
记某客户的一次 Elasticsearch 无缝数据迁移
背景
客户需要将 Elasticsearch 集群无缝迁移到移动云,迁移过程要保证业务的最小停机时间。
实现方式
通过采用成熟的 INFINI 网关来进行数据的双写,在集群的切换恢复过程中来记录数据变更,待全量数据恢复之后再追平后面增量数据,追平增量之后,进行校验确保数据一致再进行流量的切换。
总体流程
总体迁移流程如下:
- 客户业务代码,切流量,双写。(新增的变更都会记录在网关本地,但是暂停消费到移动云)
- 暂停网关移动云这边的增量数据消费。
- 迁移 11 月的数据,快照,快照上传到 S3;
- 下载 S3 的文件到移动云。
- 恢复快照到移动云的 11 月份的索引。
- 开启网关移动云这边的增量消费。
- 等待增量追平(接近追平)。
- 按照时间条件(如:时间 A,当前时间往前 30 分钟),验证文档数据量,Hash 校验等等。
- 停业务的写入,网关,腾讯云的写入(10 分钟)。
- 等待剩余的增量追完。
- 对时间 A 之后的,增量进行校验。
- 切换所有流量到移动云,业务端直接访问移动云 ES。
总体的迁移时间:
- 11 月备份时间(30 分钟)19 号开始
- 备份下载到移动云的时间(2-3 天)
- 备份恢复到移动云集群的时间(30 分钟)
- 11 月份增量备份(20 分钟)(双写开始)(21 号)
- 11 月份增量下载到移动云(6 小时)
- 11 月份增量恢复时间(20 分钟)
- 追增量数据(8 个小时产生的数据,需要 1 个小时)
- 校验比对(存量 1 个小时)
- 流量暂停,增量的校验(10 分钟)
- 切换(1 分钟)
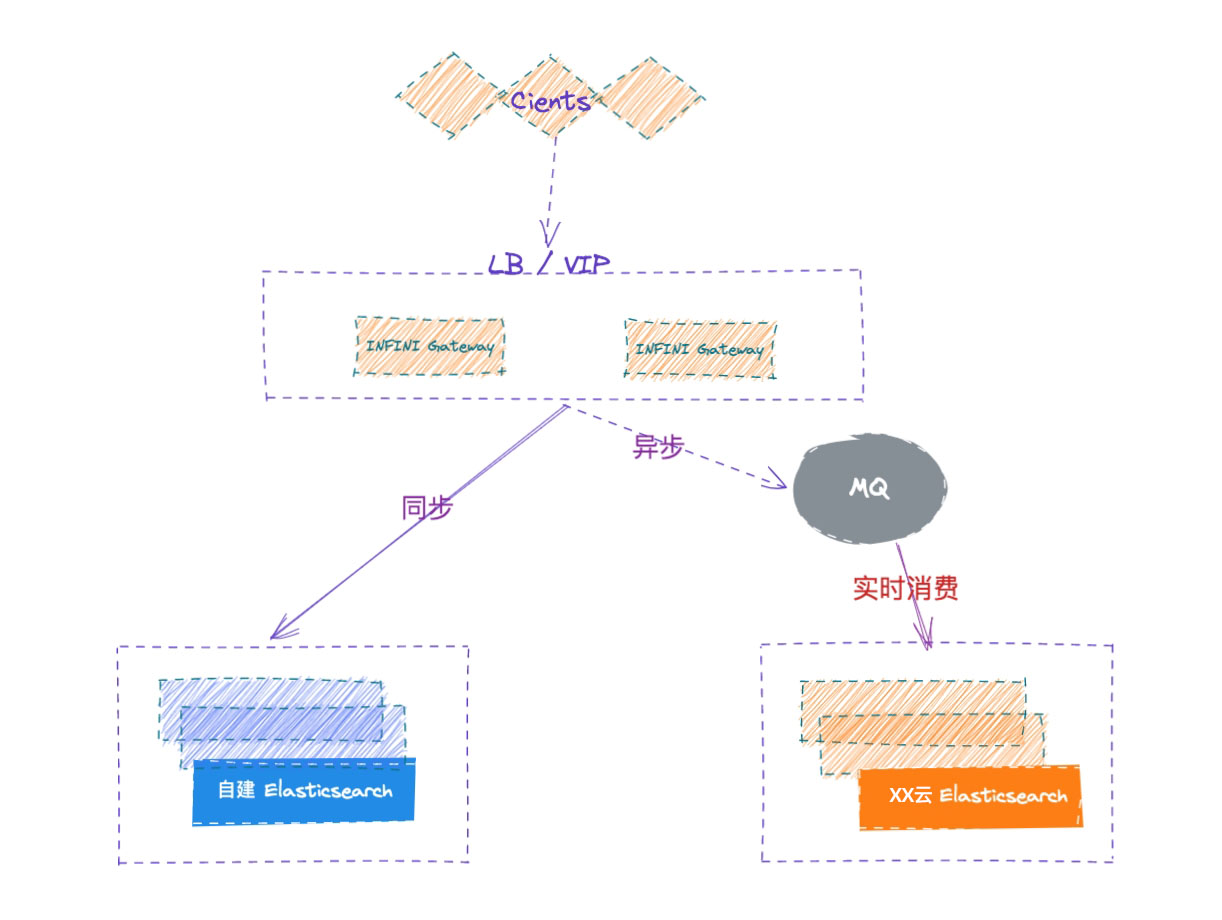
总体流程如下示意图:

ES 集群信息
- ES 版本 7.10.1
- 2个热节点 3个温节点 总数 1.9 TB
- 索引 1041, 分片2085
- 无自定义插件
- 有 update_bu_query 使用
- 有 delete_by_query 使用
- 吞吐量没有测试过,当前日增文档数 1 千多万,目标日增加上亿
迁移操作手册(参考)
环境
- 自建 ES 5.4.2
- 自建 ES 5.6.8
- 自建 ES 7.5.0
- 极限网关服务器 1
- 极限网关服务器 2
- 云端负载均衡 1 (监听 9200 端口,指向极限网关服务器 1/2 的 8000 端口)
- 云端负载均衡 2 (监听 9200 端口,指向极限网关服务器 1/2 的 8001 端口)
场景描述
若干个自建 Elasticsearch 集群需要平滑迁移到移动云,业务不停写、不做代码改动。
数据架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在云端 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
 业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
数据描述
以数据从自建集群 5.4.2 迁移到云上的 5.6.16 为例进行说明,执行步骤依次说明。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过 INFINI Gateway 来进行双写。
-
系统调优
参考此文档。
- 下载程序
[root@iZbp1gxkifg8uetb33pvcoZ ~]# mkdir /opt/gateway [root@iZbp1gxkifg8uetb33pvcoZ ~]# cd /opt/gateway/ [root@iZbp1gxkifg8uetb33pvcoZ gateway]# wget http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz --2022-05-19 10:16:25-- http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:7430568 (7.1M) [application/octet-stream] 正在保存至: “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 7,430,568 22.8MB/s 用时 0.3s
2022-05-19 10:16:25 (22.8 MB/s) - 已保存 “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz” [7430568/7430568])
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# tar vxzf gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz gateway-linux-amd64 gateway.yml sample-configs/ sample-configs/elasticsearch-with-ldap.yml sample-configs/indices-replace.yml sample-configs/record_and_play.yml sample-configs/cross-cluster-search.yml sample-configs/kibana-proxy.yml sample-configs/elasticsearch-proxy.yml sample-configs/v8-bulk-indexing-compatibility.yml sample-configs/use_old_style_search_response.yml sample-configs/context-update.yml sample-configs/elasticsearch-route-by-index.yml sample-configs/hello_world.yml sample-configs/entry-with-tls.yml sample-configs/javascript.yml sample-configs/log4j-request-filter.yml sample-configs/request-filter.yml sample-configs/condition.yml sample-configs/cross-cluster-replication.yml sample-configs/secured-elasticsearch-proxy.yml sample-configs/fast-bulk-indexing.yml sample-configs/es_migration.yml sample-configs/index-docs-diff.yml sample-configs/rate-limiter.yml sample-configs/async-bulk-indexing.yml sample-configs/elasticssearch-request-logging.yml sample-configs/router_rules.yml sample-configs/auth.yml sample-configs/index-backup.yml
3. 修改配置
将网关提供的示例配置拷贝,并根据实际集群的信息进行相应的修改,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# cp sample-configs/cross-cluster-replication.yml 5.4.2TO5.6.16.yml
首先修改集群的身份信息,如下:

然后修改集群的注册信息,如下:

根据需要修改网关监听的端口,以及是否开启 TLS (如果应用客户端通过 http 协议访问 ES,请将entry.tls.enabled 值改为 false),如下:

不同的集群可以使用不同的配置,分别监听不同的端口,用于业务的分开访问。
4. 启动网关
启动网关并指定刚刚创建的配置,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml
/ \ /\ / \/\/ / /\ \ \/\ /_/\ / /\///\ / /\/\ \ \/ \/ //\_ / / /\/ \/ / // \ /\ / \/ \ ___/\/ \/\/ \/ \/ \/_/ _/_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway. [GATEWAY] 1.6.0_SNAPSHOT, 2022-05-18 11:09:54, 2023-12-31 10:10:10, 73408e82a0f96352075f4c7d2974fd274eeafe11 [05-19 13:35:43] [INF] [app.go:174] initializing gateway. [05-19 13:35:43] [INF] [app.go:175] using config: /opt/gateway/5.4.2TO5.6.16.yml. [05-19 13:35:43] [INF] [instance.go:72] workspace: /opt/gateway/data1/gateway/nodes/ca2tc22j7ad0gneois80 [05-19 13:35:43] [INF] [app.go:283] gateway is up and running now. [05-19 13:35:50] [INF] [actions.go:358] elasticsearch [primary] is available [05-19 13:35:50] [INF] [api.go:262] api listen at: http://0.0.0.0:2900 [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [entry.go:322] entry [my_es_entry/] listen at: https://0.0.0.0:8000 [05-19 13:35:50] [INF] [module.go:116] all modules are started
5. 后台运行[root@iZbp1gxkifg8uetb33pvcoZ gateway]# nohup ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml &
6. 应用授权curl -XPOST http://localhost:2900/_license/apply -d' { "license": "XXXXXXXXXXXXXXXXXXXXXXXXX" }'
#### 部署 INFINI Console
为了方便在多个集群之间快速切换,使用 INFINI [Console](https://infinilabs.cn/products/console/) 来进行管理。
1. 下载安装[root@iZbp1gxkifg8uetb33pvcpZ console]# wget http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz --2022-05-19 10:57:24-- http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:13576234 (13M) [application/octet-stream] 正在保存至: “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 13,576,234 33.2MB/s 用时 0.4s
2022-05-19 10:57:25 (33.2 MB/s) - 已保存 “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz” [13576234/13576234])
[root@iZbp1gxkifg8uetb33pvcpZ console]# tar vxzf console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz console-linux-amd64 console.yml
2. 修改配置[root@iZbp1gxkifg8uetb33pvcpZ console]# cat console.yml
for the system cluster, please use Elasticsearch v7.3+
elasticsearch:
- name: default
enabled: true
monitored: false
endpoint: http://es-cn-7mz2p9fty0007frx0.elasticsearch.aliyuncs.com:9200
basic_auth:
username: elastic
password: XXXXXX
discovery:
enabled: false
...
-
启动服务
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service install Success [root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service start Success - 访问后台
访问该主机的 9000 端口,即可打开 Console 后台,http://x.x.x.x:9000/
打开菜单 [System][Cluster] ,注册当前需要管理的 Elasticsearch 集群和网关地址,用来快速管理,如下:

测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
 查看 5.4.2 集群的数据情况,如下:
查看 5.4.2 集群的数据情况,如下:
 查看集群 5.6.16 的数据情况,如下:
查看集群 5.6.16 的数据情况,如下:
 说明网关配置都正常,验证结束。
说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-to-backup和 consume-queue_primary-failure-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:

 修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:
修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:

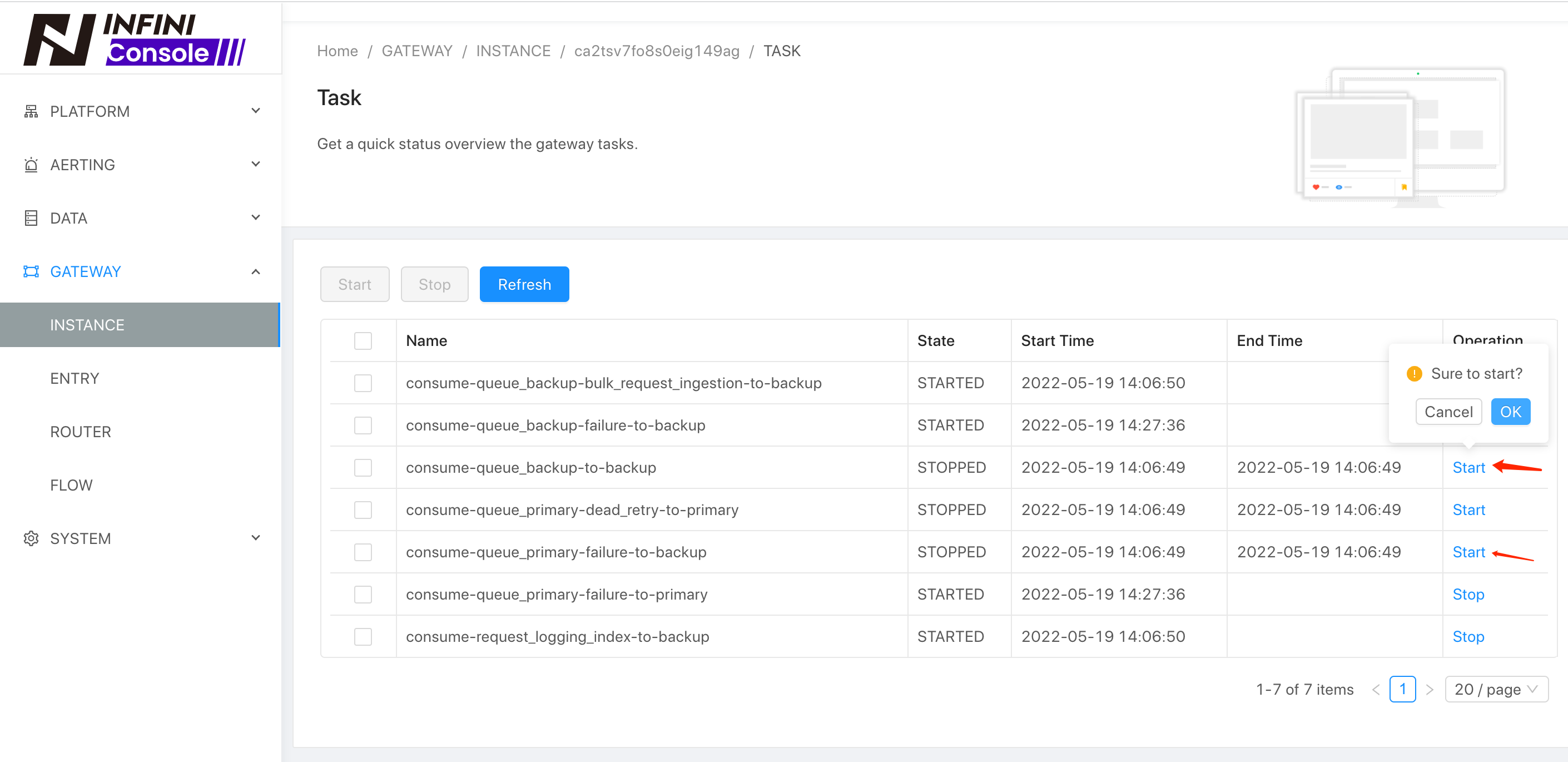
 待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:
待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:

