAG 仍然重要
https://elasticstack.blog.csdn ... 88509
4、Logstash 9.x 与早期版本差异及常见问题解决方案
https://mp.weixin.qq.com/s/08dzlC5wKsfi_5JkaSN26Q
5、ChatBI:让数据分析像聊天一样简单!
https://mp.weixin.qq.com/s/W8sEEIphNE7ot5T2oY5qVA
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 73363
2、使用 Maximum Marginal Relevance 实现搜索结果多样化
https://elasticstack.blog.csdn ... 69341
3、上下文更长 ≠ 更好:为什么 RAG 仍然重要
https://elasticstack.blog.csdn ... 88509
4、Logstash 9.x 与早期版本差异及常见问题解决方案
https://mp.weixin.qq.com/s/08dzlC5wKsfi_5JkaSN26Q
5、ChatBI:让数据分析像聊天一样简单!
https://mp.weixin.qq.com/s/W8sEEIphNE7ot5T2oY5qVA
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
极限科技荣获 2025 上海开源创新菁英荟「开源创新新星企业」奖
2025 年 6 月 28 日,由上海开源信息技术协会主办、上海对外经贸大学承办的“2025 上海开源创新菁英荟”圆满落幕。本届大会以“开源有 AI,智领千行”为主题,汇聚开源社区、科研机构及产业界 200 余位专家,共同探讨开源技术如何赋能千行百业智能化转型。会上揭晓了四大类奖项,极限科技凭借其开源项目 Coco AI 脱颖而出,荣获「开源创新新星企业」奖项,得到了行业权威认可。


统一搜索 + 私有部署,Coco AI 直击企业三大痛点
现代企业面临数据分散、安全风险高、知识利用率低三大核心痛点。Coco AI 作为一款完全开源、跨平台的企业级智能搜索与助手系统,通过三大创新解决行业难题:
- 统一搜索入口,跨平台连接数据
支持连接本地文件、云存储(S3)、协作工具(Notion、Google Workspace)、知识平台(语雀)、代码仓库(GitHub)等多种数据源,实现一站式搜索与信息聚合。 - 私有化部署,保障数据安全
完全开源且支持自主可控部署,数据全程留存于企业内网,满足高安全、高合规场景需求。 - 融合大模型,构建智能助手
接入 DeepSeek、通义千问等先进大模型,支持语义理解、自然语言问答、智能推荐,激活沉睡数据,打造真正“会思考”的企业知识中枢。
开源生态赋能,推动 AI 普惠化
作为国内少数以搜索技术为核心的初创企业,极限科技始终践行“让搜索更简单”的使命。其开源项目 Coco AI(MIT 许可证)允许自由修改与分发,服务端(AGPL-3.0)要求公开源代码以确保合规,降低企业使用门槛。通过开源生态与 AI 技术,将企业离散数据转化为可搜索、可问答、可决策的活资产。
未来展望:躬身开源,共筑智能时代
此次获奖不仅是对极限科技在开源领域创新实践的高度认可,更是对其未来发展的激励。极限科技将继续积极投身开源实践,不断优化和创新 Coco AI,为更多企业提供高效、安全、智能的解决方案,推动企业从“数据沉睡时代”迈向“知识智能时代”。同时,极限科技还将加强与开源社区的合作,吸引更多开发者参与开源项目的开发和维护,共同推动开源技术的发展和应用。
关于 Coco AI - 为现代团队打造的统一搜索与 AI 智能助手
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
官网:https://coco.rs
GitHub:https://github.com/infinilabs
2025 年 6 月 28 日,由上海开源信息技术协会主办、上海对外经贸大学承办的“2025 上海开源创新菁英荟”圆满落幕。本届大会以“开源有 AI,智领千行”为主题,汇聚开源社区、科研机构及产业界 200 余位专家,共同探讨开源技术如何赋能千行百业智能化转型。会上揭晓了四大类奖项,极限科技凭借其开源项目 Coco AI 脱颖而出,荣获「开源创新新星企业」奖项,得到了行业权威认可。
统一搜索 + 私有部署,Coco AI 直击企业三大痛点
现代企业面临数据分散、安全风险高、知识利用率低三大核心痛点。Coco AI 作为一款完全开源、跨平台的企业级智能搜索与助手系统,通过三大创新解决行业难题:
- 统一搜索入口,跨平台连接数据
支持连接本地文件、云存储(S3)、协作工具(Notion、Google Workspace)、知识平台(语雀)、代码仓库(GitHub)等多种数据源,实现一站式搜索与信息聚合。 - 私有化部署,保障数据安全
完全开源且支持自主可控部署,数据全程留存于企业内网,满足高安全、高合规场景需求。 - 融合大模型,构建智能助手
接入 DeepSeek、通义千问等先进大模型,支持语义理解、自然语言问答、智能推荐,激活沉睡数据,打造真正“会思考”的企业知识中枢。
开源生态赋能,推动 AI 普惠化
作为国内少数以搜索技术为核心的初创企业,极限科技始终践行“让搜索更简单”的使命。其开源项目 Coco AI(MIT 许可证)允许自由修改与分发,服务端(AGPL-3.0)要求公开源代码以确保合规,降低企业使用门槛。通过开源生态与 AI 技术,将企业离散数据转化为可搜索、可问答、可决策的活资产。
未来展望:躬身开源,共筑智能时代
此次获奖不仅是对极限科技在开源领域创新实践的高度认可,更是对其未来发展的激励。极限科技将继续积极投身开源实践,不断优化和创新 Coco AI,为更多企业提供高效、安全、智能的解决方案,推动企业从“数据沉睡时代”迈向“知识智能时代”。同时,极限科技还将加强与开源社区的合作,吸引更多开发者参与开源项目的开发和维护,共同推动开源技术的发展和应用。
关于 Coco AI - 为现代团队打造的统一搜索与 AI 智能助手
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
官网:https://coco.rs
GitHub:https://github.com/infinilabs
【搜索客社区日报】第2073期 (2025-07-11)
https://my.oschina.net/u/58463 ... 84272
2、Elasticsearch 在滴滴的应用与实践
https://mp.weixin.qq.com/s/nSnRH9MaG1_klI2IOJ_FuQ
3、OpenSearch 3.0发布,支持向量类型和MCP协议
https://mp.weixin.qq.com/s/Ge8-VEhN3tJf5aoU8X98RA
4、使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建
https://infinilabs.cn/blog/202 ... pose/
5、AI 深度研究(Deep Research)原理解析
https://my.oschina.net/u/58463 ... 83971
编辑:Fred
更多资讯:http://news.searchkit.cn
https://my.oschina.net/u/58463 ... 84272
2、Elasticsearch 在滴滴的应用与实践
https://mp.weixin.qq.com/s/nSnRH9MaG1_klI2IOJ_FuQ
3、OpenSearch 3.0发布,支持向量类型和MCP协议
https://mp.weixin.qq.com/s/Ge8-VEhN3tJf5aoU8X98RA
4、使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建
https://infinilabs.cn/blog/202 ... pose/
5、AI 深度研究(Deep Research)原理解析
https://my.oschina.net/u/58463 ... 83971
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2072期 (2025-07-10)
https://mp.weixin.qq.com/s/d0or_1U4TLVUKpK0vZAl2A
2.PerfTracker:万卡 GPU 集群超大规模训练性能问题定位利器!100万GPU 定位仅 3 分钟,7 分钟端到端性能诊断
https://mp.weixin.qq.com/s/YEs41WBJOY6hAG_G7Luf7A
3.OME:用模型驱动架构革新 LLM 基础设施
https://lmsys.org/blog/2025-07-08-ome
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/d0or_1U4TLVUKpK0vZAl2A
2.PerfTracker:万卡 GPU 集群超大规模训练性能问题定位利器!100万GPU 定位仅 3 分钟,7 分钟端到端性能诊断
https://mp.weixin.qq.com/s/YEs41WBJOY6hAG_G7Luf7A
3.OME:用模型驱动架构革新 LLM 基础设施
https://lmsys.org/blog/2025-07-08-ome
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2070期 (2025-07-08)
https://satorsight.medium.com/ ... 5c536
2. 用docker构建elastic 全家(需要梯子)
https://medium.com/%40kaviaras ... acb13
3. 不用es,直接用nodejs手搓搜索引擎行吗?(需要梯子)
https://leapcell.medium.com/st ... 86f28
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://satorsight.medium.com/ ... 5c536
2. 用docker构建elastic 全家(需要梯子)
https://medium.com/%40kaviaras ... acb13
3. 不用es,直接用nodejs手搓搜索引擎行吗?(需要梯子)
https://leapcell.medium.com/st ... 86f28