切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。
 切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到云端 Elasticsearch 集群。
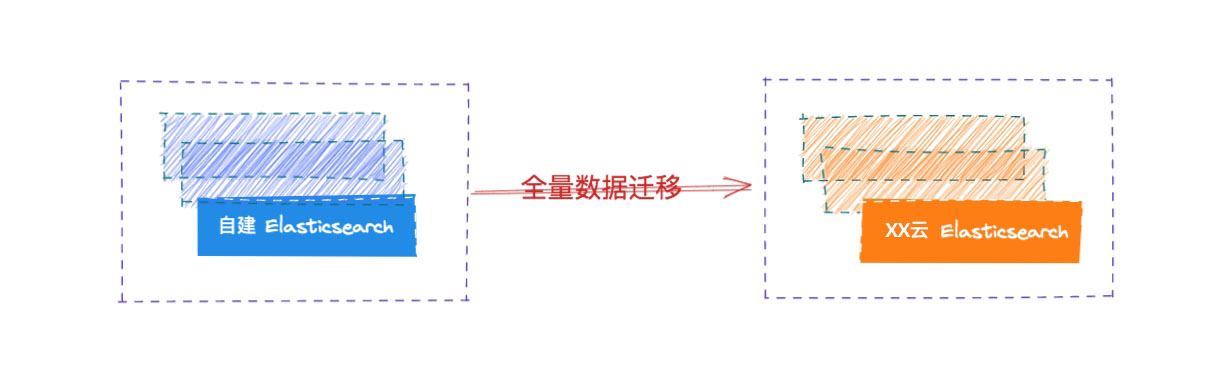 全量迁移已有的数据的方式有很多种:
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用工具来导出导入,如: ESM
如果索引数量很多的话,可以按照索引依次进行导入,同时需要注意将 Mapping 和 Setting 提前导入。
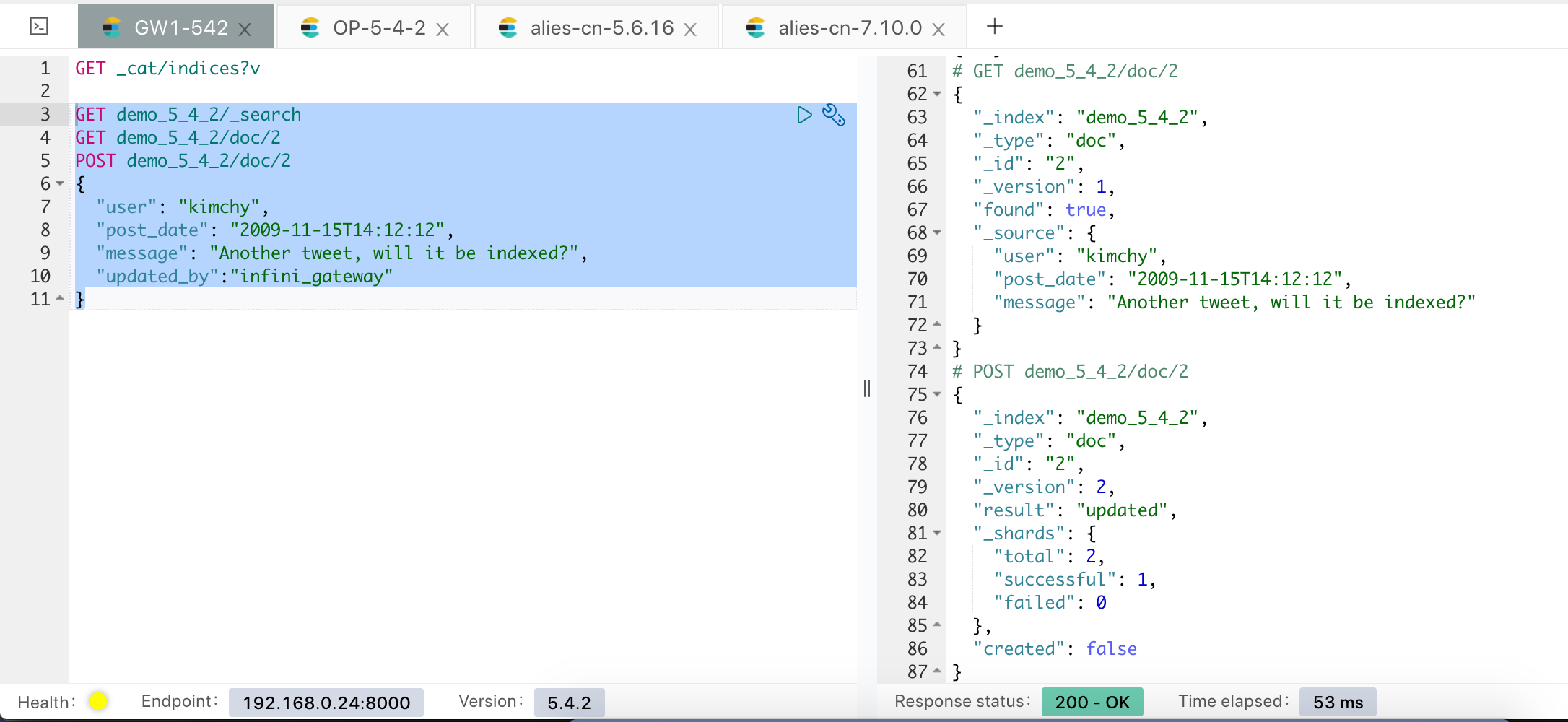
以现在 5.4 集群的索引来为例,目前的待迁移索引为 demo_5_4_2,只有4 个文档:
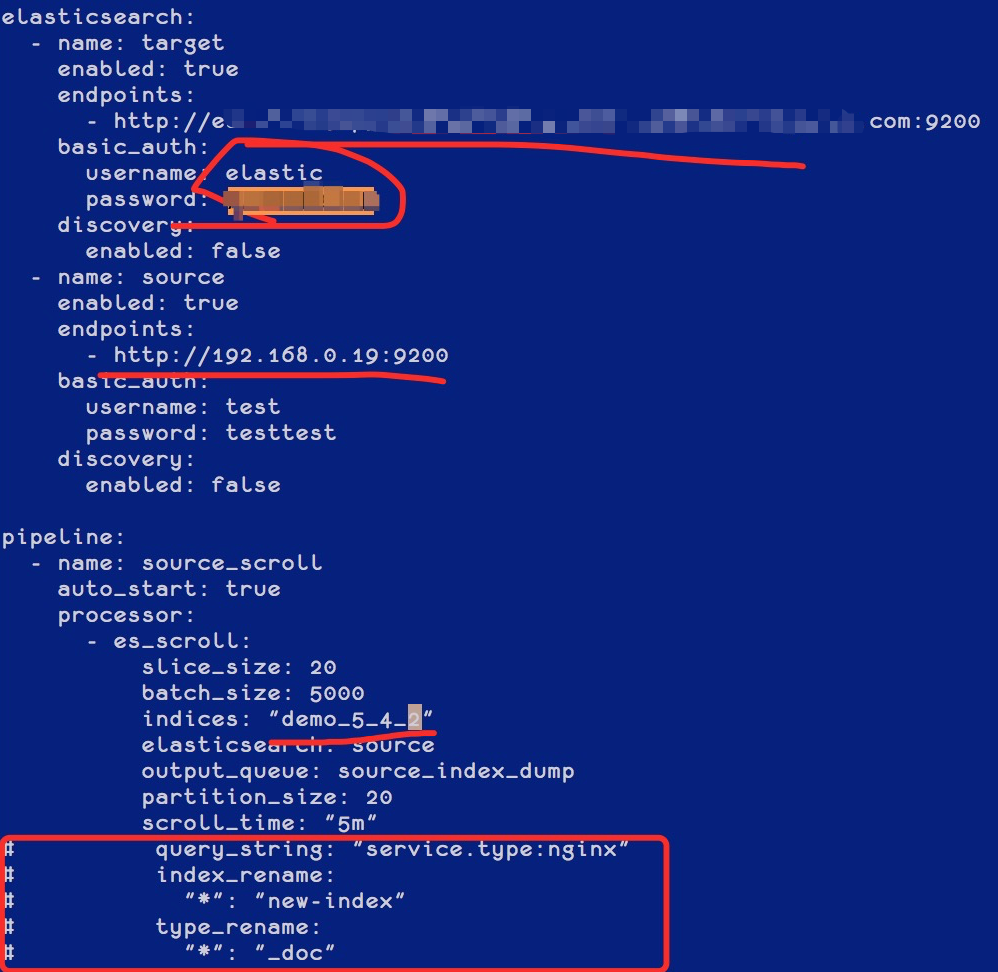
 我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/es_migration.yml 5.4TO5.6.yml修改其中代表集群和索引的相关配置,可以根据需要配置是否需要重命名索引和统一 Type( 用于跨版本统一 Type),如下图红框位置:
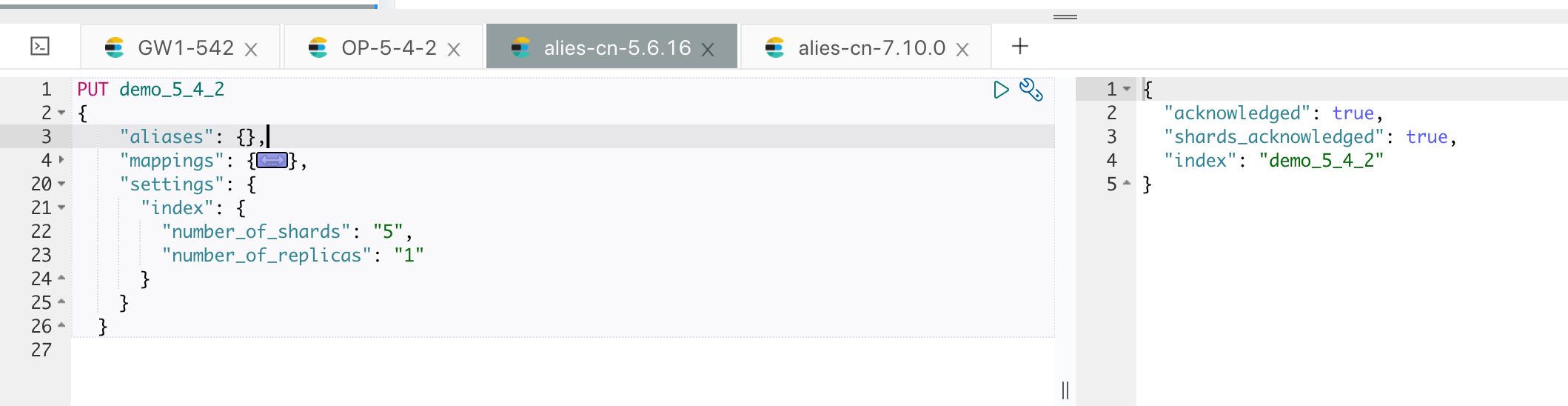
 创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
 然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
 执行完成后,可以确认下数据的情况,如下图:
执行完成后,可以确认下数据的情况,如下图:
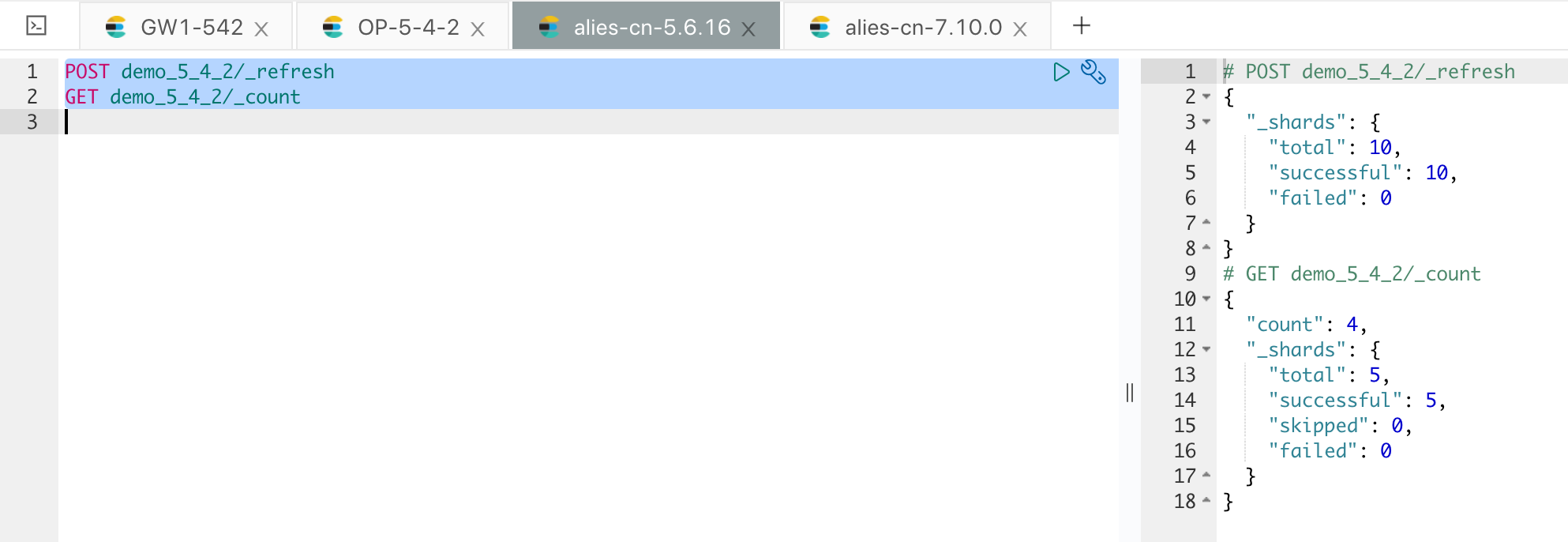 全量数据至此导入完成。
全量数据至此导入完成。
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将挤压的请求应用到云端的 Elasticsearch 集群。
 示例操作如下:
示例操作如下:
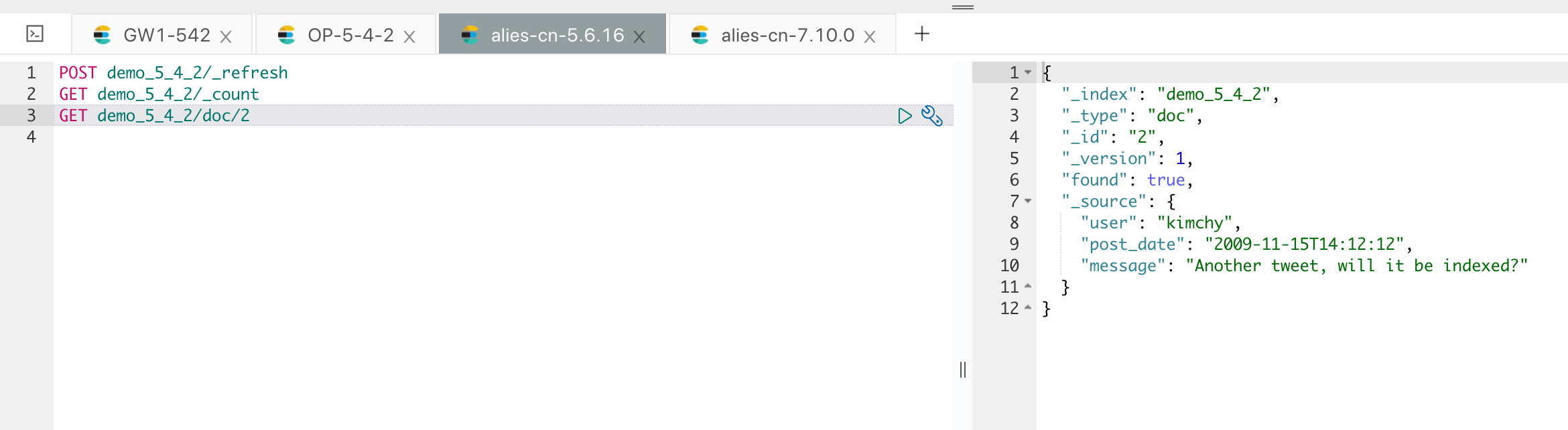
 如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
 这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
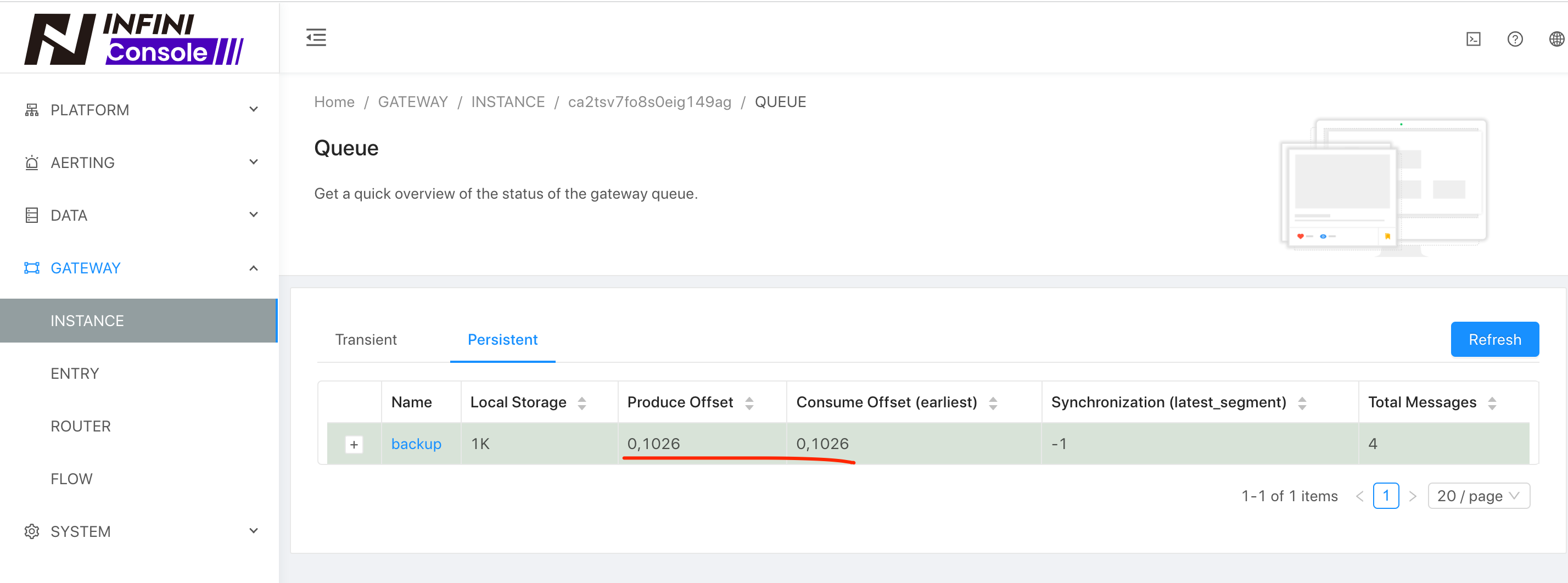
 通过观察队列是否消费完成来判断增量数据是否做完,如下:
通过观察队列是否消费完成来判断增量数据是否做完,如下:
 现在我们再看一下 5.6 集群的数据情况,如下:
现在我们再看一下 5.6 集群的数据情况,如下:
 数据的增量更新就过来了。
数据的增量更新就过来了。
执行数据比对
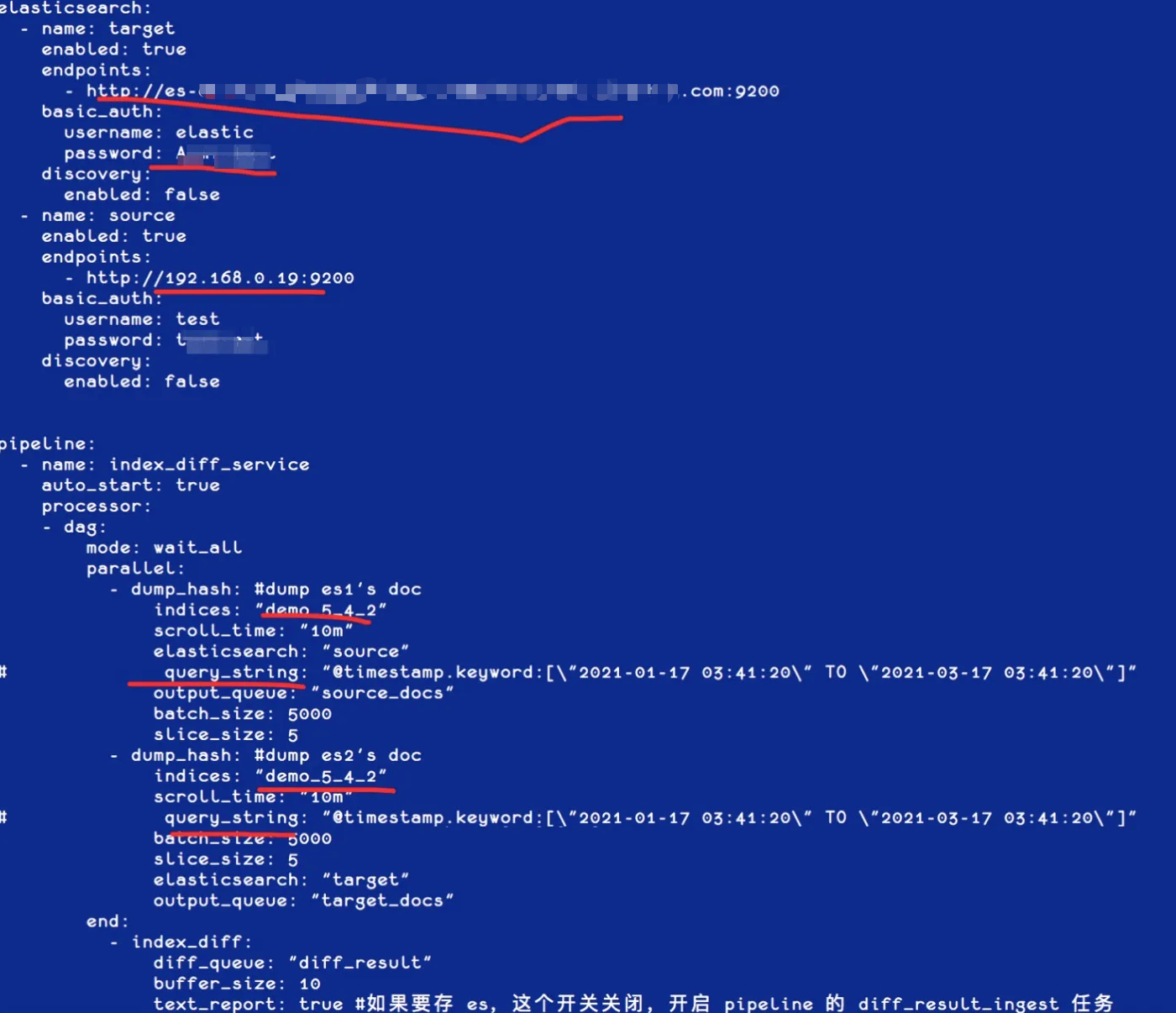
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过网关自带的数据比对工具来进行,将样例自带的文件拷贝一份,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/index-docs-diff.yml 5.4DIFF5.6.yml修改需要比对的集群和索引信息,可以加上过滤条件,如时间范围窗口来进行增量 Diff,如下图:
执行网关程序,并指定该配置文件,如下图:
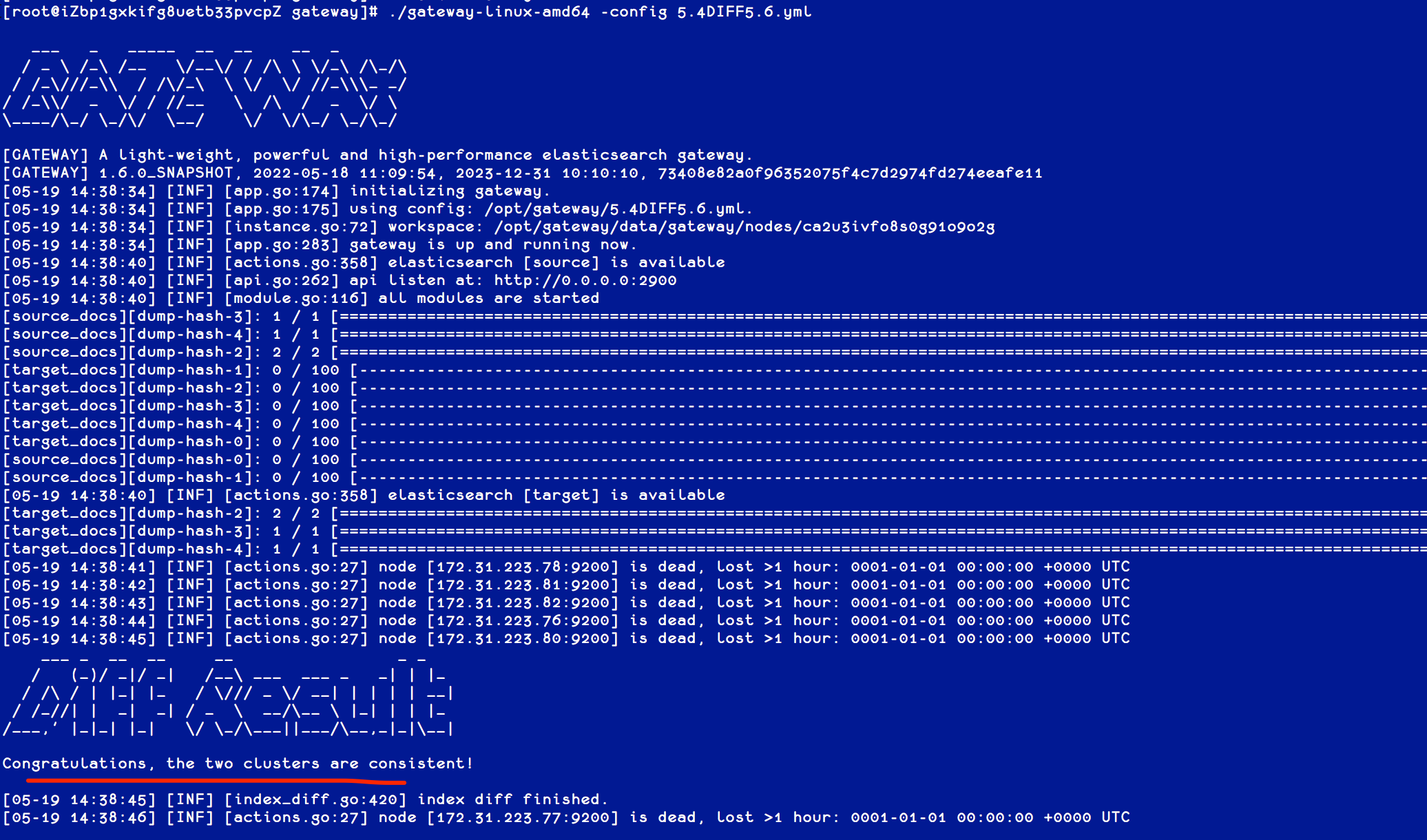 如图,两个集群完全一致。
如图,两个集群完全一致。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,同步写 5.6 集群。
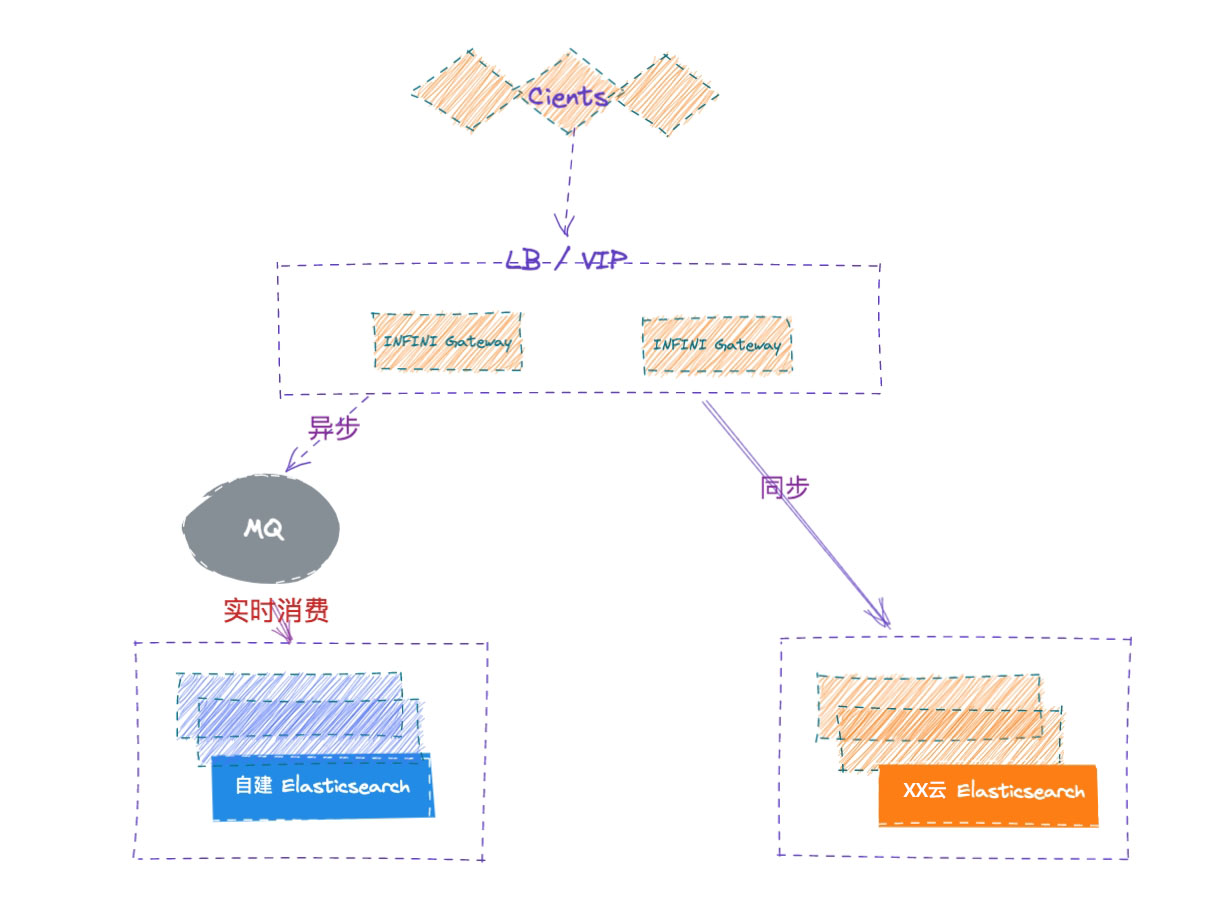 双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移到移动云 ES,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
如有任何问题,请随时联系我,期待与您交流!

背景
客户需要将 Elasticsearch 集群无缝迁移到移动云,迁移过程要保证业务的最小停机时间。
实现方式
通过采用成熟的 INFINI 网关来进行数据的双写,在集群的切换恢复过程中来记录数据变更,待全量数据恢复之后再追平后面增量数据,追平增量之后,进行校验确保数据一致再进行流量的切换。
总体流程
总体迁移流程如下:
- 客户业务代码,切流量,双写。(新增的变更都会记录在网关本地,但是暂停消费到移动云)
- 暂停网关移动云这边的增量数据消费。
- 迁移 11 月的数据,快照,快照上传到 S3;
- 下载 S3 的文件到移动云。
- 恢复快照到移动云的 11 月份的索引。
- 开启网关移动云这边的增量消费。
- 等待增量追平(接近追平)。
- 按照时间条件(如:时间 A,当前时间往前 30 分钟),验证文档数据量,Hash 校验等等。
- 停业务的写入,网关,腾讯云的写入(10 分钟)。
- 等待剩余的增量追完。
- 对时间 A 之后的,增量进行校验。
- 切换所有流量到移动云,业务端直接访问移动云 ES。
总体的迁移时间:
- 11 月备份时间(30 分钟)19 号开始
- 备份下载到移动云的时间(2-3 天)
- 备份恢复到移动云集群的时间(30 分钟)
- 11 月份增量备份(20 分钟)(双写开始)(21 号)
- 11 月份增量下载到移动云(6 小时)
- 11 月份增量恢复时间(20 分钟)
- 追增量数据(8 个小时产生的数据,需要 1 个小时)
- 校验比对(存量 1 个小时)
- 流量暂停,增量的校验(10 分钟)
- 切换(1 分钟)
总体流程如下示意图:
ES 集群信息
- ES 版本 7.10.1
- 2个热节点 3个温节点 总数 1.9 TB
- 索引 1041, 分片2085
- 无自定义插件
- 有 update_bu_query 使用
- 有 delete_by_query 使用
- 吞吐量没有测试过,当前日增文档数 1 千多万,目标日增加上亿
迁移操作手册(参考)
环境
- 自建 ES 5.4.2
- 自建 ES 5.6.8
- 自建 ES 7.5.0
- 极限网关服务器 1
- 极限网关服务器 2
- 云端负载均衡 1 (监听 9200 端口,指向极限网关服务器 1/2 的 8000 端口)
- 云端负载均衡 2 (监听 9200 端口,指向极限网关服务器 1/2 的 8001 端口)
场景描述
若干个自建 Elasticsearch 集群需要平滑迁移到移动云,业务不停写、不做代码改动。
数据架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在云端 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
数据描述
以数据从自建集群 5.4.2 迁移到云上的 5.6.16 为例进行说明,执行步骤依次说明。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过 INFINI Gateway 来进行双写。
-
系统调优
参考此文档。
- 下载程序
[root@iZbp1gxkifg8uetb33pvcoZ ~]# mkdir /opt/gateway [root@iZbp1gxkifg8uetb33pvcoZ ~]# cd /opt/gateway/ [root@iZbp1gxkifg8uetb33pvcoZ gateway]# wget http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz --2022-05-19 10:16:25-- http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:7430568 (7.1M) [application/octet-stream] 正在保存至: “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 7,430,568 22.8MB/s 用时 0.3s
2022-05-19 10:16:25 (22.8 MB/s) - 已保存 “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz” [7430568/7430568])
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# tar vxzf gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz gateway-linux-amd64 gateway.yml sample-configs/ sample-configs/elasticsearch-with-ldap.yml sample-configs/indices-replace.yml sample-configs/record_and_play.yml sample-configs/cross-cluster-search.yml sample-configs/kibana-proxy.yml sample-configs/elasticsearch-proxy.yml sample-configs/v8-bulk-indexing-compatibility.yml sample-configs/use_old_style_search_response.yml sample-configs/context-update.yml sample-configs/elasticsearch-route-by-index.yml sample-configs/hello_world.yml sample-configs/entry-with-tls.yml sample-configs/javascript.yml sample-configs/log4j-request-filter.yml sample-configs/request-filter.yml sample-configs/condition.yml sample-configs/cross-cluster-replication.yml sample-configs/secured-elasticsearch-proxy.yml sample-configs/fast-bulk-indexing.yml sample-configs/es_migration.yml sample-configs/index-docs-diff.yml sample-configs/rate-limiter.yml sample-configs/async-bulk-indexing.yml sample-configs/elasticssearch-request-logging.yml sample-configs/router_rules.yml sample-configs/auth.yml sample-configs/index-backup.yml
3. 修改配置
将网关提供的示例配置拷贝,并根据实际集群的信息进行相应的修改,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# cp sample-configs/cross-cluster-replication.yml 5.4.2TO5.6.16.yml
首先修改集群的身份信息,如下:

然后修改集群的注册信息,如下:

根据需要修改网关监听的端口,以及是否开启 TLS (如果应用客户端通过 http 协议访问 ES,请将entry.tls.enabled 值改为 false),如下:

不同的集群可以使用不同的配置,分别监听不同的端口,用于业务的分开访问。
4. 启动网关
启动网关并指定刚刚创建的配置,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml
/ \ /\ / \/\/ / /\ \ \/\ /_/\ / /\///\ / /\/\ \ \/ \/ //\_ / / /\/ \/ / // \ /\ / \/ \ ___/\/ \/\/ \/ \/ \/_/ _/_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway. [GATEWAY] 1.6.0_SNAPSHOT, 2022-05-18 11:09:54, 2023-12-31 10:10:10, 73408e82a0f96352075f4c7d2974fd274eeafe11 [05-19 13:35:43] [INF] [app.go:174] initializing gateway. [05-19 13:35:43] [INF] [app.go:175] using config: /opt/gateway/5.4.2TO5.6.16.yml. [05-19 13:35:43] [INF] [instance.go:72] workspace: /opt/gateway/data1/gateway/nodes/ca2tc22j7ad0gneois80 [05-19 13:35:43] [INF] [app.go:283] gateway is up and running now. [05-19 13:35:50] [INF] [actions.go:358] elasticsearch [primary] is available [05-19 13:35:50] [INF] [api.go:262] api listen at: http://0.0.0.0:2900 [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [entry.go:322] entry [my_es_entry/] listen at: https://0.0.0.0:8000 [05-19 13:35:50] [INF] [module.go:116] all modules are started
5. 后台运行[root@iZbp1gxkifg8uetb33pvcoZ gateway]# nohup ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml &
6. 应用授权curl -XPOST http://localhost:2900/_license/apply -d' { "license": "XXXXXXXXXXXXXXXXXXXXXXXXX" }'
#### 部署 INFINI Console
为了方便在多个集群之间快速切换,使用 INFINI [Console](https://infinilabs.cn/products/console/) 来进行管理。
1. 下载安装[root@iZbp1gxkifg8uetb33pvcpZ console]# wget http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz --2022-05-19 10:57:24-- http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:13576234 (13M) [application/octet-stream] 正在保存至: “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 13,576,234 33.2MB/s 用时 0.4s
2022-05-19 10:57:25 (33.2 MB/s) - 已保存 “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz” [13576234/13576234])
[root@iZbp1gxkifg8uetb33pvcpZ console]# tar vxzf console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz console-linux-amd64 console.yml
2. 修改配置[root@iZbp1gxkifg8uetb33pvcpZ console]# cat console.yml
for the system cluster, please use Elasticsearch v7.3+
elasticsearch:
- name: default
enabled: true
monitored: false
endpoint: http://es-cn-7mz2p9fty0007frx0.elasticsearch.aliyuncs.com:9200
basic_auth:
username: elastic
password: XXXXXX
discovery:
enabled: false
...
-
启动服务
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service install Success [root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service start Success - 访问后台
访问该主机的 9000 端口,即可打开 Console 后台,http://x.x.x.x:9000/
打开菜单 [System][Cluster] ,注册当前需要管理的 Elasticsearch 集群和网关地址,用来快速管理,如下:
测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
查看 5.4.2 集群的数据情况,如下:
查看集群 5.6.16 的数据情况,如下:
说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-to-backup和 consume-queue_primary-failure-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:
修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:
待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:
切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。
切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到云端 Elasticsearch 集群。
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用工具来导出导入,如: ESM
如果索引数量很多的话,可以按照索引依次进行导入,同时需要注意将 Mapping 和 Setting 提前导入。
以现在 5.4 集群的索引来为例,目前的待迁移索引为 demo_5_4_2,只有4 个文档:
我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/es_migration.yml 5.4TO5.6.yml修改其中代表集群和索引的相关配置,可以根据需要配置是否需要重命名索引和统一 Type( 用于跨版本统一 Type),如下图红框位置:
创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
执行完成后,可以确认下数据的情况,如下图:
全量数据至此导入完成。
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将挤压的请求应用到云端的 Elasticsearch 集群。
示例操作如下:
如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
通过观察队列是否消费完成来判断增量数据是否做完,如下:
现在我们再看一下 5.6 集群的数据情况,如下:
数据的增量更新就过来了。
执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过网关自带的数据比对工具来进行,将样例自带的文件拷贝一份,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/index-docs-diff.yml 5.4DIFF5.6.yml修改需要比对的集群和索引信息,可以加上过滤条件,如时间范围窗口来进行增量 Diff,如下图:
执行网关程序,并指定该配置文件,如下图:
如图,两个集群完全一致。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,同步写 5.6 集群。
双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移到移动云 ES,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
如有任何问题,请随时联系我,期待与您交流!
【搜索客社区日报】第1803期 (2024-03-29)
https://towardsdev.com/harness ... b0732
2、Elasticsearch 中的未捕获异常——加密 PDF 处理漏洞(8.4——8.11.1)
https://www.cve.org/CVERecord?id=CVE-2024-23449
3、Elasticsearch 开放推理 API 添加了对 Cohere 嵌入的支持
https://search-labs.elastic.co ... pport
编辑:铭毅天下
更多资讯:http://news.searchkit.cn
https://towardsdev.com/harness ... b0732
2、Elasticsearch 中的未捕获异常——加密 PDF 处理漏洞(8.4——8.11.1)
https://www.cve.org/CVERecord?id=CVE-2024-23449
3、Elasticsearch 开放推理 API 添加了对 Cohere 嵌入的支持
https://search-labs.elastic.co ... pport
编辑:铭毅天下
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1802期 (2024-03-28)
https://www.bilibili.com/video/BV1wC411a7tk
2.解锁可观测性:Spring Boot 中的结构化日志记录(需要梯子)
https://medium.com/booking-com ... fb9e7
3.Openllmetry: 基于 OpenTelemetry 的 LLM 应用程序可观测性监控
https://github.com/traceloop/openllmetry
4.OpenTelemetry 和 Elastic:携手为社区建立持续分析
https://www.elastic.co/blog/el ... metry
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://www.bilibili.com/video/BV1wC411a7tk
2.解锁可观测性:Spring Boot 中的结构化日志记录(需要梯子)
https://medium.com/booking-com ... fb9e7
3.Openllmetry: 基于 OpenTelemetry 的 LLM 应用程序可观测性监控
https://github.com/traceloop/openllmetry
4.OpenTelemetry 和 Elastic:携手为社区建立持续分析
https://www.elastic.co/blog/el ... metry
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
7 年+积累、 Elastic 创始人Shay Banon 等 15 位专家推荐的 Elasticsearch 8.X新书《一本书讲透Elasticsearch》已上线...
今天,非常高兴地跟大家宣布,经过 7 年多的努力和精心准备,我们的新书《一本书讲透 Elasticsearch》已正式出版上线!