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2071期 (2025-07-9)
https://medium.com/data-scienc ... 35d27
2.Cursor 如何每秒处理一百万次矢量搜索查询(搭梯)
https://medium.com/kx-systems/ ... 06ec1
3.以视觉答案为基础的多模态 RAG(搭梯)
https://medium.com/data-scienc ... 86c88
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/data-scienc ... 35d27
2.Cursor 如何每秒处理一百万次矢量搜索查询(搭梯)
https://medium.com/kx-systems/ ... 06ec1
3.以视觉答案为基础的多模态 RAG(搭梯)
https://medium.com/data-scienc ... 86c88
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2069期 (2025-07-07)
https://mp.weixin.qq.com/s/XxlLMXAOVI9mTpkUIMmlQw
2、Elasticsearch 排序性能提升高达 900 倍
https://mp.weixin.qq.com/s/OAVYa_w0fAug9AiwdWPkeg
3、三个数据处理技巧,永远改变你的搜索体验
https://mp.weixin.qq.com/s/9p9rZwEI4Mieimw3cJWjxg
4、Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用
https://mp.weixin.qq.com/s/ia92pszO8ed98D4vOZ57pQ
5、使用 collapse 和 cardinality 实现高效分页在 Elasticsearch 中
https://elasticstack.blog.csdn ... 32271
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/XxlLMXAOVI9mTpkUIMmlQw
2、Elasticsearch 排序性能提升高达 900 倍
https://mp.weixin.qq.com/s/OAVYa_w0fAug9AiwdWPkeg
3、三个数据处理技巧,永远改变你的搜索体验
https://mp.weixin.qq.com/s/9p9rZwEI4Mieimw3cJWjxg
4、Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用
https://mp.weixin.qq.com/s/ia92pszO8ed98D4vOZ57pQ
5、使用 collapse 和 cardinality 实现高效分页在 Elasticsearch 中
https://elasticstack.blog.csdn ... 32271
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2068期 (2025-07-03)
https://mp.weixin.qq.com/s/CoFyJMX7cHEKUFSSbKtvZQ
2.14G 显存跑动千亿大模型!基于 KTransformers 的 DeepSeek-R1'满血版'实战
https://mp.weixin.qq.com/s/XIsVYxQgp2tCbWHFFb95xg
3.Muon作者仅用一篇博客,就被OpenAI看中了
https://mp.weixin.qq.com/s/Ijez32vojwSuyJkycKJQ9g
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/CoFyJMX7cHEKUFSSbKtvZQ
2.14G 显存跑动千亿大模型!基于 KTransformers 的 DeepSeek-R1'满血版'实战
https://mp.weixin.qq.com/s/XIsVYxQgp2tCbWHFFb95xg
3.Muon作者仅用一篇博客,就被OpenAI看中了
https://mp.weixin.qq.com/s/Ijez32vojwSuyJkycKJQ9g
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2067期 (2025-07-02)
https://elasticstack.blog.csdn ... 88999
2.NVIDIA 表示小型语言模型是 Agentic AI 的未来(搭梯)
https://cobusgreyling.medium.c ... d9565
3.使用 Gemini 2.0 Flash 对数百万份文档进行提取和 RAG(搭梯)
https://ai.gopubby.com/10x-che ... b3b54
编辑:kin122
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 88999
2.NVIDIA 表示小型语言模型是 Agentic AI 的未来(搭梯)
https://cobusgreyling.medium.c ... d9565
3.使用 Gemini 2.0 Flash 对数百万份文档进行提取和 RAG(搭梯)
https://ai.gopubby.com/10x-che ... b3b54
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
INFINI Labs 产品更新 | Coco AI v0.6 发布 - 插件商店上线

INFINI Labs 产品更新发布!此次更新涵盖 Coco AI 、Easysearch 等产品多项重要升级,其中 Coco AI 新增插件商店,方便用户安装和卸载插件,重构了搜索 API,优化聊天展示等,进一步提升 AI 搜索能力、易用性。
以下为详细更新介绍:
Coco AI v0.6
Coco AI 是一款完全开源、专注于混合云平台的企业级 AI 搜索与智能助手系统。它通过统一搜索入口,连接企业内外部的异构数据源,颠覆了企业访问和获取信息的方式和途径;同时 Coco AI 利用大模型能力和机器学习技术,能够为每个用户创建个性化知识图谱,进而优化个人及公司决策协作流程。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.6
功能更新
-
添加插件商店 #699
- 历史列表支持快捷键操作(选择、删除等) #700
- 添加 「检查更新」按钮 #701
- 添加 app 索引重建按钮来索引最新的 app #719
问题修复
- 快速 AI 状态进行同步 #693
- 打开/关闭插件应该也设置/取消快捷键 #691
- 在 refresh 时,将在线的 Coco server 重新添加会搜索列表 #696
- 输入框支持空格输入进行检索 #709
- 搜索右键菜单失效问题 #713
- 搜索窗口在搜索界面,底边栏提示消息错误的问题 #722
优化改进
- 插件的唯一标识变更为「作者 ID/插件 ID」 #643
- 重构了搜索 API #679
- 继续聊天展示优化 #690
- 服务器列表支持快捷键 enter 选择 #692
- 添加最新版本检查消息展示 #703
- 在日志中记录插件命令的执行结果 #718
Coco AI 服务端 v0.6
问题修复
- 从 assistant search 中移除 manually_renamed_title
INFINI Easysearch v1.13.1
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
- 插件模块新增 dependencyModule 配置项,用于声明共享的 common 模块依赖
问题修复
- 修复了前缀查询请求在只包含一个字符时的空指针错误
优化改进
- 精简了部署后的 modules 和 plugins 大小
INFINI Framework v1.1.9
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
问题修复
- 没有响应体的 response 不允许携带 trailers(#158)
优化改进
- 重构错误处理逻辑 (#157)
- 更新 Makefile (#156)
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Console
- INFINI Gateway
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新发布!此次更新涵盖 Coco AI 、Easysearch 等产品多项重要升级,其中 Coco AI 新增插件商店,方便用户安装和卸载插件,重构了搜索 API,优化聊天展示等,进一步提升 AI 搜索能力、易用性。
以下为详细更新介绍:
Coco AI v0.6
Coco AI 是一款完全开源、专注于混合云平台的企业级 AI 搜索与智能助手系统。它通过统一搜索入口,连接企业内外部的异构数据源,颠覆了企业访问和获取信息的方式和途径;同时 Coco AI 利用大模型能力和机器学习技术,能够为每个用户创建个性化知识图谱,进而优化个人及公司决策协作流程。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.6
功能更新
-
添加插件商店 #699
- 历史列表支持快捷键操作(选择、删除等) #700
- 添加 「检查更新」按钮 #701
- 添加 app 索引重建按钮来索引最新的 app #719
问题修复
- 快速 AI 状态进行同步 #693
- 打开/关闭插件应该也设置/取消快捷键 #691
- 在 refresh 时,将在线的 Coco server 重新添加会搜索列表 #696
- 输入框支持空格输入进行检索 #709
- 搜索右键菜单失效问题 #713
- 搜索窗口在搜索界面,底边栏提示消息错误的问题 #722
优化改进
- 插件的唯一标识变更为「作者 ID/插件 ID」 #643
- 重构了搜索 API #679
- 继续聊天展示优化 #690
- 服务器列表支持快捷键 enter 选择 #692
- 添加最新版本检查消息展示 #703
- 在日志中记录插件命令的执行结果 #718
Coco AI 服务端 v0.6
问题修复
- 从 assistant search 中移除 manually_renamed_title
INFINI Easysearch v1.13.1
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
功能更新
- 插件模块新增 dependencyModule 配置项,用于声明共享的 common 模块依赖
问题修复
- 修复了前缀查询请求在只包含一个字符时的空指针错误
优化改进
- 精简了部署后的 modules 和 plugins 大小
INFINI Framework v1.1.9
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
问题修复
- 没有响应体的 response 不允许携带 trailers(#158)
优化改进
- 重构错误处理逻辑 (#157)
- 更新 Makefile (#156)
更多详情请查看以下详细的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Console
- INFINI Gateway
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »一键启动:使用 start-local 脚本轻松管理 INFINI Console 与 Easysearch 本地环境
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
虽然 Docker Compose 已经极大地提升了便利性,但在实际的开发和测试流程中,我们可能还需要处理版本选择、初始配置复制、多节点配置、指标采集开启等更细致的需求。为了进一步封装这些复杂性,提供真正的一键式体验,我们精心打造了一个强大的 Shell 脚本 start-local 。
本篇文章将带你领略 start-local 的魅力,看看它是如何将 Console 和 Easysearch (本文仍以 Console 1.29.6 和 Easysearch 1.13.0 为例) 的本地环境搭建与管理提升到一个全新的便捷高度——只需一行命令,即可拥有一个功能完备、数据持久的本地 INFINI Console 运行环境。
start-local:您的 INFINI Console 本地环境瑞士军刀
start-local 脚本(灵感来源于 elastic/start-local)集成了环境搭建的诸多最佳实践,旨在提供极致的易用性。它在后台仍然依赖 Docker 和 Docker Compose,但为用户屏蔽了底层的复杂配置细节。
核心功能:
- 智能版本管理:自动获取 INFINI Console 和 Easysearch 的最新稳定版(或你指定的版本)作为默认镜像标签。
- 动态配置生成:根据用户提供的命令行选项(如节点数、密码、版本等)自动生成
.env和docker-compose.yml文件。 - 初始配置自动处理:在首次启动或本地配置目录不存在时,自动从 Docker 镜像中提取并设置初始配置文件。
- 一键式生命周期管理:通过简单的命令 (
up,down,logs,clean) 管理整个应用的启动、停止、日志查看和彻底清理。 - 持久化内置:默认将所有关键数据(配置、索引数据、日志)持久化到本地的
./startlocal目录(可配置)。 - 集成 Agent 指标采集:通过
--metrics-agent选项,轻松启用 Easysearch 的指标收集并自动配置其指向 INFINI Console。 - 跨平台设计:主要针对 Linux 和 macOS 环境。
如何获取和使用 start-local
获取和执行 start-local 最便捷的方式是通过 curl 将脚本内容直接通过管道传递给 sh 执行:
# 启动默认配置 (Console + 1 个 Easysearch 节点)
curl -fsSL http://get.infini.cloud/start-local | sh -s
# 想要更丰富的体验?试试这个:
# 启动 3 个 Easysearch 节点,设置密码,并开启 Agent 指标采集
curl -fsSL http://get.infini.cloud/start-local | sh -s -- up --nodes 3 --password "MyDevPass123." --metrics-agent(请将 http://get.infini.cloud/start-local 替换为脚本的实际官方获取地址)
sh -s -- 部分确保脚本从标准输入读取,并且后续参数能正确传递给脚本。
脚本执行后,所有操作文件和持久化数据都会在当前目录下的 ./startlocal (默认) 子目录中创建和管理。
start-local 命令和选项概览
通过 help 命令可以查看所有支持的功能:
curl -fsSL http://get.infini.cloud/start-local | sh -s -- help以下是一些最常用的命令和选项:
命令 (COMMAND):
up: 核心命令。创建并启动定义的服务。自动处理初始配置。down: 停止服务,移除容器、网络和相关匿名卷。本地持久化数据不受影响。logs [服务名...]: 实时查看指定服务或所有服务的日志。clean: 彻底清理。执行down后,删除整个工作目录 (./startlocal及其所有内容)。help: 显示帮助信息。
常用选项 (OPTIONS) (主要用于 up 命令):
-cv TAG,--console-version TAG: 指定 Console 镜像版本 (例如1.29.6)。-ev TAG,--easysearch-version TAG: 指定 Easysearch 镜像版本 (例如1.13.0)。-n N,--nodes N: Easysearch 节点数量 (默认 1)。-p PASSWORD,--password PASSWORD: Easysearchadmin用户初始密码 (默认ShouldChangeme123.)。--services s1[,s2,...]: 指定要启动的服务 (可选值:console,easysearch)。如果未指定,默认启动两者。--metrics-agent: 启用 Easysearch 指标收集代理。-wd PATH,--work-dir PATH: 自定义工作目录,替代默认的./startlocal。
实际操作示例
让我们通过几个示例来感受 start-local 的便捷:
1. 启动一个标准的开发环境 (Console + 1 个 Easysearch 节点,开启指标)
curl -fsSL http://get.infini.cloud/start-local | sh -s脚本会自动完成所有后台工作:检查依赖、确定版本、创建工作目录、生成配置文件、复制初始配置、生成 docker-compose.yml,最后启动服务并打印访问地址。
2. 启动一个 3 节点的 Easysearch 集群,并指定版本和密码
curl -fsSL http://get.infini.cloud/start-local | sh -s -- up \
--nodes 3 \
--password "ComplexP@ssw0rd." \
--console-version 1.29.6 \
--easysearch-version 1.13.0 \
--services easysearch,console脚本会智能处理多节点配置和持久化目录结构。
3. 查看所有服务的日志
curl -fsSL http://get.infini.cloud/start-local | sh -s -- logs4. 停止运行环境(慎重操作)
curl -fsSL http://get.infini.cloud/start-local | sh -s -- down这将停止运行的所有容器。
4. 删除运行环境(慎重操作)
curl -fsSL http://get.infini.cloud/start-local | sh -s -- clean这将移除所有相关的 Docker 资源以及本地的 ./startlocal 目录。
持久化:数据安全无忧
start-local 脚本的核心设计之一就是确保数据的持久化。所有重要的配置、数据和日志都会映射到宿主机的 ./startlocal (或你通过 -wd 指定的) 目录下的结构化子目录中:
- Console:
./startlocal/console/{config,data,logs}/ - Easysearch (单节点):
./startlocal/easysearch/{config,data,logs}/ - Easysearch (多节点):
./startlocal/easysearch/node-X/{config,data,logs}/
这意味着你可以随时 down 和 up 你的环境,而不用担心丢失任何工作。
访问服务
启动成功后,脚本会打印出访问地址:
- INFINI Console:
http://localhost:9000(默认主机端口) - INFINI Easysearch:
https://localhost:9200(默认主机端口,用户admin,密码为你设置的或默认值)
总结:从复杂到简单,专注核心价值
从繁琐的 docker run 命令,到结构化的 docker-compose.yml,再到如今便捷的 start-local 脚本,我们一步步简化了 INFINI 本地环境的搭建和管理过程。start-local 将所有底层的复杂性封装起来,让你能够通过一行命令就拥有一个功能齐全、数据持久的本地环境,从而更专注于应用本身的功能测试、开发和学习。
这正是良好工具的价值所在——让复杂的事情变简单,让我们能更高效地创造。
希望这个 start-local 脚本能成为你日常工作中得力的助手!如果你有任何建议或发现问题,欢迎通过项目仓库反馈。
关于 INFINI Console

INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。INFINI Console 还可以对集群内的索引及数据进行操作管理,可以配置灵活的告警规则,可以指定统一的安全策略,可以查看各个维度的日志和审计信息,真正实现企业级的搜索服务平台化建设和运营。
官网文档:https://docs.infinilabs.com/console/main/