我从 2016 年接触 Elasticsearch 1.X、2.X 的版本,到现在已经接近 8 年+的时间。在这期间,我常常被问到:
如何系统性地学习 Elasticsearch ?
如何将现有的关系型数据库迁移到 ES ?
如何选择合适的版本?
如何规划和监控集群?
如何进行数据建模?
如何选择合适的检索方式?
如何基于现有数据进行可视化分析?
等一系列问题.......
这些问题促使我将之前的产品开发、项目实战经验和咨询经验进行全面整合,并精心梳理,融入到这本新书中,希望能让大家少走不必要的弯路。
一、书籍特点 本书具有以下几个显著特点:
最新版本,前沿知识点
本书基于 8.x 版本编写,涵盖了如索引生命周期管理、快照生命周期管理、数据流 datastream 等至关重要的新特性。
核心知识,系统认知
我们为您提供了清晰的学习路径,保留了最核心的“最少必要”知识点,并通过思维导图和大量图解内容,帮助读者更易理解和吸收。
实际应用,超越认证
覆盖Elastic官方认证的核心知识点,已帮助近200人通过Elastic专家认证考试。内容不仅限于认证,更注重实际应用。
来源于实战,应用于实战
书中内容源自真实项目案例和企业级问题解答(问题来自于Elasticsearch中文社区、死磕Elasticsearch知识星球、微信群、QQ群等)。涵盖3个实战项目,助力读者将技能应用到企业实战环境中。
代码开源,答疑服务
全书的代码、脚本在GitHub上开源,便于初学者通过实践学习。我们的答疑社群将持续跟踪最新问题,不断迭代更新内容。
二、5 个最尖锐问题快问快答 如下的问题来自 ChatGPT 4.0 的作为专业读者提出的 5 个最尖锐问题。

我快速回答一下:
2.1 问题1:市场竞争和定位问题 “市面上已有接近10本关于Elasticsearch的书籍,您的书与这些现有书籍相比有何独特之处?您是如何确保您的书在内容上与其他书籍区别开来,满足读者新的或更深入的需求的?”
铭毅天下:
1、独特之处:版本咱们是目前市场唯一的 8.X 版本。
2、区别开来:我从 2016 年开始搞 ElasticStack 到现在几乎平均每周一篇技术博客,从未间断。无需多说,时间能证明一切!这是咱们最大的不同之一。
3、还有不同:我自己公众号+博客有累计近 4.5 万+关注读者,知识星球有近2000人付费用户,这些大量的实战问题促使我唯有“自我革命”才能生存和成长!
2.2 问题2:实用性和更新性问题 “鉴于Elasticsearch技术持续发展和迭代,您的书籍是如何处理和包含最新版本的特性和变化的?在提供最新信息的同时,您如何保证书中内容的长期有效性和实用性?”
铭毅天下:
1、实话说结论,我做不到,市面上任何纸质书都不可能做到。受限于撰写、出版等相较于 Elastic技术栈体系更新的滞后性。
2、但是,我在筛选知识点的时候已充分考虑结合企业级实战以及 Elastic 官方认证考试的最核心、最关键的“最少必要知识”作为咱们的提纲,并且承诺后面继续根据读者反馈迭代和升级。
2.3 问题3:作者经验和权威性问题 “您能否分享一些您个人在Elasticsearch领域的实战经验或特殊贡献,这些经验如何在您的书中得到体现?作为作者,您相比其他书籍作者有哪些独特的优势或视角?”
铭毅天下:
1、本人持续深耕大数据存储和检索领域 7 年+,有博客为证!有丰富的项目实战经验和企业级实战问题咨询经验,已带领近200人+通过 Elastic 认证专家考试。
2、独特视角就是:来自全国乃至全球多个国家的实战问题——自己运营的知识星球、微信群、QQ群多达数千人,每天都有大量实战问题涌现。
3、作者是坚定的长期主义者:博客已写12年+,从未间断!相信积累的力量、相信坚持的力量、相信相信的力量!
2.4 问题4:读者受益问题 “您认为读者在阅读您的书籍之后,最具体和显著的收获会是什么?有哪些实际的技能或知识可以直接应用到他们的工作和项目中?”
铭毅天下:
1、少走不必要的弯路!
2、能获得属于自己的专属学习路线,能建立专属的知识体系,能将 Elasticsearch 原理、开发、运维、架构技能应用于实战。
2.5 问题5:内容深度和广度问题 “您的书籍是如何平衡Elasticsearch的基础知识和高级技术的?它是否适合所有水平的读者,从初学者到高级用户?对于那些已经具有深厚Elasticsearch知识背景的读者,您的书提供了哪些更深入的见解或独特内容?”
铭毅天下:
1、适合大数据存储和检索领域的初学者,也同样适合有工作经验的中级、高级工程师、架构师等。
2、对于深厚Elasticsearch知识背景的读者,本书可以当做工具书,需要时备查、常翻常新。
三、行业顶级大佬的推荐

值得一提的是,这本书获得了 Elastic 创始人兼CTO Shay Banon 、Elastic中文社区创始人兼极限科技CTO等15位顶级专家的强力推荐,是一本不可多得的Elasticsearch学习材料。
I am very happy to see that Elasticsearch has been widely used in China, which fully reflects the open source, free and open power of Elastic. This book is derived from the author's 7 years of technical accumulation and embodies the author's love for ElasticStack open source technology. I hope this book can help more people understand Elasticsearch and search technology, so as to discover the great value of data. I am convinced that this book will have a profound impact on Elastic's Chinese community.
我很高兴看到Elasticsearch在中国得到了广泛的应用,这充分体现了Elastic开源、自由、开放的力量。本书源自作者7年的技术积累,体现了作者对ElasticStack开源技术的热爱。希望这本书能够帮助更多的人了解Elasticsearch和搜索技术,从而发现数据的巨大价值。我相信这本书将对 Elastic 的中文社区产生深远的影响。

——Shay Banon Elastic公司创始人兼首席技术官
很高兴看到铭毅天下的新书出版,《一本书讲透Elasticsearch:原理、进阶与工程实践》是一本值得推荐的新书。它汇集了作者丰富的实战经验,深入探讨 Elasticsearch的 核心原理。书中丰富的图解和清晰的结构使得复杂的知识易于理解和吸收。同时,它覆盖了 Elastic 认证考试的所有考点,助力读者建立全面的认知。此外,书中还包含实战项目,帮助读者将所学技能应用到实际场景中。作者拥有多年实战经验和广泛的影响力,这本书将成为学习和应用 Elasticsearch 的重要指南。
——Medcl,Elastic 中文社区创始人、极限科技创始人
铭毅天下是ES中文社区里少有的常年坚持写作的技术博主,尤其擅长将点状发散的社区讨论进行归纳总结,结合自己的实践和再思考,形成系统性的系列技术文章。本书成于作者在Elasticsearch领域多年的理论知识沉淀,并涵盖了实际应用场景的最佳实践。无论你是Elasticsearch初学者还是有一定经验的开发者,相信都能通过阅读本书而受益匪浅。
—— 吴晓刚 (Wood大叔)携程旅行网 企业数字化平台部 研发总监
在大数据检索和分析领域,Elastic Stack 技术栈有广泛应用,本书从业务场景出发详细介绍了在 Elasticsearch 擅长的各类场景中完成业务系统开发所需的技术栈和技术手段,为用户系统选型和了解整体技术架构提供了指导,可以帮助用户少走弯路,快速完成系统建设。
——张超 《Elasticsearch 源码解析与优化实战》作者, Elasticsearch 内核资深研发工程师
本书基于Elasticsearch最新的8.X版本,涵盖了Elasticsearch更加完整、实时的功能。作者拥有丰富的Elasticsearch和写作经验,语言通俗易懂,内容详尽全面。无论你是初学者还是有一定经验的开发人员,本书都能够为你提供更深入的内容和最佳实践。如果你想系统地学习、掌握Elasticsearch,那么这本书绝对是你不可错过的参考书籍。
—— 魏子珺,阿里巴巴elasticsearch内核专家
很高兴为大家推荐这本关于Elasticsearch的技术书籍。本书涵盖了相当丰富的原理讲解和实现技术,更重要的是对实战场景给出了明确的指导案例和代码片段可供参考和使用。即面向开发人员深入讲解了搜索引擎的核心算法与数据结构,也同时给运维人员提供了关键指标的定义和解读。对于想系统学习的初、中级用户,可以按照章节循序渐进的阅读。对于高级用户来说,也可以从 遇到的问题为切入点,直接从某个具体章节入手来测试、寻求解决方案。铭毅天下是Elastic中文社区长期活跃和积极贡献的明星成员。非常兴奋看到他把自己日积月累的知识精华和经验总结在书中分享给广大读者。我相信本书一定可以帮助到处在任何阶段想学习探索Elasticsearch的用户。
——吴斌,Elastic中文社区主席
《一本书讲透Elasticsearch:原理、进阶与工程实践》是一本由一线开发人员撰写的实战指南。作者凭借多年的 Elasticsearch 咨询和教学经验,将复杂的概念以简明易懂的方式呈现给读者。这本书将帮助你深入了解 Elasticsearch,并理解其背后的原理和逻辑。通过学习本书,你将获得全面的知识,从而能够灵活应用 Elasticsearch 解决各种实际问题。相信这本书将成为你掌握 Elasticsearch 的必备工具。
——阮一鸣,eBay 高级研发经理、极客时间『Elasticsearch 核心技术与实战』课程讲师
铭毅在 Elasticsearch 领域深耕多年,勤奋且专注, 同时运营着国内最大的 ES 社群 ,帮助许多同学成功通过了有难度的 Elastic 认证工程师考试。很高兴看到他的新书出版,都说万事开头难,但我相信这本书能够为ES 初学者铺平道路,扫除障碍,澄清疑虑,快速上手!推荐大家阅读!
——魏彬,中国首位 Elastic 认证工程师
《一本书讲透Elasticsearch:原理、进阶与工程实践 》这本书是我极力推荐的一部作品!
我认识铭毅天下很久了,第一次见面记得是2019年在北京的Elastic开发者大会上,但在这之前,我就经常阅读他关于Elasticsearch的技术分享而神交已久。我了解的铭毅天下是一位拥有丰富的Elasticsearch领域知识和经验的专家,他曾在PB级大数据系统项目中发挥关键作用。实施这种大规模,长周期的复杂项目是非常不容易的,无论从系统设计,到实施过程中的问题解决。因此,来自于实践的真知产出,值得我们开卷。
多年来,铭毅天下一直积极、高效地在各种博客和社交媒体上分享与Elasticsearch相关的内容,并密切同步每个版本的更新。在Elasticsearch上,他不仅持续自我精进,还组织了学习小组和社区,帮助其他对Elasticsearch感兴趣的伙伴一起进步。他还带领150多人通过Elastic工程师认证,为许多人的职业发展贡献了力量。
这本书是铭毅天下多年经验的总结,内容涵盖了几乎全部的Elastic认证考点,而且它来自铭毅天下近7年的博客积累,每一章节都经得起时间的考验。因为抓住了平时学习和使用Elasticsearch当中痛点并总结了最佳实践,这些内容不仅阅读量高,而且转发度也很广泛。无论你是想深入了解Elasticsearch的基础知识还是应用实践,这本书都能满足你的需求。
我相信这本书将为读者提供一次全面而深入的学习体验,帮助他们在Elasticsearch领域取得突破。无论你是初学者还是有经验的专业人士,这本书都是不可或缺的指南。我由衷地推荐这本书,相信它会成为你在Elasticsearch学习和实践中的得力伙伴!
——李捷,Elastic 解决方案架构师 Principle Solution Architect
当得知本书成稿的消息时,我的心情是非常激动的,不管是作为一名技术人,还是作为一名搜索引擎的从业者,以及作为一名Elasticsearch中文社区的参与者和建设者。本书作者与我们一起见证了Elastic生态在国内的起步、发展以及到今天的繁荣;有所不同的是,作者有超强的毅力(就像铭毅天下的名字一样),坚持在这个技术方向上深耕了7年之久,在知识、技术和实践等方面有着深厚的经验积累,不但亲力亲为,而且深谙知识社群与实践社区CoP的操盘之道,在自我成长的同时也打造了优质的同行网络,积极影响了一批技术人,其中的优秀者更是通过了Elatics官方认证,极具含金量。本书的出版,一定会给更多技术人带来直接或间接的帮助,同时在个人成长、知识共享与实践社区等方面在业内树立成功的榜样。让我们一起用技术影响世界影响人!
—— 杨振涛,Elastisearch中文社区深圳主席|vivo互联网 研发总监
Elasticsearch是人工智能和大数据时代不可或缺的重要产品,已经成为开发者必备技能。本书汇集了作者多年开发经验、咨询经验、数千个Elasticsearch爱好者的最佳实战。因此在讲解原理的同时,能深入到最佳实践中去,做到深入浅出,非常适合Elasticsearch的初学者以及进阶者。
—— 付磊,快手Elasticsearch负责人,《Redis开发与运维》作者
Elasticsearch 作为一款强大又灵活的数据分析检索工具,值得每一位后端程序员认真学习。铭毅天下的这本《一本书讲透Elasticsearch:原理、进阶与工程实践》,用浅显易懂的语言介绍了Elasticsearch的概念、原理和实践,非常值得阅读!
—— 程序员小灰,公众号【程序员小灰】运营者,畅销书《漫画算法》作者
铭毅是我的老友,他是一个及其认证踏实和执着追究技术的人,这七年来他一直热心Elasticstack相关技术的步道,热忱帮助社区和公众号里的伙伴,成就不俗。本书是一本实用性极高的Elasticsearch的实践类书籍,更是铭毅倾尽所学之作。通读原稿后,让我非常欣赏的地方在于,它是市面上难得一见的把Elasticsearch原理,实现方式,最佳实践,以及实战案例串联在一起实操类书籍,无论是初学者还是需要进阶学习的人员都能从中获取想要的内容。十分适合想要在企业环境中落地Elasticsearch的人们,因此我诚意把它推荐给广大的技术爱好者和相关从业人员。
——周钰, IBM中国 企业架构师 中国前50 Elastic持证者
Elasticsearch作为一款优秀的开源分布式搜索引擎,被广泛应用在日志分析、站内搜索、指标监控、数据加速等场景,学习并掌握ES,已经成为一个技术工作人员不可或缺的重要技能之一。而本书深入浅出,对Elasticsearch的基本概念、设计原理及实践进行了详细介绍,是学习Elasticsearch的必备资料。诚挚推荐。
—— 吴荣,Elasticsearch平台资深研发工程师
一份专业、细致、用户友好的技术文档能给我们技术人员的日常工作带来多大的帮助,相信大家都有深刻的体会,特别是像Elasticsearch这种在搜索引擎领域最广泛应用的解决方案更是如此。虽然官方文档内容很详尽,更新很及时,但是限于语言、网速等问题,广大国内开发者并不能很准确高效的找到自己需要的内容。铭毅老师这本,兼顾了内容的专业性、严谨性、完整性,围绕着Elasticsearch及其相关组件所撰写,覆盖了从基础概念到高级用法的方方面面内容的专业书籍,能给各位带来的价值就不言而喻了。这本书适合从入门使用到高级调优的各层次的读者,是一本少有的适合放在案头常看常新的书。
—— 陈晨(死敌wen),资深搜索架构师、Elastic认证专家

15位大佬评价批量导入 Elasticsearch
15位大佬评价 Kibana 可视化

15位大佬评价词云图

无论您是大数据检索领域的初学者、开发和运维人员,还是架构师和管理人员,这本书都将成为实战路上的得力助手和“避坑指南”。

立即购买以获取专属福利:不论您从哪里购买、不论多少费用购买,记得保留购物链接和发票,费用都可以折算同等价格的星球优惠券。
私V信:elastic6 搞定后续一切流程。 ————————————————
本文为博主原创文章,未经博主书面授权不得转载。书面授权后方可转载,但转载请务必加上原作者:铭毅天下,原文地址:blog.csdn.net/laoyang360原文链接:https://blog.csdn.net/laoyang360/article/details/135614659
今天,非常高兴地跟大家宣布,经过 7 年多的努力和精心准备,我们的新书《一本书讲透 Elasticsearch》已正式出版上线!
我从 2016 年接触 Elasticsearch 1.X、2.X 的版本,到现在已经接近 8 年+的时间。在这期间,我常常被问到:
如何系统性地学习 Elasticsearch ?
如何将现有的关系型数据库迁移到 ES ?
如何选择合适的版本?
如何规划和监控集群?
如何进行数据建模?
如何选择合适的检索方式?
如何基于现有数据进行可视化分析?
等一系列问题.......
这些问题促使我将之前的产品开发、项目实战经验和咨询经验进行全面整合,并精心梳理,融入到这本新书中,希望能让大家少走不必要的弯路。
一、书籍特点 本书具有以下几个显著特点:
最新版本,前沿知识点
本书基于 8.x 版本编写,涵盖了如索引生命周期管理、快照生命周期管理、数据流 datastream 等至关重要的新特性。
核心知识,系统认知
我们为您提供了清晰的学习路径,保留了最核心的“最少必要”知识点,并通过思维导图和大量图解内容,帮助读者更易理解和吸收。
实际应用,超越认证
覆盖Elastic官方认证的核心知识点,已帮助近200人通过Elastic专家认证考试。内容不仅限于认证,更注重实际应用。
来源于实战,应用于实战
书中内容源自真实项目案例和企业级问题解答(问题来自于Elasticsearch中文社区、死磕Elasticsearch知识星球、微信群、QQ群等)。涵盖3个实战项目,助力读者将技能应用到企业实战环境中。
代码开源,答疑服务
全书的代码、脚本在GitHub上开源,便于初学者通过实践学习。我们的答疑社群将持续跟踪最新问题,不断迭代更新内容。
二、5 个最尖锐问题快问快答 如下的问题来自 ChatGPT 4.0 的作为专业读者提出的 5 个最尖锐问题。
我快速回答一下:
2.1 问题1:市场竞争和定位问题 “市面上已有接近10本关于Elasticsearch的书籍,您的书与这些现有书籍相比有何独特之处?您是如何确保您的书在内容上与其他书籍区别开来,满足读者新的或更深入的需求的?”
铭毅天下:
1、独特之处:版本咱们是目前市场唯一的 8.X 版本。
2、区别开来:我从 2016 年开始搞 ElasticStack 到现在几乎平均每周一篇技术博客,从未间断。无需多说,时间能证明一切!这是咱们最大的不同之一。
3、还有不同:我自己公众号+博客有累计近 4.5 万+关注读者,知识星球有近2000人付费用户,这些大量的实战问题促使我唯有“自我革命”才能生存和成长!
2.2 问题2:实用性和更新性问题 “鉴于Elasticsearch技术持续发展和迭代,您的书籍是如何处理和包含最新版本的特性和变化的?在提供最新信息的同时,您如何保证书中内容的长期有效性和实用性?”
铭毅天下:
1、实话说结论,我做不到,市面上任何纸质书都不可能做到。受限于撰写、出版等相较于 Elastic技术栈体系更新的滞后性。
2、但是,我在筛选知识点的时候已充分考虑结合企业级实战以及 Elastic 官方认证考试的最核心、最关键的“最少必要知识”作为咱们的提纲,并且承诺后面继续根据读者反馈迭代和升级。
2.3 问题3:作者经验和权威性问题 “您能否分享一些您个人在Elasticsearch领域的实战经验或特殊贡献,这些经验如何在您的书中得到体现?作为作者,您相比其他书籍作者有哪些独特的优势或视角?”
铭毅天下:
1、本人持续深耕大数据存储和检索领域 7 年+,有博客为证!有丰富的项目实战经验和企业级实战问题咨询经验,已带领近200人+通过 Elastic 认证专家考试。
2、独特视角就是:来自全国乃至全球多个国家的实战问题——自己运营的知识星球、微信群、QQ群多达数千人,每天都有大量实战问题涌现。
3、作者是坚定的长期主义者:博客已写12年+,从未间断!相信积累的力量、相信坚持的力量、相信相信的力量!
2.4 问题4:读者受益问题 “您认为读者在阅读您的书籍之后,最具体和显著的收获会是什么?有哪些实际的技能或知识可以直接应用到他们的工作和项目中?”
铭毅天下:
1、少走不必要的弯路!
2、能获得属于自己的专属学习路线,能建立专属的知识体系,能将 Elasticsearch 原理、开发、运维、架构技能应用于实战。
2.5 问题5:内容深度和广度问题 “您的书籍是如何平衡Elasticsearch的基础知识和高级技术的?它是否适合所有水平的读者,从初学者到高级用户?对于那些已经具有深厚Elasticsearch知识背景的读者,您的书提供了哪些更深入的见解或独特内容?”
铭毅天下:
1、适合大数据存储和检索领域的初学者,也同样适合有工作经验的中级、高级工程师、架构师等。
2、对于深厚Elasticsearch知识背景的读者,本书可以当做工具书,需要时备查、常翻常新。
三、行业顶级大佬的推荐
值得一提的是,这本书获得了 Elastic 创始人兼CTO Shay Banon 、Elastic中文社区创始人兼极限科技CTO等15位顶级专家的强力推荐,是一本不可多得的Elasticsearch学习材料。
I am very happy to see that Elasticsearch has been widely used in China, which fully reflects the open source, free and open power of Elastic. This book is derived from the author's 7 years of technical accumulation and embodies the author's love for ElasticStack open source technology. I hope this book can help more people understand Elasticsearch and search technology, so as to discover the great value of data. I am convinced that this book will have a profound impact on Elastic's Chinese community.
我很高兴看到Elasticsearch在中国得到了广泛的应用,这充分体现了Elastic开源、自由、开放的力量。本书源自作者7年的技术积累,体现了作者对ElasticStack开源技术的热爱。希望这本书能够帮助更多的人了解Elasticsearch和搜索技术,从而发现数据的巨大价值。我相信这本书将对 Elastic 的中文社区产生深远的影响。
——Shay Banon Elastic公司创始人兼首席技术官
很高兴看到铭毅天下的新书出版,《一本书讲透Elasticsearch:原理、进阶与工程实践》是一本值得推荐的新书。它汇集了作者丰富的实战经验,深入探讨 Elasticsearch的 核心原理。书中丰富的图解和清晰的结构使得复杂的知识易于理解和吸收。同时,它覆盖了 Elastic 认证考试的所有考点,助力读者建立全面的认知。此外,书中还包含实战项目,帮助读者将所学技能应用到实际场景中。作者拥有多年实战经验和广泛的影响力,这本书将成为学习和应用 Elasticsearch 的重要指南。
——Medcl,Elastic 中文社区创始人、极限科技创始人
铭毅天下是ES中文社区里少有的常年坚持写作的技术博主,尤其擅长将点状发散的社区讨论进行归纳总结,结合自己的实践和再思考,形成系统性的系列技术文章。本书成于作者在Elasticsearch领域多年的理论知识沉淀,并涵盖了实际应用场景的最佳实践。无论你是Elasticsearch初学者还是有一定经验的开发者,相信都能通过阅读本书而受益匪浅。
—— 吴晓刚 (Wood大叔)携程旅行网 企业数字化平台部 研发总监
在大数据检索和分析领域,Elastic Stack 技术栈有广泛应用,本书从业务场景出发详细介绍了在 Elasticsearch 擅长的各类场景中完成业务系统开发所需的技术栈和技术手段,为用户系统选型和了解整体技术架构提供了指导,可以帮助用户少走弯路,快速完成系统建设。
——张超 《Elasticsearch 源码解析与优化实战》作者, Elasticsearch 内核资深研发工程师
本书基于Elasticsearch最新的8.X版本,涵盖了Elasticsearch更加完整、实时的功能。作者拥有丰富的Elasticsearch和写作经验,语言通俗易懂,内容详尽全面。无论你是初学者还是有一定经验的开发人员,本书都能够为你提供更深入的内容和最佳实践。如果你想系统地学习、掌握Elasticsearch,那么这本书绝对是你不可错过的参考书籍。
—— 魏子珺,阿里巴巴elasticsearch内核专家
很高兴为大家推荐这本关于Elasticsearch的技术书籍。本书涵盖了相当丰富的原理讲解和实现技术,更重要的是对实战场景给出了明确的指导案例和代码片段可供参考和使用。即面向开发人员深入讲解了搜索引擎的核心算法与数据结构,也同时给运维人员提供了关键指标的定义和解读。对于想系统学习的初、中级用户,可以按照章节循序渐进的阅读。对于高级用户来说,也可以从 遇到的问题为切入点,直接从某个具体章节入手来测试、寻求解决方案。铭毅天下是Elastic中文社区长期活跃和积极贡献的明星成员。非常兴奋看到他把自己日积月累的知识精华和经验总结在书中分享给广大读者。我相信本书一定可以帮助到处在任何阶段想学习探索Elasticsearch的用户。
——吴斌,Elastic中文社区主席
《一本书讲透Elasticsearch:原理、进阶与工程实践》是一本由一线开发人员撰写的实战指南。作者凭借多年的 Elasticsearch 咨询和教学经验,将复杂的概念以简明易懂的方式呈现给读者。这本书将帮助你深入了解 Elasticsearch,并理解其背后的原理和逻辑。通过学习本书,你将获得全面的知识,从而能够灵活应用 Elasticsearch 解决各种实际问题。相信这本书将成为你掌握 Elasticsearch 的必备工具。
——阮一鸣,eBay 高级研发经理、极客时间『Elasticsearch 核心技术与实战』课程讲师
铭毅在 Elasticsearch 领域深耕多年,勤奋且专注, 同时运营着国内最大的 ES 社群 ,帮助许多同学成功通过了有难度的 Elastic 认证工程师考试。很高兴看到他的新书出版,都说万事开头难,但我相信这本书能够为ES 初学者铺平道路,扫除障碍,澄清疑虑,快速上手!推荐大家阅读!
——魏彬,中国首位 Elastic 认证工程师
《一本书讲透Elasticsearch:原理、进阶与工程实践 》这本书是我极力推荐的一部作品!
我认识铭毅天下很久了,第一次见面记得是2019年在北京的Elastic开发者大会上,但在这之前,我就经常阅读他关于Elasticsearch的技术分享而神交已久。我了解的铭毅天下是一位拥有丰富的Elasticsearch领域知识和经验的专家,他曾在PB级大数据系统项目中发挥关键作用。实施这种大规模,长周期的复杂项目是非常不容易的,无论从系统设计,到实施过程中的问题解决。因此,来自于实践的真知产出,值得我们开卷。
多年来,铭毅天下一直积极、高效地在各种博客和社交媒体上分享与Elasticsearch相关的内容,并密切同步每个版本的更新。在Elasticsearch上,他不仅持续自我精进,还组织了学习小组和社区,帮助其他对Elasticsearch感兴趣的伙伴一起进步。他还带领150多人通过Elastic工程师认证,为许多人的职业发展贡献了力量。
这本书是铭毅天下多年经验的总结,内容涵盖了几乎全部的Elastic认证考点,而且它来自铭毅天下近7年的博客积累,每一章节都经得起时间的考验。因为抓住了平时学习和使用Elasticsearch当中痛点并总结了最佳实践,这些内容不仅阅读量高,而且转发度也很广泛。无论你是想深入了解Elasticsearch的基础知识还是应用实践,这本书都能满足你的需求。
我相信这本书将为读者提供一次全面而深入的学习体验,帮助他们在Elasticsearch领域取得突破。无论你是初学者还是有经验的专业人士,这本书都是不可或缺的指南。我由衷地推荐这本书,相信它会成为你在Elasticsearch学习和实践中的得力伙伴!
——李捷,Elastic 解决方案架构师 Principle Solution Architect
当得知本书成稿的消息时,我的心情是非常激动的,不管是作为一名技术人,还是作为一名搜索引擎的从业者,以及作为一名Elasticsearch中文社区的参与者和建设者。本书作者与我们一起见证了Elastic生态在国内的起步、发展以及到今天的繁荣;有所不同的是,作者有超强的毅力(就像铭毅天下的名字一样),坚持在这个技术方向上深耕了7年之久,在知识、技术和实践等方面有着深厚的经验积累,不但亲力亲为,而且深谙知识社群与实践社区CoP的操盘之道,在自我成长的同时也打造了优质的同行网络,积极影响了一批技术人,其中的优秀者更是通过了Elatics官方认证,极具含金量。本书的出版,一定会给更多技术人带来直接或间接的帮助,同时在个人成长、知识共享与实践社区等方面在业内树立成功的榜样。让我们一起用技术影响世界影响人!
—— 杨振涛,Elastisearch中文社区深圳主席|vivo互联网 研发总监
Elasticsearch是人工智能和大数据时代不可或缺的重要产品,已经成为开发者必备技能。本书汇集了作者多年开发经验、咨询经验、数千个Elasticsearch爱好者的最佳实战。因此在讲解原理的同时,能深入到最佳实践中去,做到深入浅出,非常适合Elasticsearch的初学者以及进阶者。
—— 付磊,快手Elasticsearch负责人,《Redis开发与运维》作者
Elasticsearch 作为一款强大又灵活的数据分析检索工具,值得每一位后端程序员认真学习。铭毅天下的这本《一本书讲透Elasticsearch:原理、进阶与工程实践》,用浅显易懂的语言介绍了Elasticsearch的概念、原理和实践,非常值得阅读!
—— 程序员小灰,公众号【程序员小灰】运营者,畅销书《漫画算法》作者
铭毅是我的老友,他是一个及其认证踏实和执着追究技术的人,这七年来他一直热心Elasticstack相关技术的步道,热忱帮助社区和公众号里的伙伴,成就不俗。本书是一本实用性极高的Elasticsearch的实践类书籍,更是铭毅倾尽所学之作。通读原稿后,让我非常欣赏的地方在于,它是市面上难得一见的把Elasticsearch原理,实现方式,最佳实践,以及实战案例串联在一起实操类书籍,无论是初学者还是需要进阶学习的人员都能从中获取想要的内容。十分适合想要在企业环境中落地Elasticsearch的人们,因此我诚意把它推荐给广大的技术爱好者和相关从业人员。
——周钰, IBM中国 企业架构师 中国前50 Elastic持证者
Elasticsearch作为一款优秀的开源分布式搜索引擎,被广泛应用在日志分析、站内搜索、指标监控、数据加速等场景,学习并掌握ES,已经成为一个技术工作人员不可或缺的重要技能之一。而本书深入浅出,对Elasticsearch的基本概念、设计原理及实践进行了详细介绍,是学习Elasticsearch的必备资料。诚挚推荐。
—— 吴荣,Elasticsearch平台资深研发工程师
一份专业、细致、用户友好的技术文档能给我们技术人员的日常工作带来多大的帮助,相信大家都有深刻的体会,特别是像Elasticsearch这种在搜索引擎领域最广泛应用的解决方案更是如此。虽然官方文档内容很详尽,更新很及时,但是限于语言、网速等问题,广大国内开发者并不能很准确高效的找到自己需要的内容。铭毅老师这本,兼顾了内容的专业性、严谨性、完整性,围绕着Elasticsearch及其相关组件所撰写,覆盖了从基础概念到高级用法的方方面面内容的专业书籍,能给各位带来的价值就不言而喻了。这本书适合从入门使用到高级调优的各层次的读者,是一本少有的适合放在案头常看常新的书。
—— 陈晨(死敌wen),资深搜索架构师、Elastic认证专家
15位大佬评价批量导入 Elasticsearch
15位大佬评价 Kibana 可视化
15位大佬评价词云图
无论您是大数据检索领域的初学者、开发和运维人员,还是架构师和管理人员,这本书都将成为实战路上的得力助手和“避坑指南”。
立即购买以获取专属福利:不论您从哪里购买、不论多少费用购买,记得保留购物链接和发票,费用都可以折算同等价格的星球优惠券。
私V信:elastic6 搞定后续一切流程。 ————————————————
本文为博主原创文章,未经博主书面授权不得转载。书面授权后方可转载,但转载请务必加上原作者:铭毅天下,原文地址:blog.csdn.net/laoyang360原文链接:https://blog.csdn.net/laoyang360/article/details/135614659
收起阅读 »【搜索客社区日报】第1801期 (2024-03-26)
https://medium.com/%40davis.an ... 11076
2. 一组用来生成学习辅助对话的prompt
https://quail.ink/op7418/p/bao ... ci-ku
3. (目前最好的)AI 歌曲生成器
https://app.suno.ai/create/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40davis.an ... 11076
2. 一组用来生成学习辅助对话的prompt
https://quail.ink/op7418/p/bao ... ci-ku
3. (目前最好的)AI 歌曲生成器
https://app.suno.ai/create/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】 第1800期 (2024-03-25)
https://blog.csdn.net/weixin_3 ... 46906
2 从源码角度剖析 Elasticserach 段合并调优策略
https://blog.itpub.net/70027827/viewspace-2979219/
3、技术神秘化的去魅:Sora关键技术逆向工程图解
https://zhuanlan.zhihu.com/p/687928845
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/weixin_3 ... 46906
2 从源码角度剖析 Elasticserach 段合并调优策略
https://blog.itpub.net/70027827/viewspace-2979219/
3、技术神秘化的去魅:Sora关键技术逆向工程图解
https://zhuanlan.zhihu.com/p/687928845
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1799期 (2024-03-21)
https://levelup.gitconnected.c ... 7f043
2.构建RAG知识图谱
https://learn.deeplearning.ai/ ... ments
3.重新构想基于AI的平台工程(1): AI开发工具和平台的探秘之旅
https://mp.weixin.qq.com/s/NTzNnBG4D6wrVvcGD8xWnA
4.电商场景下 ES 搜索引擎的稳定性治理实践
https://mp.weixin.qq.com/s/fAgAgWWYJbbfcGGx1BpLsw
5.MultiHop-RAG 介绍(需要梯子)
https://cobusgreyling.medium.c ... 4eeda
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://levelup.gitconnected.c ... 7f043
2.构建RAG知识图谱
https://learn.deeplearning.ai/ ... ments
3.重新构想基于AI的平台工程(1): AI开发工具和平台的探秘之旅
https://mp.weixin.qq.com/s/NTzNnBG4D6wrVvcGD8xWnA
4.电商场景下 ES 搜索引擎的稳定性治理实践
https://mp.weixin.qq.com/s/fAgAgWWYJbbfcGGx1BpLsw
5.MultiHop-RAG 介绍(需要梯子)
https://cobusgreyling.medium.c ... 4eeda
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
探索搜索引擎的新时代:Windows 安装 Easysearch 完全指南
相信最近大家都已经听过Easysearch的名头,成功拿下了墨天轮搜索型数据库的榜首!什么?您不知道?那我再给您介绍下: INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。 相信看完了上面您已经对使用Easysearch有了想法,不要想,行动!我将带领您在windows环境中使用Easysearch,有几种安装方法可供选择!
方法一:使用Docker
对于已在Windows系统上安装了Docker的用户来说,通过Docker安装Easysearch是最直接高效的方法。接下来我将介绍Docker部署Easysearch的方法,如果没有安装Docker请跳过!
Docker 环境下使用 Easysearch
在使用 Docker 运行 Easysearch 之前,请确保已进行系统调优并安装好Docker服务,且Docker服务正常运行。
最快方式:启动临时的docker容器,可以从前台查看到admin的初始密码
```bash
docker run --name easysearch -p 9200:9200 dockerproxy.com/infinilabs/easysearch:latest个性配置
从宿主机挂载数据目录及日志目录,并配置jvm内存为512m。
-
在宿主机上创建目录
bashCopy code sudo mkdir -p /data/easysearch/{data,logs} -
修改目录权限
bashCopy code # 容器内es用户的uid为602,通过调整宿主机的目录权限,确保在容器内部es用户有权限读写挂载的数据卷 sudo chown -R 602.602 /data/easysearch -
后台运行容器
bashCopy code docker run -d --restart always -p 9200:9200 \ -e ES_JAVA_OPTS="-Xms512m -Xmx512m" \ -v /data/easysearch/data:/app/easysearch/data \ -v /data/easysearch/logs:/app/easysearch/logs \ --name easysearch --hostname easysearch \ dockerproxy.com/infinilabs/easysearch:latest -
查看初始密码
bashCopy code # 由于以上容器是后台启动,需要通过日志找出admin的初始密码 docker logs easysearch 2>/dev/null | grep -w Usage容器启停
-
启动容器
bashCopy code docker start easysearch -
停止容器
bashCopy code docker stop easysearch后续验证工作,请继续查看安装指南。
方法二:不使用HTTPS安装Easysearch
在某些情况下,您可能需要或者偏好不通过HTTPS方式进行安装。这种方法需要您手动下载并设置Easysearch及其依赖。
步骤1:下载并安装Easysearch
首先,手动下载 Easysearch 并将其解压到您希望的安装目录。
步骤2:下载并安装JDK
- 手动下载JDK安装包。
- 将JDK解压到Easysearch安装目录下。
-
将解压出来的JDK目录重命名为jdk。
步骤3:修改Easysearch配置
鉴于Windows默认不包含openssl,生成证书可能较为困难。您可以通过修改config/easysearch.yml文件来绕过证书验证:
security.enabled: false方法三:通过git-for-windows安装
对于喜欢使用命令行的用户,可以通过安装git-for-windows,利用bash环境来执行安装命令。
步骤1:安装Easysearch
通过以下在线脚本命令安装Easysearch:
bashCopy code curl -sSL http://get.infini.cloud | bash -s -- -p easysearch -d /d/opt/easysearch步骤2:下载并安装JDK
-
使用curl命令将JDK下载到指定目录:
bashCopy code curl -# https://release.infinilabs.com/easysearch/jdk/zulu17.42.19-ca-jdk17.0.7-win_x64.zip -o /d/opt/jdk.zip - 解压JDK文件,并将解压后的目录重命名为jdk。
bashCopy code cd /d/opt/easysearch && unzip -q /d/opt/jdk.zip mv zulu* jdk步骤3:设置JAVA_HOME环境变量
配置JAVA_HOME环境变量,以确保Easysearch能正确找到JDK。
bashCopy code export JAVA_HOME=/d/opt/easysearch/jdk步骤4:初始化证书、密码和插件
执行以下命令,初始化所需的配置:
bashCopy code bin/initialize.sh步骤5:运行Easysearch
最后,使用以下命令启动Easysearch:
bashCopy code bin/easysearch.bat通过以上任一方法,您都应该能够成功在Windows系统上安装并运行Easysearch。请选择最适合您的需求和环境的安装方法。 请根据Easysearch和JDK的最新版本,适时更新上述命令和下载链接。接下来,请继续完成验证工作。
验证工作
为了保证Easysearch数据安全,初始化脚本会为admin用户生成随机的密码,如果使用Docker运行Easysearch或执行初始化脚本时同意记录初始密码到日志文件,则可在Docker日志文件或logs/initialize.log中找到admin用户对应的初始化密码。 由于初始脚本会自动覆盖集群上次使用的证书及内置的admin用户密码,请勿多次运行!如果您忘记了初始密码,可以通过内置的证书来进行密码重置。
bashCopy code # 根据初始化脚本生成的随机密码访问 Easysearch 的 REST API curl -ku admin:xxx https://localhost:9200也可以在浏览器中输入网址 https://localhost:9200/,即可验证Easysearch是否完成启动。推荐使用INFINI Console来进行集群管理,功能更加强大和方便。 注:各类客户端及周边工具,如 Logstash、Filebeat 请使用7.10.2 oss版本来连接Easysearch。并打开config/easysearch.yml中的配置项elasticsearch.api_compatibility: true
如果你已经按照上面的步骤完成了安装,那么接下来请尽情的使用Easysearch吧!如果在安装过程中出现了问题的请私聊我!对了,希望在其他环境中部署Easysearch的也可以查询我们的安装指南,上面有详细的安装步骤!祝你好运!
相信最近大家都已经听过Easysearch的名头,成功拿下了墨天轮搜索型数据库的榜首!什么?您不知道?那我再给您介绍下: INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。 相信看完了上面您已经对使用Easysearch有了想法,不要想,行动!我将带领您在windows环境中使用Easysearch,有几种安装方法可供选择!
方法一:使用Docker
对于已在Windows系统上安装了Docker的用户来说,通过Docker安装Easysearch是最直接高效的方法。接下来我将介绍Docker部署Easysearch的方法,如果没有安装Docker请跳过!
Docker 环境下使用 Easysearch
在使用 Docker 运行 Easysearch 之前,请确保已进行系统调优并安装好Docker服务,且Docker服务正常运行。
最快方式:启动临时的docker容器,可以从前台查看到admin的初始密码
```bash
docker run --name easysearch -p 9200:9200 dockerproxy.com/infinilabs/easysearch:latest个性配置
从宿主机挂载数据目录及日志目录,并配置jvm内存为512m。
-
在宿主机上创建目录
bashCopy code sudo mkdir -p /data/easysearch/{data,logs} -
修改目录权限
bashCopy code # 容器内es用户的uid为602,通过调整宿主机的目录权限,确保在容器内部es用户有权限读写挂载的数据卷 sudo chown -R 602.602 /data/easysearch -
后台运行容器
bashCopy code docker run -d --restart always -p 9200:9200 \ -e ES_JAVA_OPTS="-Xms512m -Xmx512m" \ -v /data/easysearch/data:/app/easysearch/data \ -v /data/easysearch/logs:/app/easysearch/logs \ --name easysearch --hostname easysearch \ dockerproxy.com/infinilabs/easysearch:latest -
查看初始密码
bashCopy code # 由于以上容器是后台启动,需要通过日志找出admin的初始密码 docker logs easysearch 2>/dev/null | grep -w Usage容器启停
-
启动容器
bashCopy code docker start easysearch -
停止容器
bashCopy code docker stop easysearch后续验证工作,请继续查看安装指南。
方法二:不使用HTTPS安装Easysearch
在某些情况下,您可能需要或者偏好不通过HTTPS方式进行安装。这种方法需要您手动下载并设置Easysearch及其依赖。
步骤1:下载并安装Easysearch
首先,手动下载 Easysearch 并将其解压到您希望的安装目录。
步骤2:下载并安装JDK
- 手动下载JDK安装包。
- 将JDK解压到Easysearch安装目录下。
-
将解压出来的JDK目录重命名为jdk。
步骤3:修改Easysearch配置
鉴于Windows默认不包含openssl,生成证书可能较为困难。您可以通过修改config/easysearch.yml文件来绕过证书验证:
security.enabled: false方法三:通过git-for-windows安装
对于喜欢使用命令行的用户,可以通过安装git-for-windows,利用bash环境来执行安装命令。
步骤1:安装Easysearch
通过以下在线脚本命令安装Easysearch:
bashCopy code curl -sSL http://get.infini.cloud | bash -s -- -p easysearch -d /d/opt/easysearch步骤2:下载并安装JDK
-
使用curl命令将JDK下载到指定目录:
bashCopy code curl -# https://release.infinilabs.com/easysearch/jdk/zulu17.42.19-ca-jdk17.0.7-win_x64.zip -o /d/opt/jdk.zip - 解压JDK文件,并将解压后的目录重命名为jdk。
bashCopy code cd /d/opt/easysearch && unzip -q /d/opt/jdk.zip mv zulu* jdk步骤3:设置JAVA_HOME环境变量
配置JAVA_HOME环境变量,以确保Easysearch能正确找到JDK。
bashCopy code export JAVA_HOME=/d/opt/easysearch/jdk步骤4:初始化证书、密码和插件
执行以下命令,初始化所需的配置:
bashCopy code bin/initialize.sh步骤5:运行Easysearch
最后,使用以下命令启动Easysearch:
bashCopy code bin/easysearch.bat通过以上任一方法,您都应该能够成功在Windows系统上安装并运行Easysearch。请选择最适合您的需求和环境的安装方法。 请根据Easysearch和JDK的最新版本,适时更新上述命令和下载链接。接下来,请继续完成验证工作。
验证工作
为了保证Easysearch数据安全,初始化脚本会为admin用户生成随机的密码,如果使用Docker运行Easysearch或执行初始化脚本时同意记录初始密码到日志文件,则可在Docker日志文件或logs/initialize.log中找到admin用户对应的初始化密码。 由于初始脚本会自动覆盖集群上次使用的证书及内置的admin用户密码,请勿多次运行!如果您忘记了初始密码,可以通过内置的证书来进行密码重置。
bashCopy code # 根据初始化脚本生成的随机密码访问 Easysearch 的 REST API curl -ku admin:xxx https://localhost:9200也可以在浏览器中输入网址 https://localhost:9200/,即可验证Easysearch是否完成启动。推荐使用INFINI Console来进行集群管理,功能更加强大和方便。 注:各类客户端及周边工具,如 Logstash、Filebeat 请使用7.10.2 oss版本来连接Easysearch。并打开config/easysearch.yml中的配置项elasticsearch.api_compatibility: true
如果你已经按照上面的步骤完成了安装,那么接下来请尽情的使用Easysearch吧!如果在安装过程中出现了问题的请私聊我!对了,希望在其他环境中部署Easysearch的也可以查询我们的安装指南,上面有详细的安装步骤!祝你好运!
收起阅读 »【搜索客社区日报】第1798期 (2024-03-19)
https://medium.com/%40filippor ... 24d3a
2. 用aws lambda搭一个数据写入pipeline吧(需要梯子)
https://medium.com/%40samb333/ ... 7de9a
3. agi动画所用的技术概览
https://diffusionpilot.blogspo ... .html
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40filippor ... 24d3a
2. 用aws lambda搭一个数据写入pipeline吧(需要梯子)
https://medium.com/%40samb333/ ... 7de9a
3. agi动画所用的技术概览
https://diffusionpilot.blogspo ... .html
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】 第1797期 (2024-03-18)
https://mp.weixin.qq.com/s/C7D8AHMzRQUxTjTarftYfw
2 什么时候该使用Elasticsearch?
https://zhuanlan.zhihu.com/p/656780550
3、Elasticsearch SQL查询解析
https://blog.csdn.net/weixin_4 ... 39780
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/C7D8AHMzRQUxTjTarftYfw
2 什么时候该使用Elasticsearch?
https://zhuanlan.zhihu.com/p/656780550
3、Elasticsearch SQL查询解析
https://blog.csdn.net/weixin_4 ... 39780
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn 收起阅读 »
Stable Diffusion 解析:探寻 AI 绘画背后的科技神秘
AI 绘画发展史
在谈论 Stable Diffusion 之前,有必要先了解 AI 绘画的发展历程。
早在 2012 年,华人科学家吴恩达领导的团队训练出了当时世界上最大的深度学习网络。这个网络能够自主学习识别猫等物体,并在短短三天时间内绘制出了一张模糊但可辨识的猫图。尽管这张图片很模糊,但它展示了深度学习在图像识别方面的潜力。