开源地址:https://github.com/infinilabs/console
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:http://localhost:1313/blog/2025/console-easysearch-start-local/
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
虽然 Docker Compose 已经极大地提升了便利性,但在实际的开发和测试流程中,我们可能还需要处理版本选择、初始配置复制、多节点配置、指标采集开启等更细致的需求。为了进一步封装这些复杂性,提供真正的一键式体验,我们精心打造了一个强大的 Shell 脚本 start-local 。
本篇文章将带你领略 start-local 的魅力,看看它是如何将 Console 和 Easysearch (本文仍以 Console 1.29.6 和 Easysearch 1.13.0 为例) 的本地环境搭建与管理提升到一个全新的便捷高度——只需一行命令,即可拥有一个功能完备、数据持久的本地 INFINI Console 运行环境。
start-local:您的 INFINI Console 本地环境瑞士军刀
start-local 脚本(灵感来源于 elastic/start-local)集成了环境搭建的诸多最佳实践,旨在提供极致的易用性。它在后台仍然依赖 Docker 和 Docker Compose,但为用户屏蔽了底层的复杂配置细节。
核心功能:
- 智能版本管理:自动获取 INFINI Console 和 Easysearch 的最新稳定版(或你指定的版本)作为默认镜像标签。
- 动态配置生成:根据用户提供的命令行选项(如节点数、密码、版本等)自动生成
.env和docker-compose.yml文件。 - 初始配置自动处理:在首次启动或本地配置目录不存在时,自动从 Docker 镜像中提取并设置初始配置文件。
- 一键式生命周期管理:通过简单的命令 (
up,down,logs,clean) 管理整个应用的启动、停止、日志查看和彻底清理。 - 持久化内置:默认将所有关键数据(配置、索引数据、日志)持久化到本地的
./startlocal目录(可配置)。 - 集成 Agent 指标采集:通过
--metrics-agent选项,轻松启用 Easysearch 的指标收集并自动配置其指向 INFINI Console。 - 跨平台设计:主要针对 Linux 和 macOS 环境。
如何获取和使用 start-local
获取和执行 start-local 最便捷的方式是通过 curl 将脚本内容直接通过管道传递给 sh 执行:
# 启动默认配置 (Console + 1 个 Easysearch 节点)
curl -fsSL http://get.infini.cloud/start-local | sh -s
# 想要更丰富的体验?试试这个:
# 启动 3 个 Easysearch 节点,设置密码,并开启 Agent 指标采集
curl -fsSL http://get.infini.cloud/start-local | sh -s -- up --nodes 3 --password "MyDevPass123." --metrics-agent(请将 http://get.infini.cloud/start-local 替换为脚本的实际官方获取地址)
sh -s -- 部分确保脚本从标准输入读取,并且后续参数能正确传递给脚本。
脚本执行后,所有操作文件和持久化数据都会在当前目录下的 ./startlocal (默认) 子目录中创建和管理。
start-local 命令和选项概览
通过 help 命令可以查看所有支持的功能:
curl -fsSL http://get.infini.cloud/start-local | sh -s -- help以下是一些最常用的命令和选项:
命令 (COMMAND):
up: 核心命令。创建并启动定义的服务。自动处理初始配置。down: 停止服务,移除容器、网络和相关匿名卷。本地持久化数据不受影响。logs [服务名...]: 实时查看指定服务或所有服务的日志。clean: 彻底清理。执行down后,删除整个工作目录 (./startlocal及其所有内容)。help: 显示帮助信息。
常用选项 (OPTIONS) (主要用于 up 命令):
-cv TAG,--console-version TAG: 指定 Console 镜像版本 (例如1.29.6)。-ev TAG,--easysearch-version TAG: 指定 Easysearch 镜像版本 (例如1.13.0)。-n N,--nodes N: Easysearch 节点数量 (默认 1)。-p PASSWORD,--password PASSWORD: Easysearchadmin用户初始密码 (默认ShouldChangeme123.)。--services s1[,s2,...]: 指定要启动的服务 (可选值:console,easysearch)。如果未指定,默认启动两者。--metrics-agent: 启用 Easysearch 指标收集代理。-wd PATH,--work-dir PATH: 自定义工作目录,替代默认的./startlocal。
实际操作示例
让我们通过几个示例来感受 start-local 的便捷:
1. 启动一个标准的开发环境 (Console + 1 个 Easysearch 节点,开启指标)
curl -fsSL http://get.infini.cloud/start-local | sh -s脚本会自动完成所有后台工作:检查依赖、确定版本、创建工作目录、生成配置文件、复制初始配置、生成 docker-compose.yml,最后启动服务并打印访问地址。
2. 启动一个 3 节点的 Easysearch 集群,并指定版本和密码
curl -fsSL http://get.infini.cloud/start-local | sh -s -- up \
--nodes 3 \
--password "ComplexP@ssw0rd." \
--console-version 1.29.6 \
--easysearch-version 1.13.0 \
--services easysearch,console脚本会智能处理多节点配置和持久化目录结构。
3. 查看所有服务的日志
curl -fsSL http://get.infini.cloud/start-local | sh -s -- logs4. 停止运行环境(慎重操作)
curl -fsSL http://get.infini.cloud/start-local | sh -s -- down这将停止运行的所有容器。
4. 删除运行环境(慎重操作)
curl -fsSL http://get.infini.cloud/start-local | sh -s -- clean这将移除所有相关的 Docker 资源以及本地的 ./startlocal 目录。
持久化:数据安全无忧
start-local 脚本的核心设计之一就是确保数据的持久化。所有重要的配置、数据和日志都会映射到宿主机的 ./startlocal (或你通过 -wd 指定的) 目录下的结构化子目录中:
- Console:
./startlocal/console/{config,data,logs}/ - Easysearch (单节点):
./startlocal/easysearch/{config,data,logs}/ - Easysearch (多节点):
./startlocal/easysearch/node-X/{config,data,logs}/
这意味着你可以随时 down 和 up 你的环境,而不用担心丢失任何工作。
访问服务
启动成功后,脚本会打印出访问地址:
- INFINI Console:
http://localhost:9000(默认主机端口) - INFINI Easysearch:
https://localhost:9200(默认主机端口,用户admin,密码为你设置的或默认值)
总结:从复杂到简单,专注核心价值
从繁琐的 docker run 命令,到结构化的 docker-compose.yml,再到如今便捷的 start-local 脚本,我们一步步简化了 INFINI 本地环境的搭建和管理过程。start-local 将所有底层的复杂性封装起来,让你能够通过一行命令就拥有一个功能齐全、数据持久的本地环境,从而更专注于应用本身的功能测试、开发和学习。
这正是良好工具的价值所在——让复杂的事情变简单,让我们能更高效地创造。
希望这个 start-local 脚本能成为你日常工作中得力的助手!如果你有任何建议或发现问题,欢迎通过项目仓库反馈。
关于 INFINI Console
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。INFINI Console 还可以对集群内的索引及数据进行操作管理,可以配置灵活的告警规则,可以指定统一的安全策略,可以查看各个维度的日志和审计信息,真正实现企业级的搜索服务平台化建设和运营。
官网文档:https://docs.infinilabs.com/console/main/
开源地址:https://github.com/infinilabs/console
收起阅读 »作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:http://localhost:1313/blog/2025/console-easysearch-start-local/
使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建
前言回顾
在上一篇文章《搭建持久化的 INFINI Console 与 Easysearch 容器环境》中,我们详细介绍了如何使用基础的 docker run 命令,手动启动和配置 INFINI Console (1.29.6) 和 INFINI Easysearch (1.13.0) 容器,并实现了关键数据的持久化,解决了重启后配置丢失的问题。
手动操作虽然能让我们深入理解 Docker 的核心机制,但在管理多个容器、网络和卷时,命令会变得冗长且容易出错。这时,Docker Compose 就派上了用场。它允许我们使用一个 YAML 文件来定义和运行多容器 Docker 应用程序。
本篇文章将演示如何将上一篇的手动步骤转换为使用 Docker Compose,让你更轻松地管理和维护这套本地开发测试环境。
Docker Compose 的优势
使用 Docker Compose 带来了诸多好处:
- 声明式配置:在一个
docker-compose.yml文件中定义所有服务、网络和卷,清晰明了。 - 一键式管理:使用简单的命令(如
docker compose up,docker compose down)即可启动、停止和重建整个应用环境。 - 简化网络和服务连接:Compose 会自动处理服务间的网络设置和依赖关系。
- 易于共享和版本控制:
docker-compose.yml文件可以轻松地与团队共享并通过版本控制系统(如 Git)进行管理。
准备工作
与上一篇类似,你需要:
- 操作系统: macOS (本文示例)
- Docker 环境: OrbStack (https://orbstack.dev/) 或 Docker Desktop for Mac。
- 确保 Docker Compose V2 (
docker compose) 或 V1 (docker-compose) 已安装并可用。
查看
docker compose版本
docker compose version
Docker Compose version v2.24.5步骤一:项目目录结构
我们将继续使用上一篇文章中创建的目录结构。如果你还没有创建,或者想重新开始,可以在你的项目根目录(例如 ~/infini_compose_lab)下创建如下结构:
# 1. 创建项目根目录
mkdir -p ~/infini_compose_lab
cd ~/infini_compose_lab
# 2. 为 Console 和 Easysearch 创建持久化子目录
# 这些目录将用于存储配置、数据和日志
mkdir -p console/config console/data console/logs
mkdir -p easysearch/config easysearch/data easysearch/logs步骤二:提取初始配置文件
这一步与上一篇完全相同。你在首次启动时使用从镜像中提取的默认配置,请执行以下操作。如果这些目录中已存在配置文件(例如从上一篇博客的操作中保留下来的),Docker Compose 在挂载时会直接使用它们。
1. INFINI Console (1.29.6) 初始配置
(容器内配置路径: /config)
# 确保在 ~/infini_compose_lab 目录下
docker pull infinilabs/console:1.29.6
docker run --rm \
-v $PWD/console/config:/temp_host_config \
infinilabs/console:1.29.6 \
sh -c "cp -a /config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"2. INFINI Easysearch (1.13.0) 初始配置
(容器内配置路径: /app/easysearch/config,初始密码: INFINILabs01)
重要提示:请务必为 Easysearch 设置安全的密码。
# 确保在 ~/infini_compose_lab 目录下
docker pull infinilabs/easysearch:1.13.0
docker run --rm \
-e EASYSEARCH_INITIAL_ADMIN_PASSWORD="INFINILabs01" \
-v $PWD/easysearch/config:/temp_host_config \
infinilabs/easysearch:1.13.0 \
sh -c "cp -a /app/easysearch/config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"步骤三:创建 docker-compose.yml 文件
这是核心步骤。在你的项目根目录 ~/infini_compose_lab 下,创建一个名为 docker-compose.yml 的文件,并填入以下内容。这个文件定义了我们的服务、它们如何运行以及它们如何交互。
cat <<EOF > docker-compose.yml
services:
easysearch:
image: infinilabs/easysearch:1.13.0
container_name: infini-easysearch
environment:
- cluster.name=infini_compose_cluster
- node.name=node-01
- cluster.initial_master_nodes=node-01
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
- EASYSEARCH_INITIAL_ADMIN_PASSWORD=INFINILabs01
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./easysearch/config:/app/easysearch/config
- ./easysearch/data:/app/easysearch/data
- ./easysearch/logs:/app/easysearch/logs
ulimits:
memlock: {soft: -1, hard: -1}
nofile: {soft: 65536, hard: 65536}
networks:
- infini_app_net
console:
image: infinilabs/console:1.29.6
container_name: infini-console
ports:
- "9000:9000"
volumes:
- ./console/config:/config
- ./console/data:/data
- ./console/logs:/log
networks:
- infini_app_net
networks:
infini_app_net:
driver: bridge
EOFdocker-compose.yml 文件关键点:
services: 定义了easysearch和console两个服务。image: 指定了每个服务使用的 Docker 镜像和版本。container_name: 为容器指定一个易于识别的名称。environment: 设置容器的环境变量。- Easysearch 单节点配置: 注意
cluster.initial_master_nodes设置为节点自身的名称。 ports: 将容器的端口映射到宿主机的端口。volumes: 实现持久化的核心。将宿主机当前目录 (./) 下的console/*和easysearch/*子目录分别映射到容器内对应的路径。networks: 将两个服务都连接到我们定义的infini_app_net网络。这使得console服务可以通过服务名easysearch(例如https://easysearch:9200) 来访问easysearch服务。
步骤四:使用 Docker Compose 启动环境
现在,所有配置都在 docker-compose.yml 文件中了。启动整个环境只需要一条命令。
在 ~/infini_compose_lab 目录下(包含 docker-compose.yml 文件),执行:
docker compose up -ddocker compose(V2) 或docker-compose(V1)。up: 创建并启动在docker-compose.yml中定义的所有服务。-d: 后台模式运行。
首次运行时,如果本地没有对应的镜像,Docker Compose 会自动拉取。
常用 Docker Compose 命令:
- 查看服务状态:
docker compose ps- 查看所有服务的实时日志:
docker compose logs -f- 查看特定服务的日志:
docker compose logs -f console
docker compose logs -f easysearch- 停止所有服务(保留数据):
docker compose stop- 停止并移除所有容器、网络和匿名卷(保留通过
volumes映射的本地数据):
docker compose down步骤五:验证和使用
- 访问 Console: 浏览器打开
http://localhost:9000。 - 进行配置: 在 Console 中连接 Easysearch (
https://easysearch:9200,因为它们在同一个 Docker 网络中,可以直接使用服务名),创建用户,查看监控等。 - 测试持久化:
docker compose down # 停止并移除容器
# 稍等片刻
docker compose up -d # 重新启动再次访问 http://localhost:9000,你会发现之前的配置都还在!
操作截图
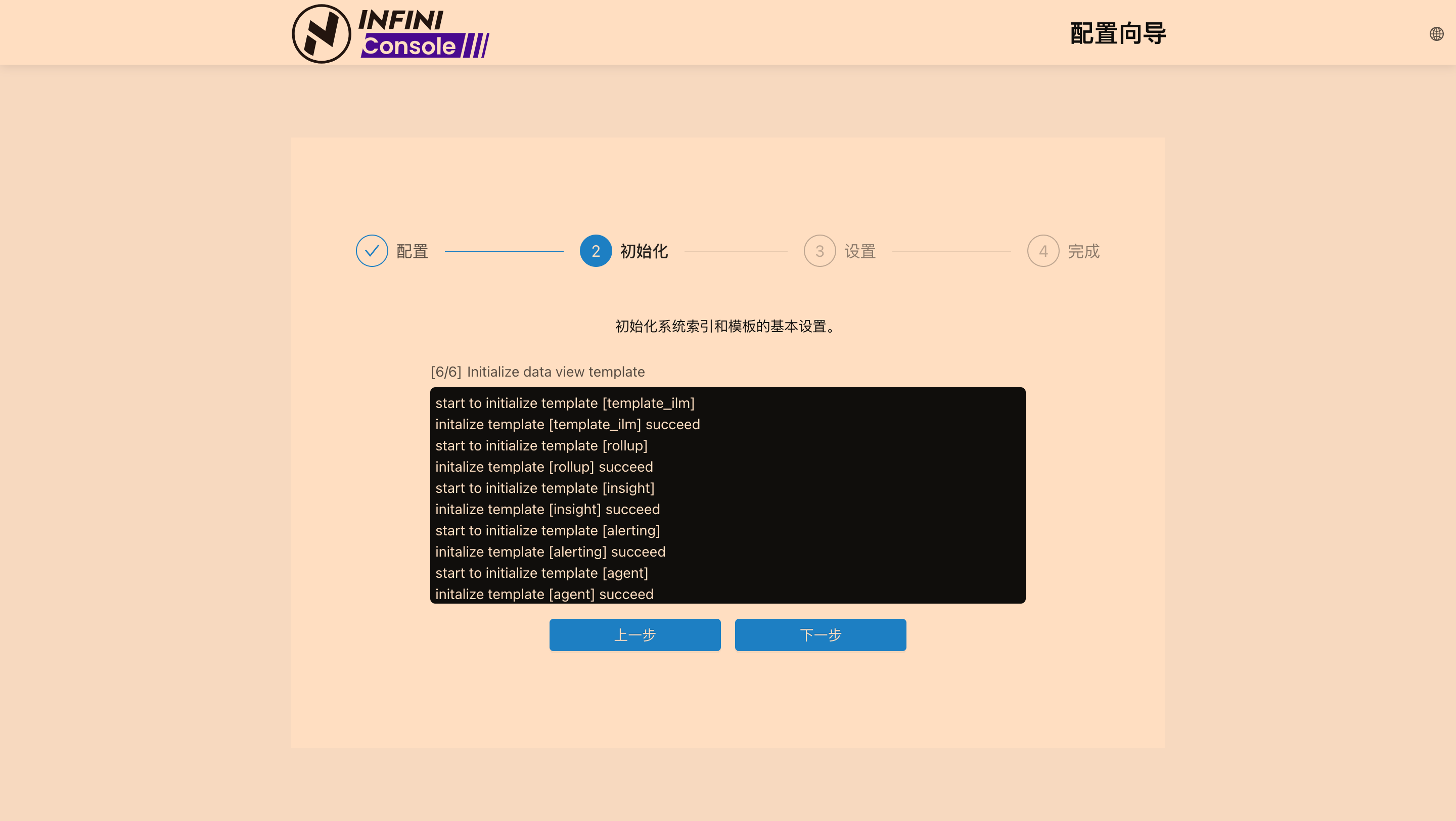
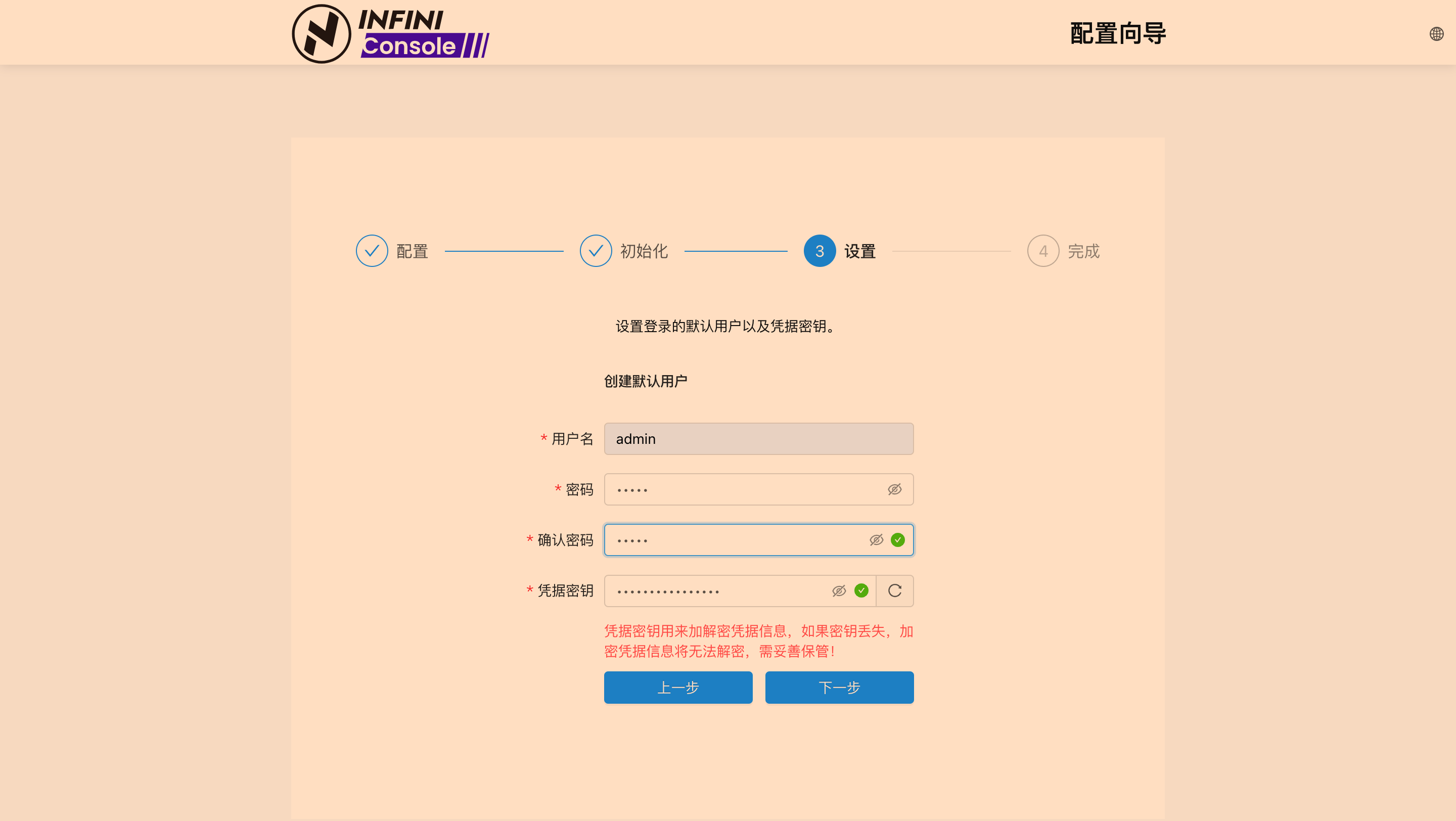
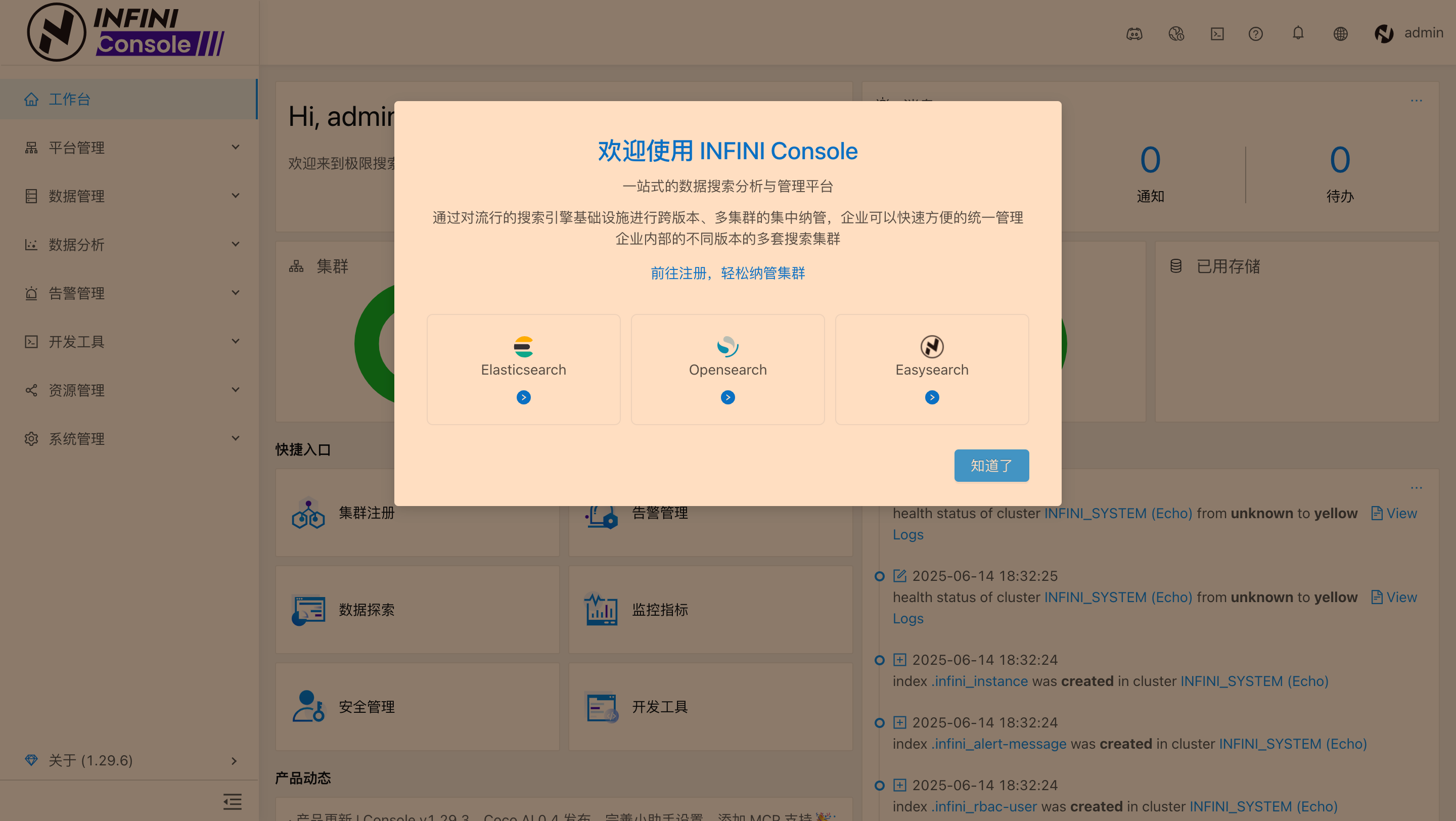
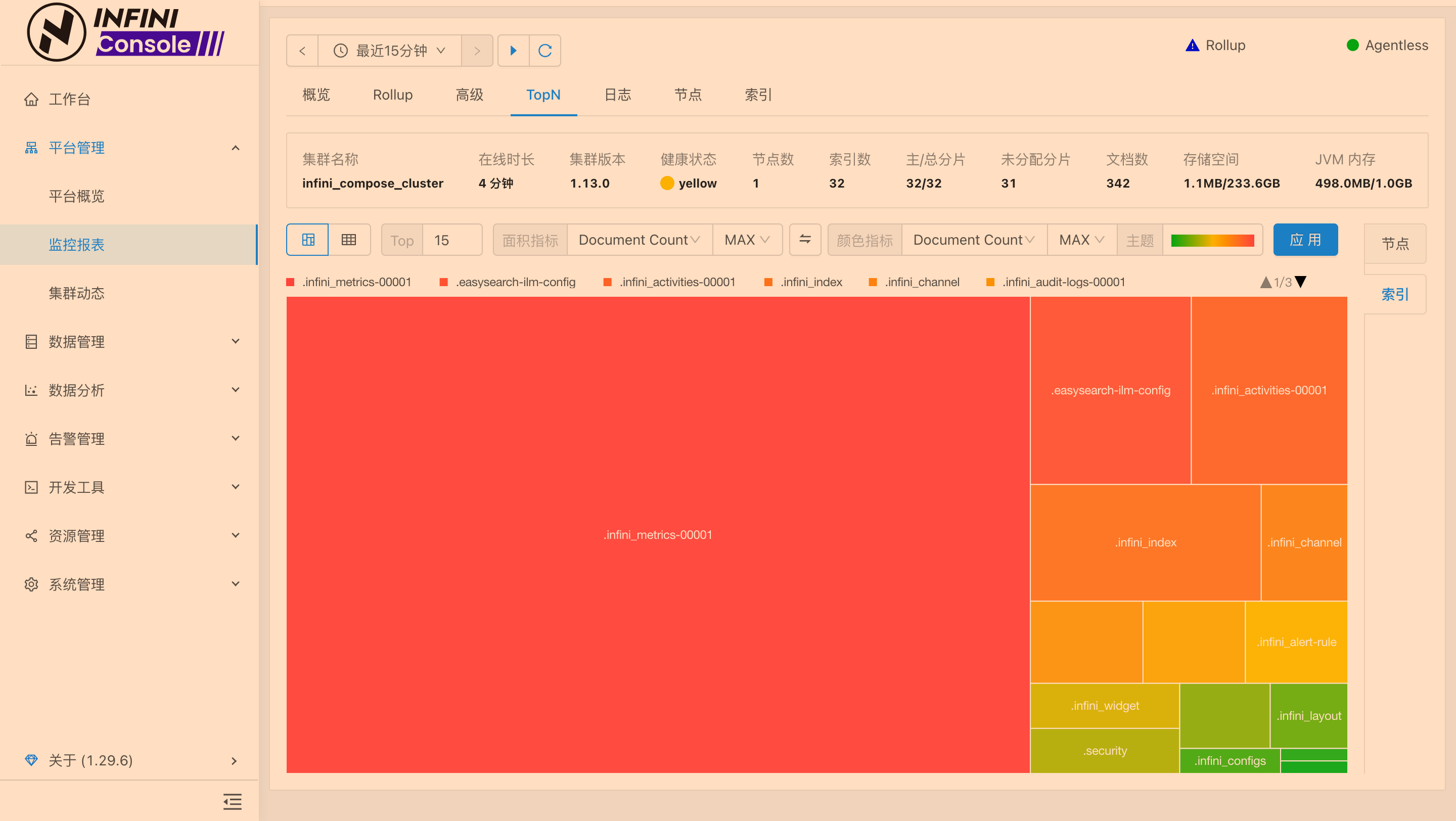
彻底清理,包括删除命名卷(如果使用了的话)和本地数据(可选)
# -v 移除命名卷
docker compose down -v
# 然后手动删除本地持久化目录
rm -rf ~/infini_compose_lab/console
rm -rf ~/infini_compose_lab/easysearch总结
通过 Docker Compose,我们用一个简洁的 docker-compose.yml 文件取代了之前冗长的 docker run 命令,极大地简化了 INFINI Console 和 Easysearch 本地环境的搭建和管理过程。同时,通过正确的卷挂载配置,我们依然确保了数据的持久化,解决了重启后配置丢失的问题。
对于开发、测试和快速原型验证,Docker Compose 无疑是一个强大而高效的工具。希望本教程能帮助你更轻松地使用 INFINI Console 进行本地实验和开发!