到了 2014 年,加拿大蒙特利尔大学的谷歌科学家 Ian Goodfellow 提出了生成对抗网络 GAN 的算法,这一算法一度成为 AI 生成绘画的主流方向。GAN 的原理是通过训练两个深度神经网络模型——生成器 Generator 和判别器 Discriminator ,使得生成器能够生成与真实数据相似的新数据样本,并且判别器可以准确地区分生成器生成的假样本和真实数据。GAN 的核心思想是博弈,生成器试图欺骗判别器,而判别器则努力辨别真伪,二者相互对抗、相互协作,最终实现高质量的数据生成效果。
2016 年,基于 GAN 的第一个文本到图像模型 GAN-INT-CLS 问世,证明了 GAN 在从文本生成图像方面的可行性,为各类基于 GAN 的有条件图像生成模型的涌现打开了大门。然而,GAN 在训练过程中很容易出现不稳定或崩溃的情况,因此难以大规模应用。
同年 10 月,NVIDIA 提出了 ProgressiveGAN,通过逐渐增加神经网络规模生成高分辨率图像,从而降低了模型训练难度并提高了生成质量,为后来的 StyleGAN 的崛起铺平了道路。
2017 年,谷歌发表了著名论文《Attention Is All You Need》,提出了 Transformer 结构,随后在自然语言处理领域大放异彩;虽然 Transformer 是为了解决自然语言处理问题而设计的,但它在图像生成领域也显示了巨大的潜力。2020 年,他们又提出了 ViT 概念,尝试用 Transformer 结构替代传统的卷积神经网络 CNN 结构在计算机视觉中的应用。
2020 年出现了转折。加州大学伯克利分校提出了众所周知的去噪扩散概率模型 DDPM,简化了原有模型的损失函数,将训练目标转变为预测当前步添加的噪声信息,极大降低了训练难度,并将网络模块由全卷积网络替换为 Unet,提升了模型的表达能力。
2021 年 1 月,OpenAI 发布了基于 VQVAE 模型的 DALL-E 和 CLIP 模型 Contrastive Language-Image Pre-Training,它们分别用于文本到图像生成和文本与图像之间的对比学习。这让 AI 似乎第一次真正“理解”了人类的描述并进行创作,激发了人们前所未有的对 AI 绘画的热情。2021 年 10 月,谷歌发布的 Disco Diffusion 模型以其惊人的图像生成效果拉开了扩散模型的时代序幕。
2022 年 2 月,由一些开源社区的工程师开发的基于扩散模型的 AI 绘图生成器 Disco Diffusion 推出。从那时起,AI 绘画进入了快速发展的轨道,潘多拉魔盒已然打开。Disco Diffusion 相比传统的 AI 模型更加易用,研究人员建立了完善的帮助文档和社群,越来越多的人开始关注它。同年 3 月,由 Disco Diffusion 核心开发人员参与开发的 AI 生成器 MidJourney 正式发布。MidJourney 选择搭载在 Discord 平台,借助聊天式的人机交互方式,使得操作更加简便,而且无需复杂的参数调节,只需向聊天窗口输入文字就可以生成图像。
更重要的是,MidJourney 生成的图片效果非常惊艳,以至于普通人几乎无法分辨出其生成的作品是否是由 AI 绘制的。在 MidJourney 发布 5 个月后,美国科罗拉多州博览会的艺术比赛评选出了结果,一幅名为《太空歌剧院》的画作获得了第一名,然而其并非人类画师的作品,而是由名为 MidJourney 的人工智能创作的。

当参赛者公布这幅作品是由 AI 绘制时,引发了许多人类画家的愤怒和焦虑。
2022 年 4 月 10 日,之前提到的 OpenAI 的 DALL·E 2 发布了。无论是 Disco Diffusion 还是 MidJourney,细心观察后仍然能够看出其是由 AI 生成的,但 DALL·E 2 生成的图像已经无法与人类作品区分开了。
Stable Diffusion
2022 年 7 月 29 日,由 Stability.AI 公司研发的 Stable Diffusion 的 AI 生成器开始内测。人们发现用它生成的 AI 绘画作品质量堪比 DALL·E 2,而且限制更少。Stable Diffusion 的内测共分 4 波,邀请了 15000 名用户参与,仅仅十天后,就有一千七百万张图片通过它生成。最关键的是,Stable Diffusion 的开发公司 Stability AI 秉承着开源的理念,“AI by the people,for the people”,这意味着任何人都可以在本地部署自己的 AI 绘画生成器,真正实现了每个人“只要你会说话,就能够创造出一幅画”。开源社区 HuggingFace 迅速适配了它,使得个人部署变得更加简单;而开源工具 Stable-diffusion-webui 则将多种图像生成工具集成在一起,甚至可以在网络端微调模型、训练个人专属模型,备受好评,在 GitHub 上获得了 3.4 万颗星,使得扩散生成模型彻底走出了大型服务,向个人部署迈进。
2022 年 11 月,Stable Diffusion 2.0 发布,新版本生成的分辨率提高了四倍,生成速度也更快。
Stable Diffusion 基于 Latent Diffusion Models,将最耗时的扩散过程放在低维度的潜变量空间,大大降低了算力需求以及个人部署门槛。它使用的潜空间编码缩减因子为 8,换句话说,图像的长和宽被缩减为原来的八分之一,例如一个 512512 的图像在潜空间中直接变为 6464,从而节省了 64 倍的内存!在此基础上,Stable Diffusion 还降低了性能要求。不仅可以快速(以秒计算)生成一张细节丰富的 512512 图像,而且只需一张英伟达消费级的 8GB 2060 显卡。如果没有这个空间压缩转换,它将需要一张 512GB 显存的超级显卡。按照显卡硬件的发展规律,消费者至少需要 8-10 年的时间才能享受到这类应用。这个算法上的重要迭代使得 AI 作画提前进入了每个人的生活。
在本文中,我们探讨了 Stable Diffusion 的发展历程以及对其的介绍。如果你同样是 AI 绘画的爱好者,欢迎和我一起交流探讨。未来,我将持续更新这个系列,分享 Stable Diffusion 的教程以及其他 AI 绘画软件的教学内容。如果您喜欢这些内容,欢迎关注我们!感谢您的阅读,期待在下一期再与您相见!