关于 INFINI Console
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。INFINI Console 还可以对集群内的索引及数据进行操作管理,可以配置灵活的告警规则,可以指定统一的安全策略,可以查看各个维度的日志和审计信息,真正实现企业级的搜索服务平台化建设和运营。
官网文档:https://docs.infinilabs.com/console/main/
开源地址:https://github.com/infinilabs/console
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose/
前言回顾
在上一篇文章《搭建持久化的 INFINI Console 与 Easysearch 容器环境》中,我们详细介绍了如何使用基础的 docker run 命令,手动启动和配置 INFINI Console (1.29.6) 和 INFINI Easysearch (1.13.0) 容器,并实现了关键数据的持久化,解决了重启后配置丢失的问题。
手动操作虽然能让我们深入理解 Docker 的核心机制,但在管理多个容器、网络和卷时,命令会变得冗长且容易出错。这时,Docker Compose 就派上了用场。它允许我们使用一个 YAML 文件来定义和运行多容器 Docker 应用程序。
本篇文章将演示如何将上一篇的手动步骤转换为使用 Docker Compose,让你更轻松地管理和维护这套本地开发测试环境。
Docker Compose 的优势
使用 Docker Compose 带来了诸多好处:
- 声明式配置:在一个
docker-compose.yml文件中定义所有服务、网络和卷,清晰明了。 - 一键式管理:使用简单的命令(如
docker compose up,docker compose down)即可启动、停止和重建整个应用环境。 - 简化网络和服务连接:Compose 会自动处理服务间的网络设置和依赖关系。
- 易于共享和版本控制:
docker-compose.yml文件可以轻松地与团队共享并通过版本控制系统(如 Git)进行管理。
准备工作
与上一篇类似,你需要:
- 操作系统: macOS (本文示例)
- Docker 环境: OrbStack (https://orbstack.dev/) 或 Docker Desktop for Mac。
- 确保 Docker Compose V2 (
docker compose) 或 V1 (docker-compose) 已安装并可用。
查看
docker compose版本
docker compose version
Docker Compose version v2.24.5步骤一:项目目录结构
我们将继续使用上一篇文章中创建的目录结构。如果你还没有创建,或者想重新开始,可以在你的项目根目录(例如 ~/infini_compose_lab)下创建如下结构:
# 1. 创建项目根目录
mkdir -p ~/infini_compose_lab
cd ~/infini_compose_lab
# 2. 为 Console 和 Easysearch 创建持久化子目录
# 这些目录将用于存储配置、数据和日志
mkdir -p console/config console/data console/logs
mkdir -p easysearch/config easysearch/data easysearch/logs步骤二:提取初始配置文件
这一步与上一篇完全相同。你在首次启动时使用从镜像中提取的默认配置,请执行以下操作。如果这些目录中已存在配置文件(例如从上一篇博客的操作中保留下来的),Docker Compose 在挂载时会直接使用它们。
1. INFINI Console (1.29.6) 初始配置
(容器内配置路径: /config)
# 确保在 ~/infini_compose_lab 目录下
docker pull infinilabs/console:1.29.6
docker run --rm \
-v $PWD/console/config:/temp_host_config \
infinilabs/console:1.29.6 \
sh -c "cp -a /config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"2. INFINI Easysearch (1.13.0) 初始配置
(容器内配置路径: /app/easysearch/config,初始密码: INFINILabs01)
重要提示:请务必为 Easysearch 设置安全的密码。
# 确保在 ~/infini_compose_lab 目录下
docker pull infinilabs/easysearch:1.13.0
docker run --rm \
-e EASYSEARCH_INITIAL_ADMIN_PASSWORD="INFINILabs01" \
-v $PWD/easysearch/config:/temp_host_config \
infinilabs/easysearch:1.13.0 \
sh -c "cp -a /app/easysearch/config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"步骤三:创建 docker-compose.yml 文件
这是核心步骤。在你的项目根目录 ~/infini_compose_lab 下,创建一个名为 docker-compose.yml 的文件,并填入以下内容。这个文件定义了我们的服务、它们如何运行以及它们如何交互。
cat <<EOF > docker-compose.yml
services:
easysearch:
image: infinilabs/easysearch:1.13.0
container_name: infini-easysearch
environment:
- cluster.name=infini_compose_cluster
- node.name=node-01
- cluster.initial_master_nodes=node-01
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
- EASYSEARCH_INITIAL_ADMIN_PASSWORD=INFINILabs01
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./easysearch/config:/app/easysearch/config
- ./easysearch/data:/app/easysearch/data
- ./easysearch/logs:/app/easysearch/logs
ulimits:
memlock: {soft: -1, hard: -1}
nofile: {soft: 65536, hard: 65536}
networks:
- infini_app_net
console:
image: infinilabs/console:1.29.6
container_name: infini-console
ports:
- "9000:9000"
volumes:
- ./console/config:/config
- ./console/data:/data
- ./console/logs:/log
networks:
- infini_app_net
networks:
infini_app_net:
driver: bridge
EOFdocker-compose.yml 文件关键点:
services: 定义了easysearch和console两个服务。image: 指定了每个服务使用的 Docker 镜像和版本。container_name: 为容器指定一个易于识别的名称。environment: 设置容器的环境变量。- Easysearch 单节点配置: 注意
cluster.initial_master_nodes设置为节点自身的名称。 ports: 将容器的端口映射到宿主机的端口。volumes: 实现持久化的核心。将宿主机当前目录 (./) 下的console/*和easysearch/*子目录分别映射到容器内对应的路径。networks: 将两个服务都连接到我们定义的infini_app_net网络。这使得console服务可以通过服务名easysearch(例如https://easysearch:9200) 来访问easysearch服务。
步骤四:使用 Docker Compose 启动环境
现在,所有配置都在 docker-compose.yml 文件中了。启动整个环境只需要一条命令。
在 ~/infini_compose_lab 目录下(包含 docker-compose.yml 文件),执行:
docker compose up -ddocker compose(V2) 或docker-compose(V1)。up: 创建并启动在docker-compose.yml中定义的所有服务。-d: 后台模式运行。
首次运行时,如果本地没有对应的镜像,Docker Compose 会自动拉取。
常用 Docker Compose 命令:
- 查看服务状态:
docker compose ps- 查看所有服务的实时日志:
docker compose logs -f- 查看特定服务的日志:
docker compose logs -f console
docker compose logs -f easysearch- 停止所有服务(保留数据):
docker compose stop- 停止并移除所有容器、网络和匿名卷(保留通过
volumes映射的本地数据):
docker compose down步骤五:验证和使用
- 访问 Console: 浏览器打开
http://localhost:9000。 - 进行配置: 在 Console 中连接 Easysearch (
https://easysearch:9200,因为它们在同一个 Docker 网络中,可以直接使用服务名),创建用户,查看监控等。 - 测试持久化:
docker compose down # 停止并移除容器
# 稍等片刻
docker compose up -d # 重新启动再次访问 http://localhost:9000,你会发现之前的配置都还在!
操作截图
彻底清理,包括删除命名卷(如果使用了的话)和本地数据(可选)
# -v 移除命名卷
docker compose down -v
# 然后手动删除本地持久化目录
rm -rf ~/infini_compose_lab/console
rm -rf ~/infini_compose_lab/easysearch总结
通过 Docker Compose,我们用一个简洁的 docker-compose.yml 文件取代了之前冗长的 docker run 命令,极大地简化了 INFINI Console 和 Easysearch 本地环境的搭建和管理过程。同时,通过正确的卷挂载配置,我们依然确保了数据的持久化,解决了重启后配置丢失的问题。
对于开发、测试和快速原型验证,Docker Compose 无疑是一个强大而高效的工具。希望本教程能帮助你更轻松地使用 INFINI Console 进行本地实验和开发!
关于 INFINI Console
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。INFINI Console 还可以对集群内的索引及数据进行操作管理,可以配置灵活的告警规则,可以指定统一的安全策略,可以查看各个维度的日志和审计信息,真正实现企业级的搜索服务平台化建设和运营。
官网文档:https://docs.infinilabs.com/console/main/
开源地址:https://github.com/infinilabs/console
收起阅读 »作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose/
如何搭建持久化的 INFINI Console 与 Easysearch 容器环境
背景介绍
许多用户在使用 Docker 部署 INFINI Console(本文使用 1.29.6 版本)时,可能会遇到一个常见问题:重启容器后,之前在 INFINI Console 中所连接的系统集群配置会丢失。这个问题通常源于未能正确配置 Docker 的数据持久化。原本通过 Docker 运行 INFINI Console 只是一个简单的测试示例,并未考虑多次重启使用,现官方文档也进行了更新,参考:容器部署
接下来我们本地测试一下。
理解核心问题:Docker 容器与数据持久化
默认情况下,Docker 容器的文件系统是临时的。当容器被停止并删除后,容器内部所做的任何未被持久化的更改都会丢失。INFINI Console 的配置存储在其容器内部的特定目录中。为了在容器重启或重建后保留这些信息,我们必须将这些关键目录映射到宿主机(你的电脑)上的持久化存储位置。
准备工作
- 操作系统: macOS (本文示例)
- Docker 环境: OrbStack (https://orbstack.dev/) 或 Docker Desktop for Mac。
请确保 Docker 服务已启动并正常运行。你可以通过在终端执行 docker --version 来验证。
docker --version
Docker version 25.0.5, build 5dc9bcc步骤一:创建本地持久化目录和自定义 Docker 网络
首先,在宿主机上为 Console 和 Easysearch 创建用于存储配置、数据和日志的目录。同时,创建一个自定义 Docker 网络,以便容器之间可以通过名称进行通信。
# 1. 创建项目根目录和各个服务的持久化子目录
mkdir -p ~/infini_manual_setup/console/config ~/infini_manual_setup/console/data ~/infini_manual_setup/console/logs
mkdir -p ~/infini_manual_setup/easysearch/config ~/infini_manual_setup/easysearch/data ~/infini_manual_setup/easysearch/logs
cd ~/infini_manual_setup
# 2. 创建一个自定义的 Docker 桥接网络
docker network create infini_app_netinfini_app_net是我们为这两个容器创建的自定义网络名称。
步骤二:提取初始配置文件
为了方便首次启动和后续自定义,我们需要从官方 Docker 镜像中提取默认的配置文件到我们本地创建的持久化目录中。
1. INFINI Console (1.29.6) 初始配置
根据 INFINI Console 官方 Docker 文档,其容器内配置文件位于 /config。
docker pull infinilabs/console:1.29.6
docker run --rm \
-v $PWD/console/config:/temp_host_config \
infinilabs/console:1.29.6 \
sh -c "cp -a /config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"2. INFINI Easysearch (1.13.0) 初始配置
INFINI Easysearch 镜像内部的配置文件位于 /app/easysearch/config,并且需要初始管理员密码 INFINILabs01。
重要提示:请务必为 Easysearch 设置安全的密码。
docker pull infinilabs/easysearch:1.13.0
docker run --rm \
-e EASYSEARCH_INITIAL_ADMIN_PASSWORD="INFINILabs01" \
-v $PWD/easysearch/config:/temp_host_config \
infinilabs/easysearch:1.13.0 \
sh -c "cp -a /app/easysearch/config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"现在,你的本地 console/config 和 easysearch/config 目录应该包含了初始配置文件。
检查目录如下
tree -L 3 .
.
├── console
│ ├── config
│ │ ├── install_agent.tpl
│ │ ├── permission.json
│ │ ├── setup
│ │ └── system_config.tpl
│ ├── data
│ └── logs
└── easysearch
├── config
│ ├── admin.crt
│ ├── admin.key
│ ├── analysis-ik
│ ├── ca.crt
│ ├── ca.key
│ ├── easysearch.yml
│ ├── easysearch.yml.example
│ ├── instance.crt
│ ├── instance.key
│ ├── jvm.options
│ ├── jvm.options.d
│ ├── log4j2.properties
│ └── security
├── data
└── logs步骤三:手动运行 INFINI Easysearch 容器
使用 docker run 命令启动 Easysearch,并配置端口映射、环境变量和最重要的——卷挂载。
docker run -d \
--name easysearch01 \
--network infini_app_net \
-p 9200:9200 \
-p 9300:9300 \
-e cluster.name="infini_local_cluster" \
-e node.name="easysearch-node01" \
-e cluster.initial_master_nodes="easysearch-node01" \
-e "ES_JAVA_OPTS=-Xms1g -Xmx1g" \
-e EASYSEARCH_INITIAL_ADMIN_PASSWORD="INFINILabs01" \
-v $PWD/easysearch/config:/app/easysearch/config \
-v $PWD/easysearch/data:/app/easysearch/data \
-v $PWD/easysearch/logs:/app/easysearch/logs \
--ulimit memlock=-1:-1 \
--ulimit nofile=65536:65536 \
infinilabs/easysearch:1.13.0关键参数解释:
--name easysearch01: 为容器指定一个名称。--network infini_app_net: 连接到自定义网络。-p HOST_PORT:CONTAINER_PORT: 端口映射。-e VARIABLE=VALUE: 设置环境变量。-v $PWD/host/path:/container/path: 实现持久化的核心。将宿主机当前工作目录 ($PWD) 下的子目录映射到容器内的指定路径。
步骤四:手动运行 INFINI Console 容器
现在启动 Console 容器,同样配置网络、端口、环境变量和卷挂载。
docker run -d \
--name console01 \
--network infini_app_net \
-p 9000:9000 \
-v $PWD/console/config:/config \
-v $PWD/console/data:/data \
-v $PWD/console/logs:/log \
infinilabs/console:1.29.6查看日志
docker logs -f easysearch01
docker logs -f console01步骤五:验证服务和持久化
- 检查容器状态:
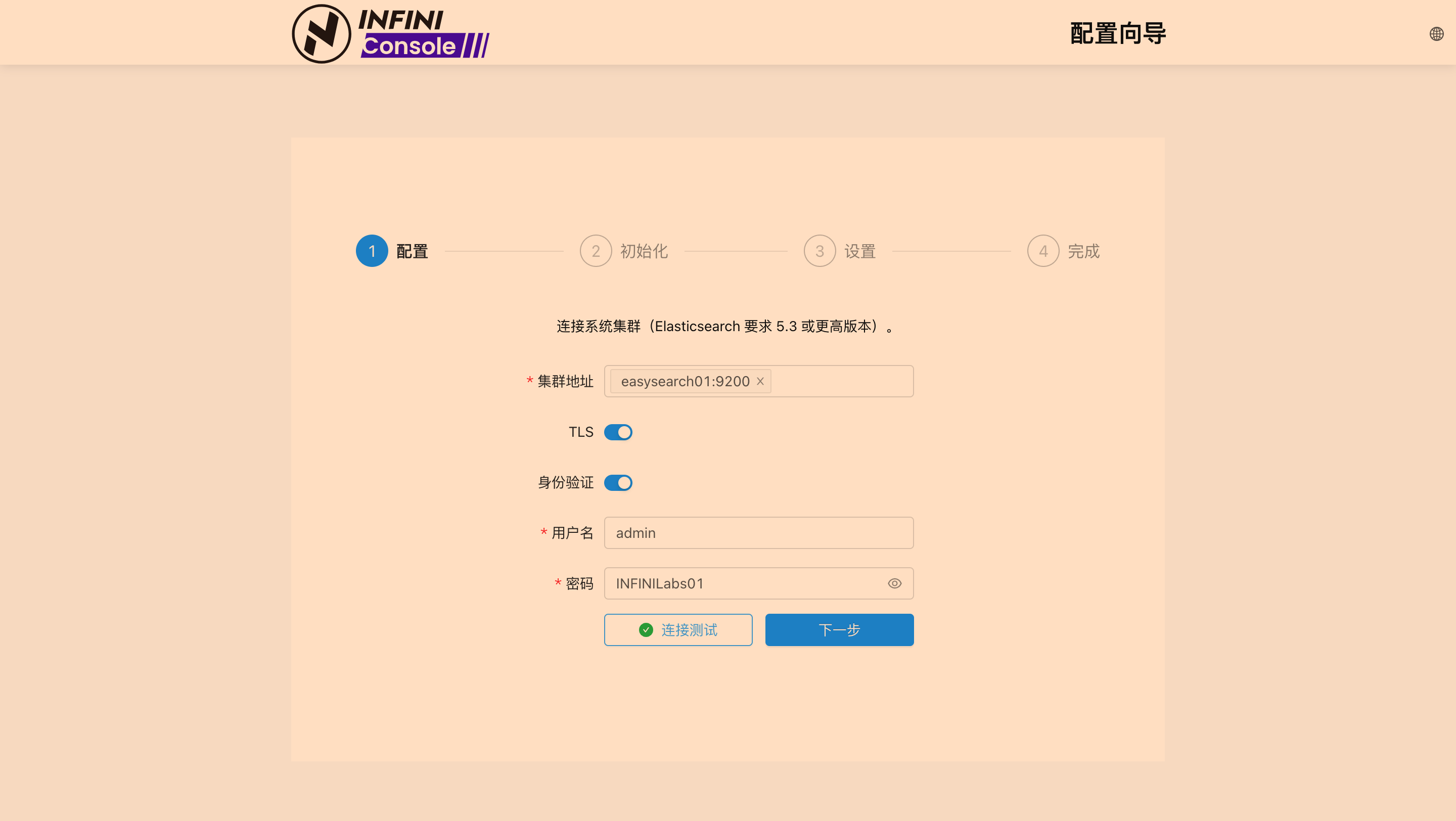
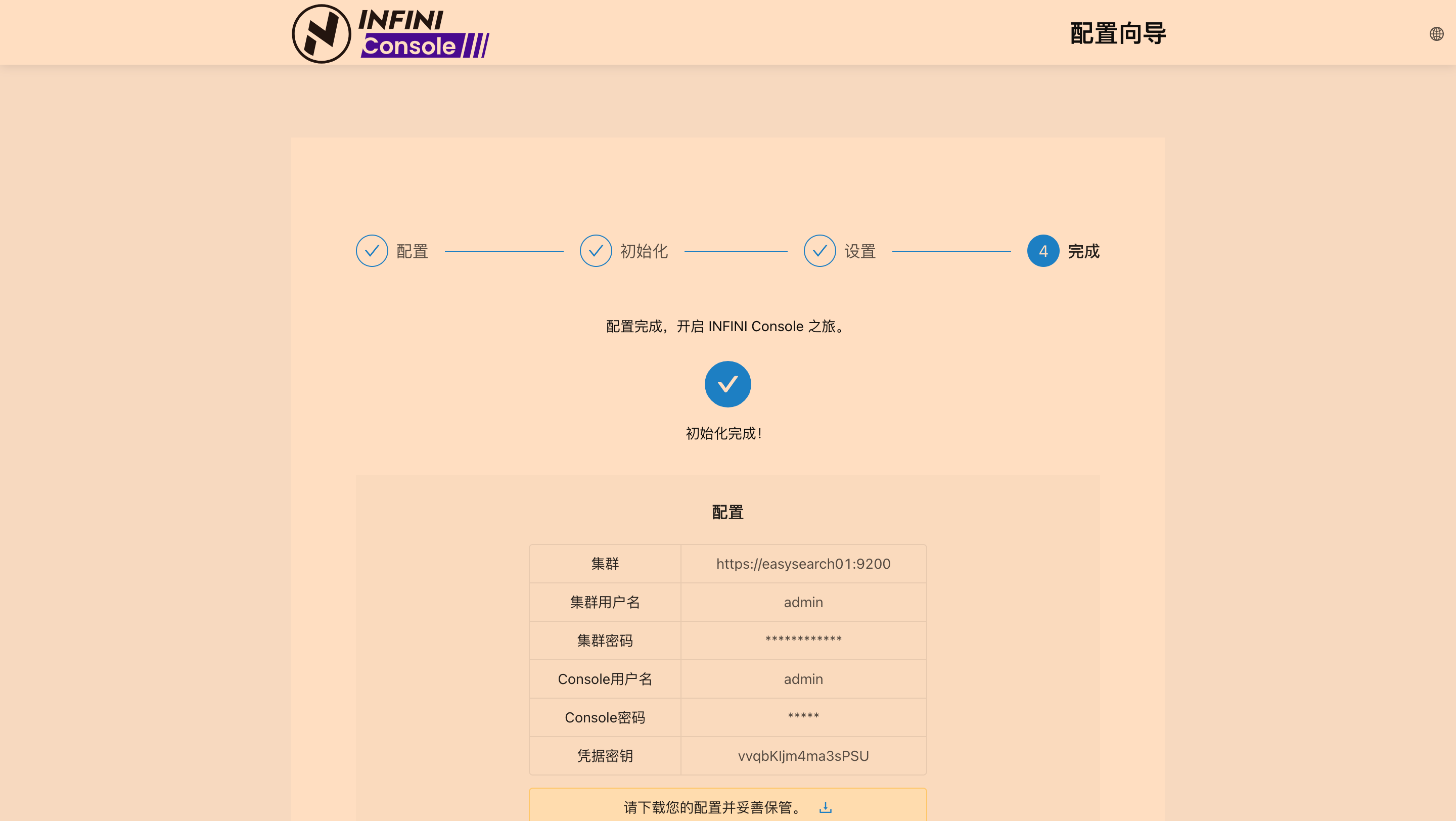
docker ps(应能看到easysearch01和console01)。 - 访问 Console: 浏览器打开
http://localhost:9000。 - 在 Console 中进行初始化配置
- 测试持久化 (重启 Console 容器):
docker stop console01
docker rm console01
# 重新运行步骤四中启动 Console 的 docker run 命令 (确保所有参数一致)操作截图

再次访问 Console: 打开 http://localhost:9000。如果一切正常,证明持久化成功。
步骤六:停止和清理(可选)
- 停止容器:
docker stop console01 easysearch01 - 移除容器:
docker rm console01 easysearch01 - 移除网络:
docker network rm infini_app_net - 移除本地持久化数据 (如果不再需要):
rm -rf ~/infini_manual_setup/console
rm -rf ~/infini_manual_setup/easysearch总结
通过 docker run 命令并仔细配置卷挂载,我们成功地为 INFINI Console 和 Easysearch 构建了一个具有持久化能力的本地容器环境,有效解决了重启后配置丢失的问题。虽然手动操作参数较多,但它能让你更清晰地理解 Docker 的核心机制。
在后续的文章中,我们将探讨如何使用 Docker Compose 来简化这一过程。
关于 INFINI Console
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。INFINI Console 还可以对集群内的索引及数据进行操作管理,可以配置灵活的告警规则,可以指定统一的安全策略,可以查看各个维度的日志和审计信息,真正实现企业级的搜索服务平台化建设和运营。
官网文档:https://docs.infinilabs.com/console/main/
开源地址:https://github.com/infinilabs/console
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker/
背景介绍
许多用户在使用 Docker 部署 INFINI Console(本文使用 1.29.6 版本)时,可能会遇到一个常见问题:重启容器后,之前在 INFINI Console 中所连接的系统集群配置会丢失。这个问题通常源于未能正确配置 Docker 的数据持久化。原本通过 Docker 运行 INFINI Console 只是一个简单的测试示例,并未考虑多次重启使用,现官方文档也进行了更新,参考:容器部署
接下来我们本地测试一下。
理解核心问题:Docker 容器与数据持久化
默认情况下,Docker 容器的文件系统是临时的。当容器被停止并删除后,容器内部所做的任何未被持久化的更改都会丢失。INFINI Console 的配置存储在其容器内部的特定目录中。为了在容器重启或重建后保留这些信息,我们必须将这些关键目录映射到宿主机(你的电脑)上的持久化存储位置。
准备工作
- 操作系统: macOS (本文示例)
- Docker 环境: OrbStack (https://orbstack.dev/) 或 Docker Desktop for Mac。
请确保 Docker 服务已启动并正常运行。你可以通过在终端执行 docker --version 来验证。
docker --version
Docker version 25.0.5, build 5dc9bcc步骤一:创建本地持久化目录和自定义 Docker 网络
首先,在宿主机上为 Console 和 Easysearch 创建用于存储配置、数据和日志的目录。同时,创建一个自定义 Docker 网络,以便容器之间可以通过名称进行通信。
# 1. 创建项目根目录和各个服务的持久化子目录
mkdir -p ~/infini_manual_setup/console/config ~/infini_manual_setup/console/data ~/infini_manual_setup/console/logs
mkdir -p ~/infini_manual_setup/easysearch/config ~/infini_manual_setup/easysearch/data ~/infini_manual_setup/easysearch/logs
cd ~/infini_manual_setup
# 2. 创建一个自定义的 Docker 桥接网络
docker network create infini_app_netinfini_app_net是我们为这两个容器创建的自定义网络名称。
步骤二:提取初始配置文件
为了方便首次启动和后续自定义,我们需要从官方 Docker 镜像中提取默认的配置文件到我们本地创建的持久化目录中。
1. INFINI Console (1.29.6) 初始配置
根据 INFINI Console 官方 Docker 文档,其容器内配置文件位于 /config。
docker pull infinilabs/console:1.29.6
docker run --rm \
-v $PWD/console/config:/temp_host_config \
infinilabs/console:1.29.6 \
sh -c "cp -a /config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"2. INFINI Easysearch (1.13.0) 初始配置
INFINI Easysearch 镜像内部的配置文件位于 /app/easysearch/config,并且需要初始管理员密码 INFINILabs01。