AI 绘画发展史
在谈论 Stable Diffusion 之前,有必要先了解 AI 绘画的发展历程。
早在 2012 年,华人科学家吴恩达领导的团队训练出了当时世界上最大的深度学习网络。这个网络能够自主学习识别猫等物体,并在短短三天时间内绘制出了一张模糊但可辨识的猫图。尽管这张图片很模糊,但它展示了深度学习在图像识别方面的潜力。
到了 2014 年,加拿大蒙特利尔大学的谷歌科学家 Ian Goodfellow 提出了生成对抗网络 GAN 的算法,这一算法一度成为 AI 生成绘画的主流方向。GAN 的原理是通过训练两个深度神经网络模型——生成器 Generator 和判别器 Discriminator ,使得生成器能够生成与真实数据相似的新数据样本,并且判别器可以准确地区分生成器生成的假样本和真实数据。GAN 的核心思想是博弈,生成器试图欺骗判别器,而判别器则努力辨别真伪,二者相互对抗、相互协作,最终实现高质量的数据生成效果。
2016 年,基于 GAN 的第一个文本到图像模型 GAN-INT-CLS 问世,证明了 GAN 在从文本生成图像方面的可行性,为各类基于 GAN 的有条件图像生成模型的涌现打开了大门。然而,GAN 在训练过程中很容易出现不稳定或崩溃的情况,因此难以大规模应用。
同年 10 月,NVIDIA 提出了 ProgressiveGAN,通过逐渐增加神经网络规模生成高分辨率图像,从而降低了模型训练难度并提高了生成质量,为后来的 StyleGAN 的崛起铺平了道路。
2017 年,谷歌发表了著名论文《Attention Is All You Need》,提出了 Transformer 结构,随后在自然语言处理领域大放异彩;虽然 Transformer 是为了解决自然语言处理问题而设计的,但它在图像生成领域也显示了巨大的潜力。2020 年,他们又提出了 ViT 概念,尝试用 Transformer 结构替代传统的卷积神经网络 CNN 结构在计算机视觉中的应用。
2020 年出现了转折。加州大学伯克利分校提出了众所周知的去噪扩散概率模型 DDPM,简化了原有模型的损失函数,将训练目标转变为预测当前步添加的噪声信息,极大降低了训练难度,并将网络模块由全卷积网络替换为 Unet,提升了模型的表达能力。
2021 年 1 月,OpenAI 发布了基于 VQVAE 模型的 DALL-E 和 CLIP 模型 Contrastive Language-Image Pre-Training,它们分别用于文本到图像生成和文本与图像之间的对比学习。这让 AI 似乎第一次真正“理解”了人类的描述并进行创作,激发了人们前所未有的对 AI 绘画的热情。2021 年 10 月,谷歌发布的 Disco Diffusion 模型以其惊人的图像生成效果拉开了扩散模型的时代序幕。
2022 年 2 月,由一些开源社区的工程师开发的基于扩散模型的 AI 绘图生成器 Disco Diffusion 推出。从那时起,AI 绘画进入了快速发展的轨道,潘多拉魔盒已然打开。Disco Diffusion 相比传统的 AI 模型更加易用,研究人员建立了完善的帮助文档和社群,越来越多的人开始关注它。同年 3 月,由 Disco Diffusion 核心开发人员参与开发的 AI 生成器 MidJourney 正式发布。MidJourney 选择搭载在 Discord 平台,借助聊天式的人机交互方式,使得操作更加简便,而且无需复杂的参数调节,只需向聊天窗口输入文字就可以生成图像。
更重要的是,MidJourney 生成的图片效果非常惊艳,以至于普通人几乎无法分辨出其生成的作品是否是由 AI 绘制的。在 MidJourney 发布 5 个月后,美国科罗拉多州博览会的艺术比赛评选出了结果,一幅名为《太空歌剧院》的画作获得了第一名,然而其并非人类画师的作品,而是由名为 MidJourney 的人工智能创作的。
当参赛者公布这幅作品是由 AI 绘制时,引发了许多人类画家的愤怒和焦虑。
2022 年 4 月 10 日,之前提到的 OpenAI 的 DALL·E 2 发布了。无论是 Disco Diffusion 还是 MidJourney,细心观察后仍然能够看出其是由 AI 生成的,但 DALL·E 2 生成的图像已经无法与人类作品区分开了。
Stable Diffusion
2022 年 7 月 29 日,由 Stability.AI 公司研发的 Stable Diffusion 的 AI 生成器开始内测。人们发现用它生成的 AI 绘画作品质量堪比 DALL·E 2,而且限制更少。Stable Diffusion 的内测共分 4 波,邀请了 15000 名用户参与,仅仅十天后,就有一千七百万张图片通过它生成。最关键的是,Stable Diffusion 的开发公司 Stability AI 秉承着开源的理念,“AI by the people,for the people”,这意味着任何人都可以在本地部署自己的 AI 绘画生成器,真正实现了每个人“只要你会说话,就能够创造出一幅画”。开源社区 HuggingFace 迅速适配了它,使得个人部署变得更加简单;而开源工具 Stable-diffusion-webui 则将多种图像生成工具集成在一起,甚至可以在网络端微调模型、训练个人专属模型,备受好评,在 GitHub 上获得了 3.4 万颗星,使得扩散生成模型彻底走出了大型服务,向个人部署迈进。
2022 年 11 月,Stable Diffusion 2.0 发布,新版本生成的分辨率提高了四倍,生成速度也更快。
Stable Diffusion 基于 Latent Diffusion Models,将最耗时的扩散过程放在低维度的潜变量空间,大大降低了算力需求以及个人部署门槛。它使用的潜空间编码缩减因子为 8,换句话说,图像的长和宽被缩减为原来的八分之一,例如一个 512512 的图像在潜空间中直接变为 6464,从而节省了 64 倍的内存!在此基础上,Stable Diffusion 还降低了性能要求。不仅可以快速(以秒计算)生成一张细节丰富的 512512 图像,而且只需一张英伟达消费级的 8GB 2060 显卡。如果没有这个空间压缩转换,它将需要一张 512GB 显存的超级显卡。按照显卡硬件的发展规律,消费者至少需要 8-10 年的时间才能享受到这类应用。这个算法上的重要迭代使得 AI 作画提前进入了每个人的生活。
在本文中,我们探讨了 Stable Diffusion 的发展历程以及对其的介绍。如果你同样是 AI 绘画的爱好者,欢迎和我一起交流探讨。未来,我将持续更新这个系列,分享 Stable Diffusion 的教程以及其他 AI 绘画软件的教学内容。如果您喜欢这些内容,欢迎关注我们!感谢您的阅读,期待在下一期再与您相见!
Elasticsearch 国产化
背景
Elasticsearch 这些年来在搜索领域一直是领头羊。国内也有非常多的企业在使用 Elasticsearch 来做查询搜索、数据分析、安全分析等等。甚至一些很重要的行业、系统都在使用 Elasticsearch。在使用 Elasticsearch 的道路上狂飙的时候,我们也观察到了一些问题:
- Elasticsearch 不再是开源软件了。
- Elastic 公司退出了中国直销市场,不提供本土化支持了。
- 国家对信创、自主可控的战略化布局。
- 国际形势从合作共赢到自闭对垒。
- Elasticsearch 软件本身安全问题频发。
- Elasticsearch 软件在性能、稳定性和扩展性方面存在很大的提升空间。
基于以上这些问题,推出一个 Elasticsearch 国产化解决方案就很有必要了。我们的解决方案是推出一款名为 Easysearch 的软件,作为 Elasticsearch 国产化替代 。
出发点是在兼容原 Elasticsearch 软件的基础之上,完善更多的企业级功能,同时提高产品的性能、稳定性和扩展性。
下面我将从几个方面简单介绍下 Easysearch 软件。
兼容性
支持原生 Elasticsearch 的 DSL 查询语法,原业务代码无需调整。 支持 SQL ,方便熟悉 SQL 的开发人员上手分析数据。 兼容 Elasticsearch 的 SDK。 兼容现有索引存储格式。 支持冷热架构和索引生命周期,真正做到无缝衔接。
功能增强
提供企业级的安全管理,可对接 LDAP、AD 认证。 重构分布式架构,保持稳定的同时,能支持更大规模的数据。 在不降低性能的同时,实现更高压缩比的数据压缩,直接节省磁盘 40% 以上。 支持 KNN、异步搜索、数据脱敏、可搜索快照、审计等企业级功能。
容灾
支持基于 CDC 的集群复制技术,实现同版本间的容灾。
支持基于请求双写的复制技术,实现跨版本容灾。
信创
全面适配国产 CPU、操作系统,并获得厂家认证。

迁移方案
支持原索引存储格式,可通过快照备份直接恢复到 Easysearch 集群。
提供迁移工具,直接可视化操作迁移数据。
简单的介绍就到这里了,更多信息请访问:https://www.infinilabs.com/products/easysearch
最后
如有需要请联系我,让我们一起位祖国的信创事业添砖加瓦。

背景
Elasticsearch 这些年来在搜索领域一直是领头羊。国内也有非常多的企业在使用 Elasticsearch 来做查询搜索、数据分析、安全分析等等。甚至一些很重要的行业、系统都在使用 Elasticsearch。在使用 Elasticsearch 的道路上狂飙的时候,我们也观察到了一些问题:
- Elasticsearch 不再是开源软件了。
- Elastic 公司退出了中国直销市场,不提供本土化支持了。
- 国家对信创、自主可控的战略化布局。
- 国际形势从合作共赢到自闭对垒。
- Elasticsearch 软件本身安全问题频发。
- Elasticsearch 软件在性能、稳定性和扩展性方面存在很大的提升空间。
基于以上这些问题,推出一个 Elasticsearch 国产化解决方案就很有必要了。我们的解决方案是推出一款名为 Easysearch 的软件,作为 Elasticsearch 国产化替代 。
出发点是在兼容原 Elasticsearch 软件的基础之上,完善更多的企业级功能,同时提高产品的性能、稳定性和扩展性。
下面我将从几个方面简单介绍下 Easysearch 软件。
兼容性
支持原生 Elasticsearch 的 DSL 查询语法,原业务代码无需调整。 支持 SQL ,方便熟悉 SQL 的开发人员上手分析数据。 兼容 Elasticsearch 的 SDK。 兼容现有索引存储格式。 支持冷热架构和索引生命周期,真正做到无缝衔接。
功能增强
提供企业级的安全管理,可对接 LDAP、AD 认证。 重构分布式架构,保持稳定的同时,能支持更大规模的数据。 在不降低性能的同时,实现更高压缩比的数据压缩,直接节省磁盘 40% 以上。 支持 KNN、异步搜索、数据脱敏、可搜索快照、审计等企业级功能。
容灾
支持基于 CDC 的集群复制技术,实现同版本间的容灾。
支持基于请求双写的复制技术,实现跨版本容灾。
信创
全面适配国产 CPU、操作系统,并获得厂家认证。
迁移方案
支持原索引存储格式,可通过快照备份直接恢复到 Easysearch 集群。
提供迁移工具,直接可视化操作迁移数据。
简单的介绍就到这里了,更多信息请访问:https://www.infinilabs.com/products/easysearch
最后
如有需要请联系我,让我们一起位祖国的信创事业添砖加瓦。
OpenSearch 与 Elasticsearch:哪个开源搜索引擎适合您?
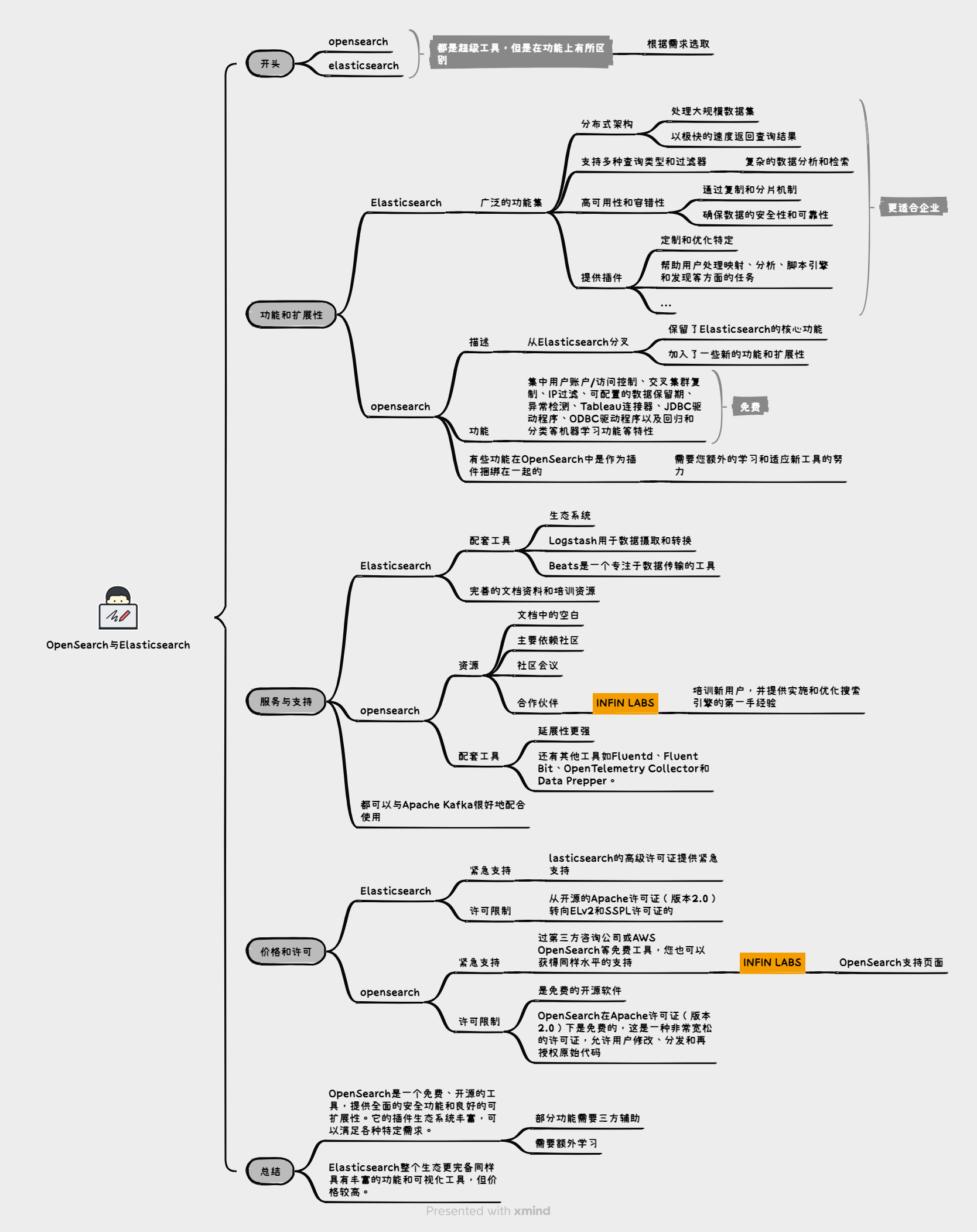
当谈论到搜索引擎产品时,Elasticsearch 和 OpenSearch 是两个备受关注的选择。它们都以其出色的功能和灵活性而闻名,但在一些方面存在一些差异。在本文中,我们将从功能和延展性、工具与资源、价格和许可这三个角度对这两个产品进行论述。通过深入研究它们的特点和优势,您将能够更好地了解它们,从而为您的搜索需求做出明智的选择。让我们开始探索 Elasticsearch 和 OpenSearch 的世界,以便您能够为自己的项目或业务找到最佳的搜索解决方案。
功能和延展性
Elasticsearch 是一个功能强大的搜索引擎,它支持全文搜索、实时数据分析、数据聚合和可视化等功能。
- 分布式架构:它使用分布式架构,可以处理大规模数据集,并以快速的速度返回查询结果。
- 多种查询类型和过滤器:提供多种查询类型和过滤器,使用户能够进行复杂的数据分析和检索。
- 高可用性和容错性:提供高可用性和容错性,通过复制和分片机制来确保数据的安全性和可靠性。
- 强大的插件生态系统:帮助用户处理映射、分析、脚本引擎和发现等任务。通过使用这些插件,用户可以根据其特定的数据处理和分析需求进行功能扩展和定制。
OpenSearch 是从 Elasticsearch 分叉出来的版本,因此在许多方面与 Elasticsearch 相似。它保留了 Elasticsearch 的核心功能,并加入了一些新的功能和扩展性。下面主要讨论一些差异点:
- 开源性和社区参与:OpenSearch 更注重开源性和社区参与,鼓励用户共同开发和改进系统。
- 功能差异:OpenSearch 提供了一些额外的免费功能,如集中用户账户/访问控制、交叉集群复制、IP 过滤、可配置的数据保留期、异常检测、Tableau 连接器、JDBC 驱动程序、ODBC 驱动程序以及回归和分类等机器学习功能。
- 插件生态系统差异:OpenSearch 中的某些功能作为插件捆绑在一起,需要用户额外学习和适应新工具。
服务与支持
Elasticsearch 拥有丰富的工具和资源,使用户能够更好地使用和管理搜索引擎。
- 配套工具:丰富的生态系统,Logstash 用于数据摄取和转换,可以帮助用户为非结构化数据添加结构,进行字段匿名处理,并解析 IP 地址以获取位置信息。Beats 是一个专注于数据传输的工具,可以将数据从数千台机器发送到 Logstash 或 Elasticsearch。
-
完善的文档资料和培训资源:
a. 官方网站提供了产品指南、教程视频、博客文章、讨论论坛等丰富的学习材料。
b. Elastic 还提供了 Slack 频道、YouTube 频道、以及定期举办的在线研讨会和培训活动,为用户提供即时的答疑和学习机会。
c. 广泛的支持服务,包括社区支持、商业支持和培训服务。
OpenSearch 配套工具延展性更好,但是在学习资料和用户培训方面存在大部分空白,目前的服务与支持模式主要依赖于社区。
-
配套工具:除去支持 Logstash 和 Beats 外,还有其他工具如 Fluentd、Fluent Bit、OpenTelemetry Collector 和 Data Prepper,来支持数据处理和传输。
-
文档资料和培训资源:
a. 文档资源:积极填补文档中的空白,并且每月举行两次社区会议,鼓励用户通过 GitHub 提交拉取请求、报告问题和提供反馈。
b. 合作伙伴:提供 OpenSearch 的咨询支持和托管服务,其中就包括 INFINI Labs 在内,通过这些合作伙伴,用户可以获取与 OpenSearch 相关的专业服务和咨询,以满足其特定需求。
OpenSearch 的学习资源和培训材料相对较少,相比之下,Elasticsearch 的学习资料更加丰富和全面。然而,OpenSearch 社区积极发展中,未来可能会有更多的学习资源和支持服务可用。
价格和许可
Elasticsearch 和 OpenSearch 在价格和许可方面也存在差异。本文将从紧急支持和许可限制两个角度进行分析。
Elasticsearch:
- 紧急支持:Elasticsearch 的高级许可证提供紧急支持,这意味着当出现集群崩溃、数据丢失或安全漏洞等问题时,公司能够提供即时的支持。
- 许可限制:Elasticsearch 提供基于订阅模型的商业许可,其中包括从免费的基本许可到高级许可的多个层次。高级许可提供了额外的功能和支持,适合对性能和功能有更高要求的企业。
Opensearch:
- 紧急支持:当前可以通过过第三方咨询公司或 AWS OpenSearch 等免费工具获得同样水平的支持,OpenSearch 有一个合作伙伴页面,列出了许多咨询公司,包括 INFINI Labs 的 OpenSearch 支持页面,他们提供 24 x 7 的支持。
- 许可限制:OpenSearch 是基于 Apache 2.0 许可的开源软件,允许用户自由使用、修改和分发。它提供了免费的功能和灵活的定制,使用户能够根据自己的需求进行自定义和扩展。
总结
Elasticsearch 和 OpenSearch 都是强大而灵活的搜索引擎产品,但是存在一些差异。
总体来说,Elasticsearch 是一个成熟、功能强大的搜索引擎,拥有广泛的插件生态系统和丰富的学习资源。商业版本提供额外的功能和支持服务,适合需要高级功能和专业支持的企业。
OpenSearch 是从 Elasticsearch 分叉出来的版本,保留了核心功能,并添加了一些额外的功能。它更注重开源性和社区参与,适合更倾向于自主开发和定制的用户。
作者的话
希望这些信息能为您提供有价值的帮助,并使您更好地了解 Elasticsearch 和 OpenSearch。无论您选择哪个搜索引擎,都希望它能满足您的需求并取得成功。
当谈论到搜索引擎产品时,Elasticsearch 和 OpenSearch 是两个备受关注的选择。它们都以其出色的功能和灵活性而闻名,但在一些方面存在一些差异。在本文中,我们将从功能和延展性、工具与资源、价格和许可这三个角度对这两个产品进行论述。通过深入研究它们的特点和优势,您将能够更好地了解它们,从而为您的搜索需求做出明智的选择。让我们开始探索 Elasticsearch 和 OpenSearch 的世界,以便您能够为自己的项目或业务找到最佳的搜索解决方案。
功能和延展性
Elasticsearch 是一个功能强大的搜索引擎,它支持全文搜索、实时数据分析、数据聚合和可视化等功能。
- 分布式架构:它使用分布式架构,可以处理大规模数据集,并以快速的速度返回查询结果。
- 多种查询类型和过滤器:提供多种查询类型和过滤器,使用户能够进行复杂的数据分析和检索。
- 高可用性和容错性:提供高可用性和容错性,通过复制和分片机制来确保数据的安全性和可靠性。
- 强大的插件生态系统:帮助用户处理映射、分析、脚本引擎和发现等任务。通过使用这些插件,用户可以根据其特定的数据处理和分析需求进行功能扩展和定制。
OpenSearch 是从 Elasticsearch 分叉出来的版本,因此在许多方面与 Elasticsearch 相似。它保留了 Elasticsearch 的核心功能,并加入了一些新的功能和扩展性。下面主要讨论一些差异点:
- 开源性和社区参与:OpenSearch 更注重开源性和社区参与,鼓励用户共同开发和改进系统。
- 功能差异:OpenSearch 提供了一些额外的免费功能,如集中用户账户/访问控制、交叉集群复制、IP 过滤、可配置的数据保留期、异常检测、Tableau 连接器、JDBC 驱动程序、ODBC 驱动程序以及回归和分类等机器学习功能。
- 插件生态系统差异:OpenSearch 中的某些功能作为插件捆绑在一起,需要用户额外学习和适应新工具。
服务与支持
Elasticsearch 拥有丰富的工具和资源,使用户能够更好地使用和管理搜索引擎。
- 配套工具:丰富的生态系统,Logstash 用于数据摄取和转换,可以帮助用户为非结构化数据添加结构,进行字段匿名处理,并解析 IP 地址以获取位置信息。Beats 是一个专注于数据传输的工具,可以将数据从数千台机器发送到 Logstash 或 Elasticsearch。
-
完善的文档资料和培训资源:
a. 官方网站提供了产品指南、教程视频、博客文章、讨论论坛等丰富的学习材料。
b. Elastic 还提供了 Slack 频道、YouTube 频道、以及定期举办的在线研讨会和培训活动,为用户提供即时的答疑和学习机会。
c. 广泛的支持服务,包括社区支持、商业支持和培训服务。
OpenSearch 配套工具延展性更好,但是在学习资料和用户培训方面存在大部分空白,目前的服务与支持模式主要依赖于社区。
-
配套工具:除去支持 Logstash 和 Beats 外,还有其他工具如 Fluentd、Fluent Bit、OpenTelemetry Collector 和 Data Prepper,来支持数据处理和传输。
-
文档资料和培训资源:
a. 文档资源:积极填补文档中的空白,并且每月举行两次社区会议,鼓励用户通过 GitHub 提交拉取请求、报告问题和提供反馈。
b. 合作伙伴:提供 OpenSearch 的咨询支持和托管服务,其中就包括 INFINI Labs 在内,通过这些合作伙伴,用户可以获取与 OpenSearch 相关的专业服务和咨询,以满足其特定需求。
OpenSearch 的学习资源和培训材料相对较少,相比之下,Elasticsearch 的学习资料更加丰富和全面。然而,OpenSearch 社区积极发展中,未来可能会有更多的学习资源和支持服务可用。
价格和许可
Elasticsearch 和 OpenSearch 在价格和许可方面也存在差异。本文将从紧急支持和许可限制两个角度进行分析。
Elasticsearch:
- 紧急支持:Elasticsearch 的高级许可证提供紧急支持,这意味着当出现集群崩溃、数据丢失或安全漏洞等问题时,公司能够提供即时的支持。
- 许可限制:Elasticsearch 提供基于订阅模型的商业许可,其中包括从免费的基本许可到高级许可的多个层次。高级许可提供了额外的功能和支持,适合对性能和功能有更高要求的企业。
Opensearch:
- 紧急支持:当前可以通过过第三方咨询公司或 AWS OpenSearch 等免费工具获得同样水平的支持,OpenSearch 有一个合作伙伴页面,列出了许多咨询公司,包括 INFINI Labs 的 OpenSearch 支持页面,他们提供 24 x 7 的支持。
- 许可限制:OpenSearch 是基于 Apache 2.0 许可的开源软件,允许用户自由使用、修改和分发。它提供了免费的功能和灵活的定制,使用户能够根据自己的需求进行自定义和扩展。
总结
Elasticsearch 和 OpenSearch 都是强大而灵活的搜索引擎产品,但是存在一些差异。
总体来说,Elasticsearch 是一个成熟、功能强大的搜索引擎,拥有广泛的插件生态系统和丰富的学习资源。商业版本提供额外的功能和支持服务,适合需要高级功能和专业支持的企业。
OpenSearch 是从 Elasticsearch 分叉出来的版本,保留了核心功能,并添加了一些额外的功能。它更注重开源性和社区参与,适合更倾向于自主开发和定制的用户。
作者的话
希望这些信息能为您提供有价值的帮助,并使您更好地了解 Elasticsearch 和 OpenSearch。无论您选择哪个搜索引擎,都希望它能满足您的需求并取得成功。
收起阅读 »【搜索客社区日报】第1795期 (2024-03-12)
https://medium.com/%40Frauenho ... ab062
2. 一个大佬的博客,里面有不少技术干货
https://plantegg.github.io/
3. 在线古籍收录网站
https://www.shidianguji.com/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40Frauenho ... ab062
2. 一个大佬的博客,里面有不少技术干货
https://plantegg.github.io/
3. 在线古籍收录网站
https://www.shidianguji.com/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
Easysearch 内核完善之 OOM 内存溢出优化案例一则

最近某客户在使用 Easysearch 做聚合时,报出 OOM 导致掉节点的问题,当时直接让客户试着调整 indices.breaker.request.limit ,但是不起作用,于是又看了下 Easysearch 在断路器相关的代码,并自己测试了下。
断路器的种类和作用
Easysearch 内部有个 Circuit breaker 机制,目的是防止各种请求的负载过大导致 OutOfMemoryError,比较常用的断路器有 7 种,分别是:
- Parent circuit breaker 父断路器
- Field data circuit breaker fielddata 断路器
- Request circuit breaker 请求断路器
- In flight requests circuit breaker 传输请求断路器
- Accounting requests circuit breaker lucene 内存占用断路器
- Script compilation circuit breaker 脚本编译断路器
- Regex circuit breaker 正则表达式断路器
其中在执行消耗内存较多的聚合查询时,Request circuit breaker 用得最多。
复现测试
我在模拟客户场景测试聚合查询时,发现断路器并没有覆盖查询的整个流程,仍然会有 OOM 的风险。我测试了一个高基数 5 百万的 Terms aggregation,就没有触发断路,而是在等待了 1 分多钟后直接 OOM 了。我的测试环境是单节点 内存配置为 -Xmx1g,测试索引只有 1 个 shard。
测试语句如下:
curl -X GET "localhost:9211/leader-01/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size": 1,
"aggs": {
"a": {
"terms": { "field": "agent.id.keyword", "size": 5000000 }
}
}
}' > a.txtEasysearch OOM 日志:
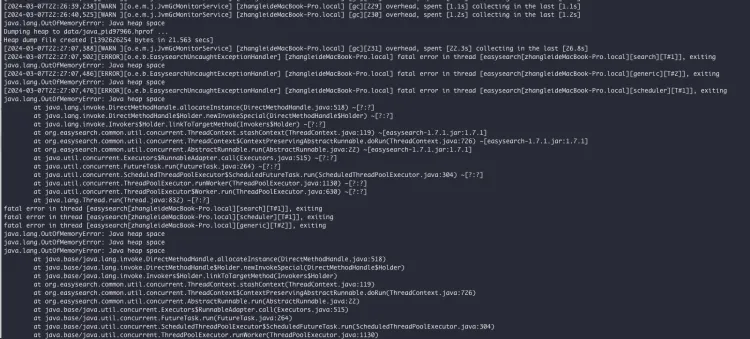
内存泄漏分析
使用 MemoryAnalyzer 分析生成的 jvm 堆转储文件:
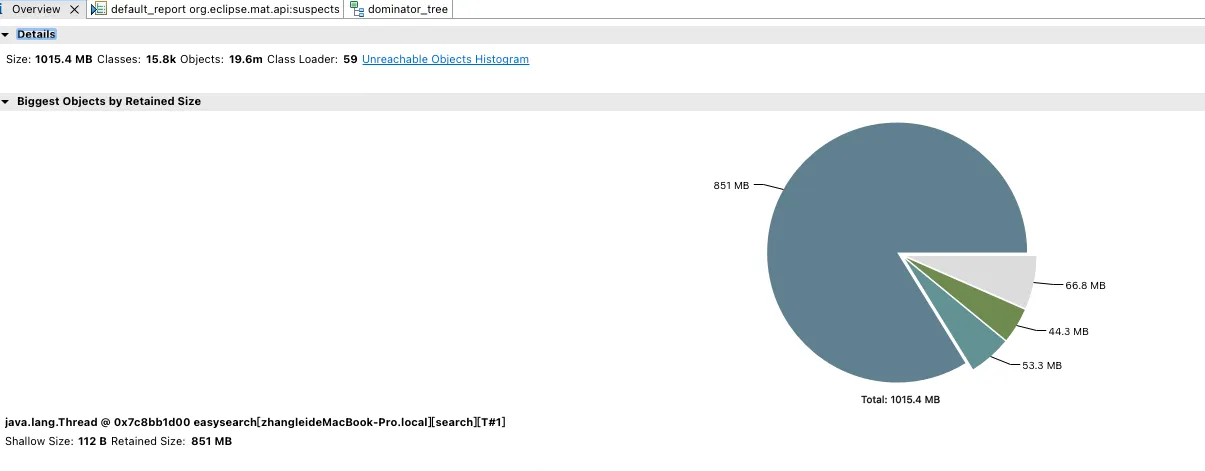
最大的内存占用来自 Java 线程java.lang.Thread @ 0x7c8bb1d00。这个线程浅层(Shallow)保留的对象占用了 112.8MB 内存。但该线程实际保留(Retained)的对象内存占用高达 851 MB,成为整个内存占用的绝对大头。
进一步查看 Leak Suspects:
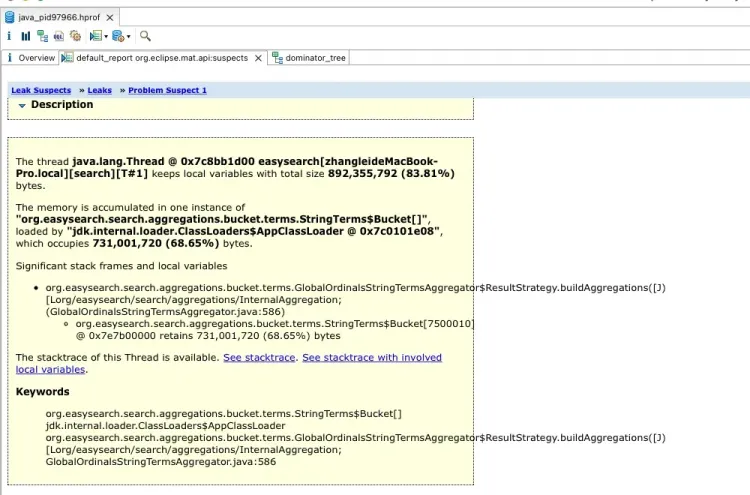
非常明确的给出了具体的内存泄露的对象:StringTerms$Bucket[7500010]
数组长度达到了七百五十万,占用内存:731,001,720 字节(占总内存的 68.65%)。
按照提示的GlobalOrdinalsStringTermsAggregator.java:586 行,去查看代码,实际上是将收集完的OrdBucket 转换为 StringTerms.Bucket,并且有一个 copy BytesRef的操作。
至此,原因和解决办法都清楚了,只要在转换之前预估一下将要增长的内存并调用断路器检测一下内存,一旦超出允许范围就快速触发 CircuitBreakingException,避免长时间等待后 OOM 引起的节点宕机了。
最新版 Elasticsearch 对比
作为对比,我又测试了下 Elasticsearch 最新版本 8.12.2,同样的测试环境和测试方法,结果依然是 OOM:

从这里可以看出 Elasticsearch 即使是最新版的断路器机制也还有很多改进的余地,比如增加对有 OOM 风险查询的覆盖率,还有就是在触发 GC 时,对 GC 堆内存回收的判断过于简单。
Easysearch 最新版本的改进
Easysearch 刚刚发布的 1.7.1 版本已经增加了上面的改进,后面也会持续改进查询聚合操作的内存控制,最新版本的跨集群复制(CCR)也增加了对 source_reuse 索引的支持,能更好的满足客户降本增效的需求,欢迎大家下载试用。
附官网下载链接:https://www.infinilabs.com/download/?product=easysearch
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
最近某客户在使用 Easysearch 做聚合时,报出 OOM 导致掉节点的问题,当时直接让客户试着调整 indices.breaker.request.limit ,但是不起作用,于是又看了下 Easysearch 在断路器相关的代码,并自己测试了下。
断路器的种类和作用
Easysearch 内部有个 Circuit breaker 机制,目的是防止各种请求的负载过大导致 OutOfMemoryError,比较常用的断路器有 7 种,分别是:
- Parent circuit breaker 父断路器
- Field data circuit breaker fielddata 断路器
- Request circuit breaker 请求断路器
- In flight requests circuit breaker 传输请求断路器
- Accounting requests circuit breaker lucene 内存占用断路器
- Script compilation circuit breaker 脚本编译断路器
- Regex circuit breaker 正则表达式断路器
其中在执行消耗内存较多的聚合查询时,Request circuit breaker 用得最多。
复现测试
我在模拟客户场景测试聚合查询时,发现断路器并没有覆盖查询的整个流程,仍然会有 OOM 的风险。我测试了一个高基数 5 百万的 Terms aggregation,就没有触发断路,而是在等待了 1 分多钟后直接 OOM 了。我的测试环境是单节点 内存配置为 -Xmx1g,测试索引只有 1 个 shard。
测试语句如下:
curl -X GET "localhost:9211/leader-01/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size": 1,
"aggs": {
"a": {
"terms": { "field": "agent.id.keyword", "size": 5000000 }
}
}
}' > a.txtEasysearch OOM 日志:
内存泄漏分析
使用 MemoryAnalyzer 分析生成的 jvm 堆转储文件:
最大的内存占用来自 Java 线程java.lang.Thread @ 0x7c8bb1d00。这个线程浅层(Shallow)保留的对象占用了 112.8MB 内存。但该线程实际保留(Retained)的对象内存占用高达 851 MB,成为整个内存占用的绝对大头。
进一步查看 Leak Suspects:
非常明确的给出了具体的内存泄露的对象:StringTerms$Bucket[7500010]
数组长度达到了七百五十万,占用内存:731,001,720 字节(占总内存的 68.65%)。
按照提示的GlobalOrdinalsStringTermsAggregator.java:586 行,去查看代码,实际上是将收集完的OrdBucket 转换为 StringTerms.Bucket,并且有一个 copy BytesRef的操作。
至此,原因和解决办法都清楚了,只要在转换之前预估一下将要增长的内存并调用断路器检测一下内存,一旦超出允许范围就快速触发 CircuitBreakingException,避免长时间等待后 OOM 引起的节点宕机了。
最新版 Elasticsearch 对比
作为对比,我又测试了下 Elasticsearch 最新版本 8.12.2,同样的测试环境和测试方法,结果依然是 OOM:
从这里可以看出 Elasticsearch 即使是最新版的断路器机制也还有很多改进的余地,比如增加对有 OOM 风险查询的覆盖率,还有就是在触发 GC 时,对 GC 堆内存回收的判断过于简单。
Easysearch 最新版本的改进
Easysearch 刚刚发布的 1.7.1 版本已经增加了上面的改进,后面也会持续改进查询聚合操作的内存控制,最新版本的跨集群复制(CCR)也增加了对 source_reuse 索引的支持,能更好的满足客户降本增效的需求,欢迎大家下载试用。
附官网下载链接:https://www.infinilabs.com/download/?product=easysearch
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
收起阅读 »