重要提示:请务必为 Easysearch 设置安全的密码。
docker pull infinilabs/easysearch:1.13.0
docker run --rm \
-e EASYSEARCH_INITIAL_ADMIN_PASSWORD="INFINILabs01" \
-v $PWD/easysearch/config:/temp_host_config \
infinilabs/easysearch:1.13.0 \
sh -c "cp -a /app/easysearch/config/. /temp_host_config/ && chmod -R ugo+rw /temp_host_config/"现在,你的本地 console/config 和 easysearch/config 目录应该包含了初始配置文件。
检查目录如下
tree -L 3 .
.
├── console
│ ├── config
│ │ ├── install_agent.tpl
│ │ ├── permission.json
│ │ ├── setup
│ │ └── system_config.tpl
│ ├── data
│ └── logs
└── easysearch
├── config
│ ├── admin.crt
│ ├── admin.key
│ ├── analysis-ik
│ ├── ca.crt
│ ├── ca.key
│ ├── easysearch.yml
│ ├── easysearch.yml.example
│ ├── instance.crt
│ ├── instance.key
│ ├── jvm.options
│ ├── jvm.options.d
│ ├── log4j2.properties
│ └── security
├── data
└── logs步骤三:手动运行 INFINI Easysearch 容器
使用 docker run 命令启动 Easysearch,并配置端口映射、环境变量和最重要的——卷挂载。
docker run -d \
--name easysearch01 \
--network infini_app_net \
-p 9200:9200 \
-p 9300:9300 \
-e cluster.name="infini_local_cluster" \
-e node.name="easysearch-node01" \
-e cluster.initial_master_nodes="easysearch-node01" \
-e "ES_JAVA_OPTS=-Xms1g -Xmx1g" \
-e EASYSEARCH_INITIAL_ADMIN_PASSWORD="INFINILabs01" \
-v $PWD/easysearch/config:/app/easysearch/config \
-v $PWD/easysearch/data:/app/easysearch/data \
-v $PWD/easysearch/logs:/app/easysearch/logs \
--ulimit memlock=-1:-1 \
--ulimit nofile=65536:65536 \
infinilabs/easysearch:1.13.0关键参数解释:
--name easysearch01: 为容器指定一个名称。--network infini_app_net: 连接到自定义网络。-p HOST_PORT:CONTAINER_PORT: 端口映射。-e VARIABLE=VALUE: 设置环境变量。-v $PWD/host/path:/container/path: 实现持久化的核心。将宿主机当前工作目录 ($PWD) 下的子目录映射到容器内的指定路径。
步骤四:手动运行 INFINI Console 容器
现在启动 Console 容器,同样配置网络、端口、环境变量和卷挂载。
docker run -d \
--name console01 \
--network infini_app_net \
-p 9000:9000 \
-v $PWD/console/config:/config \
-v $PWD/console/data:/data \
-v $PWD/console/logs:/log \
infinilabs/console:1.29.6查看日志
docker logs -f easysearch01
docker logs -f console01步骤五:验证服务和持久化
- 检查容器状态:
docker ps(应能看到easysearch01和console01)。 - 访问 Console: 浏览器打开
http://localhost:9000。 - 在 Console 中进行初始化配置
- 测试持久化 (重启 Console 容器):
docker stop console01
docker rm console01
# 重新运行步骤四中启动 Console 的 docker run 命令 (确保所有参数一致)操作截图
再次访问 Console: 打开 http://localhost:9000。如果一切正常,证明持久化成功。
步骤六:停止和清理(可选)
- 停止容器:
docker stop console01 easysearch01 - 移除容器:
docker rm console01 easysearch01 - 移除网络:
docker network rm infini_app_net - 移除本地持久化数据 (如果不再需要):
rm -rf ~/infini_manual_setup/console
rm -rf ~/infini_manual_setup/easysearch总结
通过 docker run 命令并仔细配置卷挂载,我们成功地为 INFINI Console 和 Easysearch 构建了一个具有持久化能力的本地容器环境,有效解决了重启后配置丢失的问题。虽然手动操作参数较多,但它能让你更清晰地理解 Docker 的核心机制。
在后续的文章中,我们将探讨如何使用 Docker Compose 来简化这一过程。
关于 INFINI Console
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。INFINI Console 还可以对集群内的索引及数据进行操作管理,可以配置灵活的告警规则,可以指定统一的安全策略,可以查看各个维度的日志和审计信息,真正实现企业级的搜索服务平台化建设和运营。
官网文档:https://docs.infinilabs.com/console/main/
开源地址:https://github.com/infinilabs/console
收起阅读 »作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker/
【搜索客社区日报】第2066期 (2025-07-01)
https://medium.com/%40guptaarm ... d5aef
2. 用Kyverno Policies和他的朋友们做k8s的日志处理怎么搞(需要梯子)
https://medium.com/the-code-jo ... 80118
3. 零停机跨集群迁移,肘着(需要梯子)
https://medium.com/%40krishnac ... c1b5a
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40guptaarm ... d5aef
2. 用Kyverno Policies和他的朋友们做k8s的日志处理怎么搞(需要梯子)
https://medium.com/the-code-jo ... 80118
3. 零停机跨集群迁移,肘着(需要梯子)
https://medium.com/%40krishnac ... c1b5a
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2065期 (2025-06-30)
https://elasticstack.blog.csdn ... 92617
2、Elasticsearch:什么是搜索相关性?
https://elasticstack.blog.csdn ... 45095
3、使用 Elasticsearch 构建一个用于真实健康数据的 MCP 服务器
https://elasticstack.blog.csdn ... 39749
4、如何将 Coco AI 与自定义数据源集成 ?
https://mp.weixin.qq.com/s/ZiPsEaxGrbDrHeC1ZWK3zw
5、日志文件是什么?
https://elasticstack.blog.csdn ... 05443
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 92617
2、Elasticsearch:什么是搜索相关性?
https://elasticstack.blog.csdn ... 45095
3、使用 Elasticsearch 构建一个用于真实健康数据的 MCP 服务器
https://elasticstack.blog.csdn ... 39749
4、如何将 Coco AI 与自定义数据源集成 ?
https://mp.weixin.qq.com/s/ZiPsEaxGrbDrHeC1ZWK3zw
5、日志文件是什么?
https://elasticstack.blog.csdn ... 05443
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »


