

【搜索客社区日报】第1953期 (2024-12-17)
1. 我们在zendesk是怎么做语义检索的(需要梯子)
https://zendesk.engineering/se ... aa7d3
2. 构建一个简单的“或许你想找”?(需要梯子)
https://medium.com/%40andre.lu ... 0a1b5
3. 官方ES+kibana 视频教程(需要梯子)
https://www.youtube.com/watch% ... MMBta
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 我们在zendesk是怎么做语义检索的(需要梯子)
https://zendesk.engineering/se ... aa7d3
2. 构建一个简单的“或许你想找”?(需要梯子)
https://medium.com/%40andre.lu ... 0a1b5
3. 官方ES+kibana 视频教程(需要梯子)
https://www.youtube.com/watch% ... MMBta
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
《ClickHouse:强大的数据分析引擎》
列式存储
列式存储是一种数据存储结构,也称为列存储或列式数据库。它将数据按列存储而非传统的按行存储。每一列的数据类型相同或者相似。
采用行式存储时,数据在磁盘上的组织结构为:
采用列式存储时,数据在磁盘上的组织结构为:
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
ClickHouse 的主要特点
高性能
快速的查询响应:能够在秒级甚至亚秒级时间内处理大规模数据的查询请求。
高效的数据压缩:采用了多种数据压缩算法,大大减少了数据存储占用的空间,同时提高了数据读取的速度。
向量化执行引擎:可以并行处理大量数据,充分利用现代硬件的优势,提高执行效率。
可扩展性
分布式架构:支持水平扩展,可以轻松地添加更多的服务器节点来处理不断增长的数据量和查询负载。
数据分片:将数据分散存储在不同的节点上,提高数据的可用性和可靠性。
丰富的数据分析功能
支持多种数据类型:包括数值、字符串、日期时间等常见数据类型,以及数组、嵌套结构等复杂数据类型。
强大的聚合函数:提供了丰富的聚合函数,如求和、平均值、最大值、最小值等,方便进行数据分析和统计。
支持 SQL 语言:用户可以使用熟悉的 SQL 语句进行数据查询和分析,降低了学习成本。
场景支持
ClickHouse的数据处理速度非常快,尤其适合于包含复杂分析查询的场景
适合场景
日志和事件数据:由于ClickHouse的处理速度,它可以作为实时数据分析的工具。
监控和报警系统:ClickHouse可以用于快速查询和显示监控数据。
交互式查询:由于其快速的查询速度,ClickHouse可以作为数据科学家进行交互式探索的工具。
数据仓库:ClickHouse可以作为数据仓库的一种替代方法,用于快速查询和分析。
不适合场景
事务处理:ClickHouse不支持事务处理。
强一致性:ClickHouse不保证数据的强一致性。
低延迟的更新:ClickHouse不适合于需要实时或近实时更新数据的场景。
高度模式化的数据:ClickHouse对模式的灵活性不如关系型数据库。
小结
总之,ClickHouse 是一款功能强大的数据库管理系统,适用于大规模数据分析和处理场景。通过了解其特点和基础知识,用户可以更好地利用 ClickHouse 来满足自己的数据分析需求
列式存储
列式存储是一种数据存储结构,也称为列存储或列式数据库。它将数据按列存储而非传统的按行存储。每一列的数据类型相同或者相似。
采用行式存储时,数据在磁盘上的组织结构为:
采用列式存储时,数据在磁盘上的组织结构为:
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
ClickHouse 的主要特点
高性能
快速的查询响应:能够在秒级甚至亚秒级时间内处理大规模数据的查询请求。
高效的数据压缩:采用了多种数据压缩算法,大大减少了数据存储占用的空间,同时提高了数据读取的速度。
向量化执行引擎:可以并行处理大量数据,充分利用现代硬件的优势,提高执行效率。
可扩展性
分布式架构:支持水平扩展,可以轻松地添加更多的服务器节点来处理不断增长的数据量和查询负载。
数据分片:将数据分散存储在不同的节点上,提高数据的可用性和可靠性。
丰富的数据分析功能
支持多种数据类型:包括数值、字符串、日期时间等常见数据类型,以及数组、嵌套结构等复杂数据类型。
强大的聚合函数:提供了丰富的聚合函数,如求和、平均值、最大值、最小值等,方便进行数据分析和统计。
支持 SQL 语言:用户可以使用熟悉的 SQL 语句进行数据查询和分析,降低了学习成本。
场景支持
ClickHouse的数据处理速度非常快,尤其适合于包含复杂分析查询的场景
适合场景
日志和事件数据:由于ClickHouse的处理速度,它可以作为实时数据分析的工具。
监控和报警系统:ClickHouse可以用于快速查询和显示监控数据。
交互式查询:由于其快速的查询速度,ClickHouse可以作为数据科学家进行交互式探索的工具。
数据仓库:ClickHouse可以作为数据仓库的一种替代方法,用于快速查询和分析。
不适合场景
事务处理:ClickHouse不支持事务处理。
强一致性:ClickHouse不保证数据的强一致性。
低延迟的更新:ClickHouse不适合于需要实时或近实时更新数据的场景。
高度模式化的数据:ClickHouse对模式的灵活性不如关系型数据库。
小结
总之,ClickHouse 是一款功能强大的数据库管理系统,适用于大规模数据分析和处理场景。通过了解其特点和基础知识,用户可以更好地利用 ClickHouse 来满足自己的数据分析需求 收起阅读 »
【搜索客社区日报】第1954期 (2024-12-18)
https://towardsdatascience.com ... ebfff
2.日志分析大比拼:Elasticsearch VS Apache Doris
https://blog.devgenius.io/log- ... bd2a1
3.什么是语义重排(semantic rerank)?如何使用它?
https://cloud.tencent.com/deve ... 76629
4.介绍 Elastic Rerank:Elastic 的新语义重排模型
https://cloud.tencent.com/deve ... 76632
5.深入探讨高质量重排器及其性能优化:Elastic Rerank模型的实战评估
https://cloud.tencent.com/deve ... 77172
编辑:kin122
更多资讯:http://news.searchkit.cn
https://towardsdatascience.com ... ebfff
2.日志分析大比拼:Elasticsearch VS Apache Doris
https://blog.devgenius.io/log- ... bd2a1
3.什么是语义重排(semantic rerank)?如何使用它?
https://cloud.tencent.com/deve ... 76629
4.介绍 Elastic Rerank:Elastic 的新语义重排模型
https://cloud.tencent.com/deve ... 76632
5.深入探讨高质量重排器及其性能优化:Elastic Rerank模型的实战评估
https://cloud.tencent.com/deve ... 77172
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch Java SDK 2.0.x 使用指南(一)

各位 Easysearch 的小伙伴们,我们前一阵刚把 easysearch-client 更新到了 2.0.2 版本!借此详细介绍下新版客户端的使用。
新版客户端和 1.0 版本相比,完全重构,抛弃了旧版客户端的一些历史包袱,从里到外都焕然一新!不管是刚入门的小白还是经验丰富的老司机,2.0.x 客户端都能让你开发效率蹭蹭往上涨!
到底有啥新东西?
- 更轻更快: 以前的版本依赖了一堆乱七八糟的东西,现在好了,我们把那些没用的都砍掉了,客户端变得更苗条,性能也杠杠的!
- 类型安全,告别迷糊: 常用的 Easysearch API 现在都配上了强类型的请求和响应对象,再也不用担心写错参数类型了,代码也更好看了,维护起来也更省心!
- 同步异步,想咋用咋用: 所有 API 都支持同步和异步两种调用方式,不管是啥场景,都能轻松应对!
- 构建查询,跟搭积木一样简单: 我们用了流式构建器和函数式编程,构建复杂查询的时候,代码写起来那叫一个流畅,看着也舒服!
- 和 Jackson 无缝对接: 可以轻松地把你的 Java 类和客户端 API 关联起来,数据转换嗖嗖的快!
快速上手
废话不多说,咱们直接上干货!这部分教你怎么快速安装和使用 easysearch-client 2.0.2 客户端,还会演示一些基本操作。
安装
easysearch-client 2.0.2 已经上传到 Maven 中央仓库了,加到你的项目里超级方便。
最低要求: JDK 8 或者更高版本
依赖管理: 客户端内部用 Jackson 来处理对象映射。
Maven 项目
在你的 pom.xml 文件的 <dependencies> 里面加上这段:
<dependencies>
<dependency>
<groupId>com.infinilabs</groupId>
<artifactId>easysearch-client</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>Gradle 项目
在你的 build.gradle 文件的 dependencies 里面加上这段:
dependencies {
implementation 'com.infinilabs:easysearch-client:2.0.2'
}初始化客户端
下面这段代码演示了怎么初始化一个启用了安全通信加密和 security 的 Easysearch 客户端,看起来有点长,别慌,我们一步一步解释!
public static EasysearchClient create() throws NoSuchAlgorithmException, KeyStoreException,
KeyManagementException {
final HttpHost[] hosts = new HttpHost[]{new HttpHost("localhost", 9200, "https")};
final SSLContext sslContext = SSLContextBuilder.create()
.loadTrustMaterial(null, (chains, authType) -> true).build();
SSLIOSessionStrategy sessionStrategy = new SSLIOSessionStrategy(sslContext, NoopHostnameVerifier.INSTANCE);
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("username", "passwowd"));
RestClient restClient = RestClient.builder(hosts)
.setHttpClientConfigCallback(httpClientBuilder ->
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
.setSSLStrategy(sessionStrategy)
.disableAuthCaching()
).setRequestConfigCallback(requestConfigCallback ->
requestConfigCallback.setConnectTimeout(30000).setSocketTimeout(300000))
.build();
EasysearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new EasysearchClient(transport);
}这段代码,简单来说,就是:
- 连上 Easysearch: 我们要用 HTTPS 连接到本地的 9200 端口。
- 搞定证书: 这里为了方便,我们信任了所有证书(注意!生产环境一定要配置好你们自己的证书)。
- 填上用户名密码: 这里需要填上你的用户名和密码。
- 设置连接参数: 设置了连接超时时间(30 秒)和读取超时时间(300 秒)。
- 创建客户端: 最后,我们就创建好了一个
EasysearchClient实例,可以开始干活了!
举个栗子:批量操作
下面的例子演示了怎么用 bulk API 来批量索引数据:
public static void bulk() throws Exception {
String json2 = "{"
+ " \"@timestamp\": \"2023-01-08T22:50:13.059Z\","
+ " \"agent\": {"
+ " \"version\": \"7.3.2\","
+ " \"type\": \"filebeat\","
+ " \"ephemeral_id\": \"3ff1f2c8-1f7f-48c2-b560-4272591b8578\","
+ " \"hostname\": \"ba-0226-msa-fbl-747db69c8d-ngff6\""
+ " }"
+ "}";
EasysearchClient client = create();
BulkRequest.Builder br = new BulkRequest.Builder();
br.index("test1");
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
builder.index(indexBuilder.document(JsonData.fromJson(json2)).build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(JsonData.fromJson(json2)).index("test2");
builder.index(indexBuilder.build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
Map<String, Object> map = new HashMap<>();
map.put("@timestamp", "2023-01-08T22:50:13.059Z");
map.put("field1", "value1");
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(map).index("test3");
br.operations(new BulkOperation(indexBuilder.build()));
}
BulkResponse bulkResponse = client.bulk(br.build());
if (bulkResponse.errors()) {
for (BulkResponseItem item : bulkResponse.items()) {
System.out.println(item.toString());
}
}
client._transport().close();
}这个例子里,我们一口气把数据批量索引到了 test1、test2 和 test3 这三个索引里,
并且展示了三种在 bulk API 中构建 IndexOperation 的方式,虽然它们最终都能实现将文档索引到 Easysearch,但在使用场景和灵活性上还是有一些区别的:
这段代码的核心是利用 BulkRequest.Builder 来构建一个批量请求,并通过 br.operations(...) 方法添加多个操作。而每个操作,在这个例子里,都是一个 IndexOperation,也就是索引一个文档。IndexOperation 可以通过 IndexOperation.Builder 来创建。
三种方式的区别主要体现在如何构建 IndexOperation 里的 document 部分,也就是要索引的文档内容。
第一种方式:使用 JsonData.fromJson(json2) 且不指定索引。
特点:
使用 JsonData.fromJson(json2) 将一个 JSON 字符串直接转换成 JsonData 对象作为文档内容。
这里没有在 IndexOperation.Builder 上调用 index() 方法来指定索引名称。由于没有在每个 IndexOperation 中指定索引,这个索引名称将回退到 BulkRequest.Builder 上设置的索引,即 br.index("test1"),所以这 10 个文档都会被索引到 test1。
当你需要将一批相同结构的 JSON 文档索引到同一个索引时,这种方式比较简洁。
第二种方式:使用 JsonData.fromJson(json2) 并指定索引
特点:
同样使用 JsonData.fromJson(json2) 将 JSON 字符串转换成 JsonData 对象。
关键区别在于,这里在 IndexOperation.Builder 上调用了 index("test2"),为每个操作单独指定了索引名称。
这 10 个文档会被索引到 test2,即使 BulkRequest.Builder 上设置了 index("test1") 也没用,因为 IndexOperation 里的设置优先级更高。
当你需要将一批相同结构的 JSON 文档索引到不同的索引时,就需要使用这种方式来分别指定索引。
第三种方式:使用 Map<String, Object> 并指定索引
特点:
使用 Map<String, Object> 来构建文档内容,这种方式更加灵活,可以构建任意结构的文档。
同样在 IndexOperation.Builder 上调用了 index("test3") 指定了索引名称。
使用 new BulkOperation(indexBuilder.build()) 代替之前的 builder.index(indexBuilder.build()), 这是等价的。
这 10 个文档会被索引到 test3。
当你需要索引的文档结构不固定,或者你需要动态构建文档内容时,使用 Map 是最佳选择。例如,你可以根据不同的业务逻辑,往 Map 里添加不同的字段。
总结
这次 easysearch-client 2.0.x Java 客户端的更新真的很给力,强烈建议大家升级体验!相信我,用了新版客户端,你的开发效率绝对会提升一大截!
想要了解更多?
-
客户端 Maven 地址: https://mvnrepository.com/artifact/com.infinilabs/easysearch-client/2.0.2
- 更详细的文档和示例代码在 官网 持续更新中,请随时关注!
大家有啥问题或者建议,也欢迎随时反馈!
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
各位 Easysearch 的小伙伴们,我们前一阵刚把 easysearch-client 更新到了 2.0.2 版本!借此详细介绍下新版客户端的使用。
新版客户端和 1.0 版本相比,完全重构,抛弃了旧版客户端的一些历史包袱,从里到外都焕然一新!不管是刚入门的小白还是经验丰富的老司机,2.0.x 客户端都能让你开发效率蹭蹭往上涨!
到底有啥新东西?
- 更轻更快: 以前的版本依赖了一堆乱七八糟的东西,现在好了,我们把那些没用的都砍掉了,客户端变得更苗条,性能也杠杠的!
- 类型安全,告别迷糊: 常用的 Easysearch API 现在都配上了强类型的请求和响应对象,再也不用担心写错参数类型了,代码也更好看了,维护起来也更省心!
- 同步异步,想咋用咋用: 所有 API 都支持同步和异步两种调用方式,不管是啥场景,都能轻松应对!
- 构建查询,跟搭积木一样简单: 我们用了流式构建器和函数式编程,构建复杂查询的时候,代码写起来那叫一个流畅,看着也舒服!
- 和 Jackson 无缝对接: 可以轻松地把你的 Java 类和客户端 API 关联起来,数据转换嗖嗖的快!
快速上手
废话不多说,咱们直接上干货!这部分教你怎么快速安装和使用 easysearch-client 2.0.2 客户端,还会演示一些基本操作。
安装
easysearch-client 2.0.2 已经上传到 Maven 中央仓库了,加到你的项目里超级方便。
最低要求: JDK 8 或者更高版本
依赖管理: 客户端内部用 Jackson 来处理对象映射。
Maven 项目
在你的 pom.xml 文件的 <dependencies> 里面加上这段:
<dependencies>
<dependency>
<groupId>com.infinilabs</groupId>
<artifactId>easysearch-client</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>Gradle 项目
在你的 build.gradle 文件的 dependencies 里面加上这段:
dependencies {
implementation 'com.infinilabs:easysearch-client:2.0.2'
}初始化客户端
下面这段代码演示了怎么初始化一个启用了安全通信加密和 security 的 Easysearch 客户端,看起来有点长,别慌,我们一步一步解释!
public static EasysearchClient create() throws NoSuchAlgorithmException, KeyStoreException,
KeyManagementException {
final HttpHost[] hosts = new HttpHost[]{new HttpHost("localhost", 9200, "https")};
final SSLContext sslContext = SSLContextBuilder.create()
.loadTrustMaterial(null, (chains, authType) -> true).build();
SSLIOSessionStrategy sessionStrategy = new SSLIOSessionStrategy(sslContext, NoopHostnameVerifier.INSTANCE);
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("username", "passwowd"));
RestClient restClient = RestClient.builder(hosts)
.setHttpClientConfigCallback(httpClientBuilder ->
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
.setSSLStrategy(sessionStrategy)
.disableAuthCaching()
).setRequestConfigCallback(requestConfigCallback ->
requestConfigCallback.setConnectTimeout(30000).setSocketTimeout(300000))
.build();
EasysearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new EasysearchClient(transport);
}这段代码,简单来说,就是:
- 连上 Easysearch: 我们要用 HTTPS 连接到本地的 9200 端口。
- 搞定证书: 这里为了方便,我们信任了所有证书(注意!生产环境一定要配置好你们自己的证书)。
- 填上用户名密码: 这里需要填上你的用户名和密码。
- 设置连接参数: 设置了连接超时时间(30 秒)和读取超时时间(300 秒)。
- 创建客户端: 最后,我们就创建好了一个
EasysearchClient实例,可以开始干活了!
举个栗子:批量操作
下面的例子演示了怎么用 bulk API 来批量索引数据:
public static void bulk() throws Exception {
String json2 = "{"
+ " \"@timestamp\": \"2023-01-08T22:50:13.059Z\","
+ " \"agent\": {"
+ " \"version\": \"7.3.2\","
+ " \"type\": \"filebeat\","
+ " \"ephemeral_id\": \"3ff1f2c8-1f7f-48c2-b560-4272591b8578\","
+ " \"hostname\": \"ba-0226-msa-fbl-747db69c8d-ngff6\""
+ " }"
+ "}";
EasysearchClient client = create();
BulkRequest.Builder br = new BulkRequest.Builder();
br.index("test1");
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
builder.index(indexBuilder.document(JsonData.fromJson(json2)).build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(JsonData.fromJson(json2)).index("test2");
builder.index(indexBuilder.build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
Map<String, Object> map = new HashMap<>();
map.put("@timestamp", "2023-01-08T22:50:13.059Z");
map.put("field1", "value1");
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(map).index("test3");
br.operations(new BulkOperation(indexBuilder.build()));
}
BulkResponse bulkResponse = client.bulk(br.build());
if (bulkResponse.errors()) {
for (BulkResponseItem item : bulkResponse.items()) {
System.out.println(item.toString());
}
}
client._transport().close();
}这个例子里,我们一口气把数据批量索引到了 test1、test2 和 test3 这三个索引里,
并且展示了三种在 bulk API 中构建 IndexOperation 的方式,虽然它们最终都能实现将文档索引到 Easysearch,但在使用场景和灵活性上还是有一些区别的:
这段代码的核心是利用 BulkRequest.Builder 来构建一个批量请求,并通过 br.operations(...) 方法添加多个操作。而每个操作,在这个例子里,都是一个 IndexOperation,也就是索引一个文档。IndexOperation 可以通过 IndexOperation.Builder 来创建。
三种方式的区别主要体现在如何构建 IndexOperation 里的 document 部分,也就是要索引的文档内容。
第一种方式:使用 JsonData.fromJson(json2) 且不指定索引。
特点:
使用 JsonData.fromJson(json2) 将一个 JSON 字符串直接转换成 JsonData 对象作为文档内容。
这里没有在 IndexOperation.Builder 上调用 index() 方法来指定索引名称。由于没有在每个 IndexOperation 中指定索引,这个索引名称将回退到 BulkRequest.Builder 上设置的索引,即 br.index("test1"),所以这 10 个文档都会被索引到 test1。
当你需要将一批相同结构的 JSON 文档索引到同一个索引时,这种方式比较简洁。
第二种方式:使用 JsonData.fromJson(json2) 并指定索引
特点:
同样使用 JsonData.fromJson(json2) 将 JSON 字符串转换成 JsonData 对象。
关键区别在于,这里在 IndexOperation.Builder 上调用了 index("test2"),为每个操作单独指定了索引名称。
这 10 个文档会被索引到 test2,即使 BulkRequest.Builder 上设置了 index("test1") 也没用,因为 IndexOperation 里的设置优先级更高。
当你需要将一批相同结构的 JSON 文档索引到不同的索引时,就需要使用这种方式来分别指定索引。
第三种方式:使用 Map<String, Object> 并指定索引
特点:
使用 Map<String, Object> 来构建文档内容,这种方式更加灵活,可以构建任意结构的文档。
同样在 IndexOperation.Builder 上调用了 index("test3") 指定了索引名称。
使用 new BulkOperation(indexBuilder.build()) 代替之前的 builder.index(indexBuilder.build()), 这是等价的。
这 10 个文档会被索引到 test3。
当你需要索引的文档结构不固定,或者你需要动态构建文档内容时,使用 Map 是最佳选择。例如,你可以根据不同的业务逻辑,往 Map 里添加不同的字段。
总结
这次 easysearch-client 2.0.x Java 客户端的更新真的很给力,强烈建议大家升级体验!相信我,用了新版客户端,你的开发效率绝对会提升一大截!
想要了解更多?
-
客户端 Maven 地址: https://mvnrepository.com/artifact/com.infinilabs/easysearch-client/2.0.2
- 更详细的文档和示例代码在 官网 持续更新中,请随时关注!
大家有啥问题或者建议,也欢迎随时反馈!
收起阅读 »作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
【搜索客社区日报】第1951期 (2024-12-13)
https://mp.weixin.qq.com/s/9voA_HVAnp3DO4RKkr85qQ
2、如何平衡向量检索速度和精度?深度解读 HNSW 算法
https://mp.weixin.qq.com/s/JECoGeO27L1IHdseDBHmow
3、Elasticsearch 进阶篇(三):ik 分词器的使用与项目应用
https://blog.csdn.net/Tingfeng ... 15124
4、【老杨玩搜索】12. Easysearch 页面-multi_match | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV12E2JYsEUS
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/9voA_HVAnp3DO4RKkr85qQ
2、如何平衡向量检索速度和精度?深度解读 HNSW 算法
https://mp.weixin.qq.com/s/JECoGeO27L1IHdseDBHmow
3、Elasticsearch 进阶篇(三):ik 分词器的使用与项目应用
https://blog.csdn.net/Tingfeng ... 15124
4、【老杨玩搜索】12. Easysearch 页面-multi_match | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV12E2JYsEUS
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1950期 (2024-12-12)
https://mp.weixin.qq.com/s/-Jmc2So_fxsryvW_rTa2Qw
2.得物新一代可观测性架构:海量数据下的存算分离设计与实践
https://mp.weixin.qq.com/s/VwGEq-sbEToew3M_F_LvyQ
3.使用 present 工具轻松生成演示文稿
https://charly3pins.dev/blog/l ... th-go
4.京东十亿级订单系统的数据库查询性能优化之路
https://elasticsearch.cn/article/15319
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/-Jmc2So_fxsryvW_rTa2Qw
2.得物新一代可观测性架构:海量数据下的存算分离设计与实践
https://mp.weixin.qq.com/s/VwGEq-sbEToew3M_F_LvyQ
3.使用 present 工具轻松生成演示文稿
https://charly3pins.dev/blog/l ... th-go
4.京东十亿级订单系统的数据库查询性能优化之路
https://elasticsearch.cn/article/15319
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
十亿级订单系统的数据库查询性能优化之路
作者:京东零售 崔健
0.前言
-
系统概要:BIP采购系统用于京东采销部门向供应商采购商品,并且提供了多种创建采购单的方式以及采购单审批、回告、下传回传等业务功能
- 系统价值:向供应商采购商品增加库存,满足库存周转及客户订单的销售,供应链最重要的第一环节
1.背景
采购系统在经历了多年的迭代后,在数据库查询层面面临巨大的性能挑战。核心根因主要有以下几方面:
-
复杂查询多,历史上通过MySQL和JED承载了过多的检索过滤条件,时至今日很难推动接口使用方改变调用方式
-
数据量大,随着业务的持续发展,带来了海量的数据增长(日均150万单左右,订单主表/子表/渠道表/扩展表分别都是:6.5亿行,订单明细表/分配表:9.2亿行,日志表:60亿行)
- 数据模型复杂,订单完整数据分布在20+张表,经常需要多表join
引入的主要问题有:
-
业务层面:
-
订单列表页查询/导出体验差,性能非常依赖输入条件,尤其是在面对订单数据倾斜的时候,部分用户无法查询/导出超过半个月以上的订单
- 查询条件不合理,1.归档筛选条件,技术词汇透传到业务,导致相同周期的单子无法一键查询/导出,需要切换“是否归档”查询全部;2.无法区分“需要仓库收货”类的单子,大部分业务同事主要关注这类单子的履约情况
-
-
技术层面:
-
慢SQL多,各种多表关联复杂条件查询导致,索引、SQL已经优化道了瓶颈,经常出现数据库负载被拉高
-
大表多,难在数据库上做DDL,可能会引起核心写库负载升高、主从延迟等问题
- 模型复杂,开发、迭代成本高,查询索引字段散落在多个表中,导致查询性能下降
-
2.目标
业务层面:提升核心查询/导出体验,加强查询性能,优化不合理的查询条件
技术层面:1.减少慢SQL,降低数据库负载,提高系统稳定性;2.降低单表数据量级;3.简化数据模型
3.挑战
提升海量数据、复杂场景下的查询性能!
- 采购订单系统 VS C端销售订单系统复杂度对比:
| 对比项 | 采购订单系统 | C端订单销售系统 |
|---|---|---|
| 分库逻辑 | 使用采购单号分库 | 按用户pin分库分表 |
| 查询场景 | 面向采销、接口人、供应商、仓储运营提供包括采销员、单号、SKU、供应商、部门、配送中心、库房等多场景复杂查询 | 主要是按用户pin进行订单查询 |
| 单据所属人 | 采购单生成后,采销可以进行单据转移 | 订单生成后订单所属人不变 |
| 数据倾斜 | 单一采销或供应商存在大量采购单,并且自动补货会自动创建采购单 | C端一个用户pin下订单数量有限 |
4.方案
思路
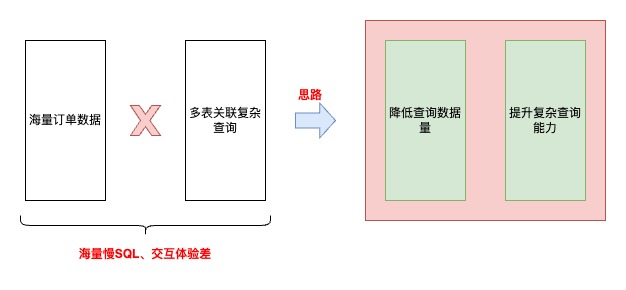
优化前
优化后

4.1 降低查询数据量
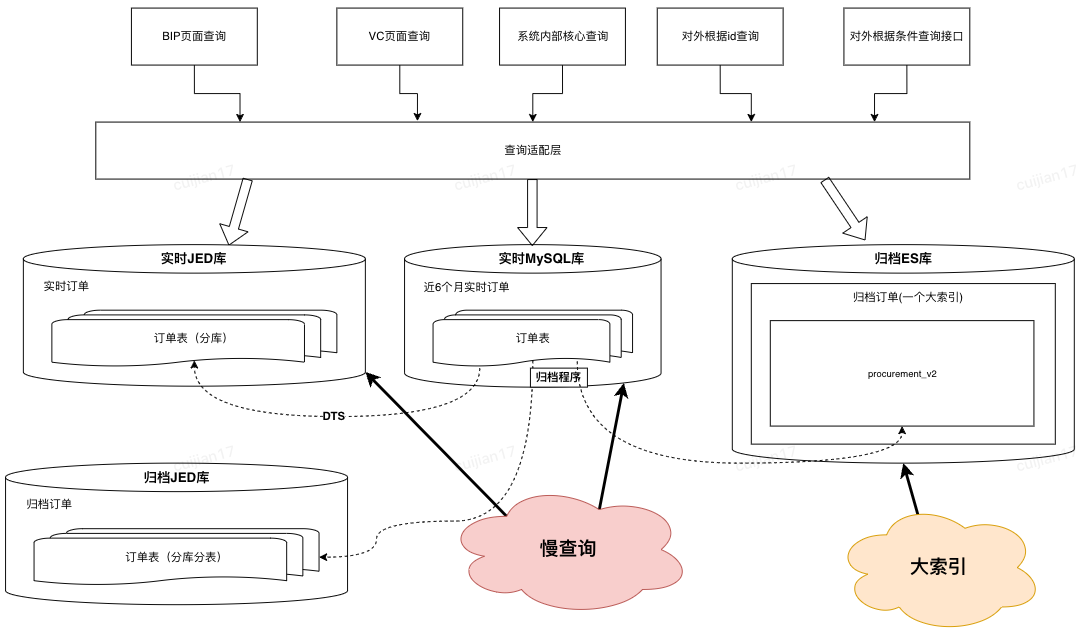
4.1.1 前期调研
基于历史数据、业务调研分析,采购订单只有8%的订单属于“需要实际送货至京东库房”的范围,也就是拥有完整订单履约流程、业务核心关注时效的。其余订单属于通过客户订单驱动,在采购系统的生命周期只有创建记录

基于以上结论,在与产品达成共识后,提出新的业务领域概念:“入库订单” ,在查询时单独异构这部分订单数据(前期也曾考虑过,直接从写入层面拆分入库订单,但是因为开发成本、改动范围被pass了)。异构这部分数据实际也参考了操作系统、中间件的核心优化思路,缓存访问频次高的热数据
4.1.2 入库订单异构
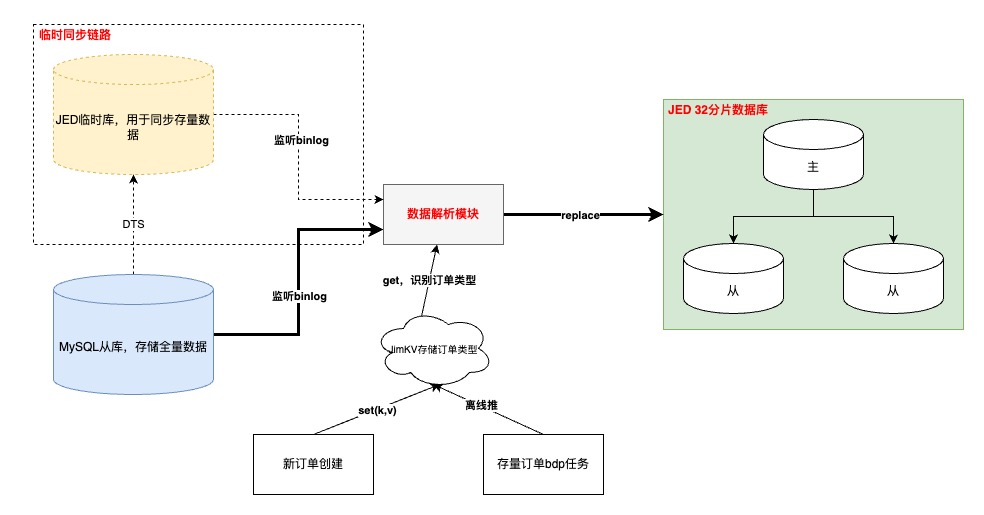
执行流程
-
“入库”订单数据打标
-
增量订单在创建订单完成时写入;存量订单通过离线表推数
-
需要订单创建模块先完成改造上线,再同步历史,保证数据不丢
- 如果在【数据解析模块】处理binlog时无法及时从JimKV获取到订单标识,会补偿反查数据库并回写JimKV,提升其他表的binlog处理效率
-
-
binlog监听
-
基于公司的【数据订阅】任务,通过消费JMQ实现。其中订阅任务基于订单号进行MQ数据分区,并且在消费端配置不允许消息重试,防止消息时序错乱
- 其中,根据订单号进行各个表的MQ数据分区,第一版设计可能会引起热分区,导致消费速率变慢,基于这个问题识别到热分区主要是由于频繁更新订单明细数据导致(订单(1)->明细(N)),于是将明细相关表基于自身id进行分区,其他订单纬度表还是基于订单号。这样既不影响订单数据更新的先后顺序,也不会造成热分区、还可以保证明细数据的准确性
-
-
数据同步
-
增量数据同步可以采用源库的增量binlog进行解析即可,存量数据通过申请新库/表,进行DTS的存量+增量同步写入,完成binlog生产
- 以上是在上线前的临时链路,上线后需要切换到源库同步binlog的增量订阅任务,此时依赖“位点回拨”+“数据可重入”。位点回拨基于订阅任务的binlog时间戳,数据可重入依赖上文提到的MQ消费有序以及SQL覆盖写
-
-
数据校对
-
以表为纬度,优先统计总数,再随机抽样明细进行比对
- 目前入库订单量为稳定在5000万,全部实时订单量级6.5亿,降低92%
-
4.2 提升复杂查询能力
4.2.1 数据准备
-
考虑到异构“入库”订单到JED,虽然数据查询时效性可以有一定保障,但是在复杂查询能力以及识别“非入库”订单还没有支持
-
其中,“非入库”订单业务对于订单数据时效性要求并不高(1.订单创建源于客户订单;2.没有履约流程;3.无需手动操作订单关键节点)
- 所以,考虑将这部分查询能力转移到ES上
ES数据异构过程
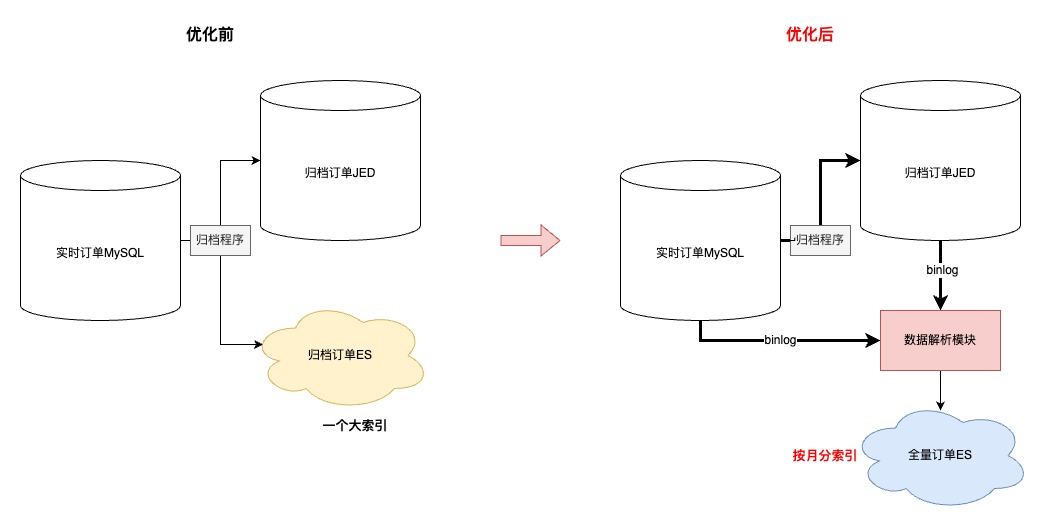
-
首先,同步到ES的数据的由“实时+归档”订单组成,其中合计20亿订单,顺带优化了先前归档ES大索引(所有订单放在同一个索引)的问题,改成基于“月份”存储订单,之所以改成月份是因为根据条件查询分两种:1.一定会有查询时间范围(最多3个月);2.指定单号查询,这种会优先检索单号对应的订单创建时间,再路由到指定索引
-
其次,简化了归档程序流程,历史方案是程序中直接写入【归档JED+归档ES】,现在优化成只写入JED,ES数据通过【数据解析模块】完成,简化归档程序的同时,提高了归档能力的时效性
-
再次,因为ES是存储全量订单,需要支持复杂条件的查询,所以在订单没有物理删除的前提下,【数据解析模块】会过滤所有delete语句,保证全量订单数据的完整性
-
接着,为了提升同步到ES数据的吞吐,在MQ消费端,主要做了两方面优化:1.会根据表和具体操作进行binlog的请求合并;2.降低对于ES内部refresh机制的依赖,将2分钟内更新到ES的数据缓存到JimKV,更新前从缓存中获取
- 最后,上文提到,同步到入库JED,有的表是根据订单号,有的表是根据自身id。那么ES这里,因为NoSQL的设计,和线程并发的问题,为了防止数据错误,只能将所有表数据根据单号路由到相同的MQ分区
4.2.2 查询调度策略设计
优化前,所有的查询请求都会直接落到数据库进行查询,可以高效查询完全取决于用户的筛选条件是否可以精准缩小数据查询范围
优化后,新增动态路由层
-
离线计算T-1的采销/供应商的订单数据倾斜,将数据倾斜情况推送到JimDB集群
- 根据登陆用户、数据延迟要求、查询数据范围,自动调度查询的数据集群,实现高性能的查询请求
查询调度
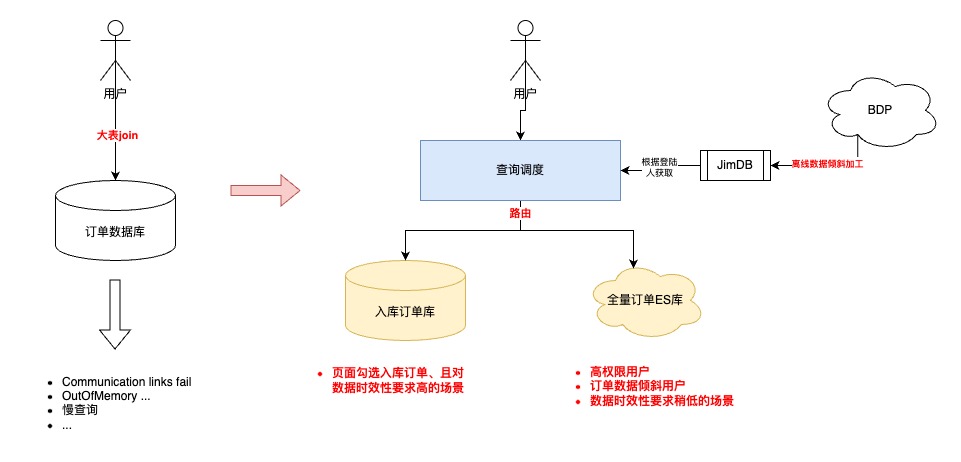
5.ES主备机制&数据监控
1.主/备ES可以通过DUCC开关,实现动态切换,提升数据可靠性
2.结合公司的业务监控,完成订单数据延迟监控(数据同步模块写入时间-订单创建时间)
3.开启消息队列积压告警
5.1 ES集群主/备机制
1:1ES集群进行互备,应急预案快速切换,保证高可用

5.2 数据监控

6.灰度上线
-
第一步,优先上线数据模块,耗费较多时间的原因:1.整体数据量级以及历史数据复杂度的问题;2.数据同步链路比较长,中间环节多
-
第二步,预发环境验证,流量回放并没有做到长周期的完全自动化,根因:1.项目周期相对紧张;2.新老集群的数据还是有一些区别,回放脚本不够完善
-
第三步,用户功能灰度,主要是借助JDOS的负载均衡策略结合用户erp完成
- 第四部,对外接口灰度,通过控制新代码灰度容器个数,逐步放量
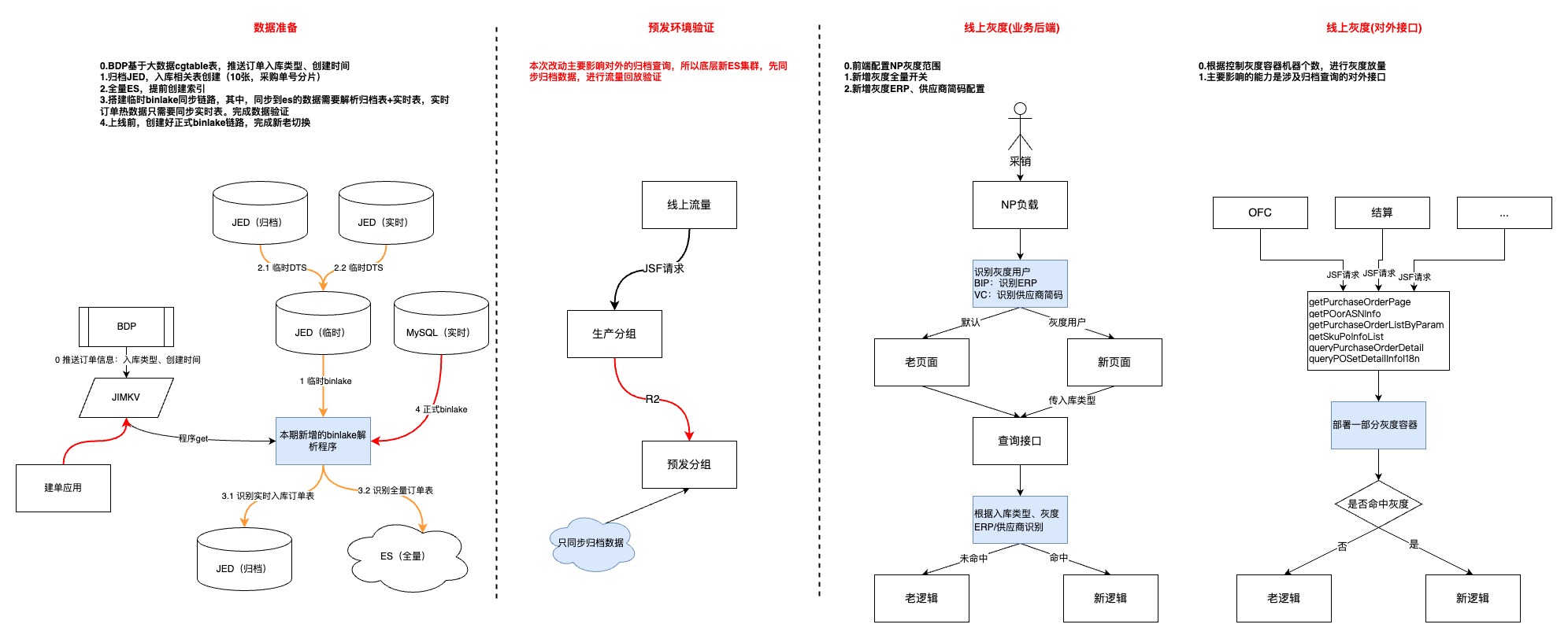
7.成果
平稳切换,无线上问题
| 指标 | 具体提升 |
|---|---|
| 采购列表查询(ms) | 1、TP999:4817 优化到 2872,提升40.37% 2、超管、部门管理员由无法查询超过一周范围的订单,优化为可以在2秒内查询3个月的订单 3、页面删除“是否归档”查询条件,简化业务操作 4、页面新增“是否入库”查询条件,聚焦核心业务数据 |
| 仓储运营列表(ms) | TP999:9009 优化到 6545,提升27.34% |
| 采购统计查询(ms) | TP999:13219 优化到 1546,提升88.3% |
| 慢SQL指标(天纬度) | 1、1s-2s慢SQL数:820->72,降低91% 2、2s-5s慢SQL数:276->26,降低90% 3、5s以上慢SQL数:343->6,降低98% |
8.待办
-
主动监控层面,新增按照天纬度进行数据比对、异常告警的能力,提高问题发现率
-
优化数据模型,对历史无用订单表进行精简,降低开发、运维成本,提升需求迭代效率
-
精简存储集群
-
逐步下线其他非核心业务存储集群,减少外部依赖,提高系统容错度
- 目前全量订单ES集群已经可以支持多场景的外部查询,未来考虑是否可以逐步下线入库订单JED
-
-
识别数据库隐患,基于慢日志监控,重新梳理引入模块,逐步优化,持续降低数据库负载
-
MySQL减负,探索其他优化方案,减少数据量存储,提升数据灵活性。优先从业务层面出发,识别库里进行中的僵尸订单的根因,进行分类,强制结束
- 降级方案,当数据同步或者数据库存在异常时,可以做到秒级无感切换,提升业务可用率
9.写在最后
-
为什么没考虑Doris?因为ES是团队应用相对成熟的中间件,处于学习、开发成本考虑
-
未来入库的JED相关表是否可以下掉,用ES完全替代?目前看可以,当初设计冗余入库JED也是出于对于ES不确定性以及数据延迟的角度考虑,而且历史的一部分查询就落在了异构的全量实时订单JED上。现在,JED官方也不是很推荐非route key的查询。最后,现阶段因为降低了数据量和拆分了业务场景,入库JED的查询性能还是非常不错的
- 因为项目排期、个人能力的因素,在方案设计上会有考虑不周的场景,本期只是优化了最核心的业务、技术痛点,未来还有很大持续优化的空间。中间件的使用并不是可以优化数据库性能的银弹,最核心的还是要结合业务以及系统历史背景,在不断纠结当中寻找balance
作者:京东零售 崔健
0.前言
-
系统概要:BIP采购系统用于京东采销部门向供应商采购商品,并且提供了多种创建采购单的方式以及采购单审批、回告、下传回传等业务功能
- 系统价值:向供应商采购商品增加库存,满足库存周转及客户订单的销售,供应链最重要的第一环节
1.背景
采购系统在经历了多年的迭代后,在数据库查询层面面临巨大的性能挑战。核心根因主要有以下几方面:
-
复杂查询多,历史上通过MySQL和JED承载了过多的检索过滤条件,时至今日很难推动接口使用方改变调用方式
-
数据量大,随着业务的持续发展,带来了海量的数据增长(日均150万单左右,订单主表/子表/渠道表/扩展表分别都是:6.5亿行,订单明细表/分配表:9.2亿行,日志表:60亿行)
- 数据模型复杂,订单完整数据分布在20+张表,经常需要多表join
引入的主要问题有:
-
业务层面:
-
订单列表页查询/导出体验差,性能非常依赖输入条件,尤其是在面对订单数据倾斜的时候,部分用户无法查询/导出超过半个月以上的订单
- 查询条件不合理,1.归档筛选条件,技术词汇透传到业务,导致相同周期的单子无法一键查询/导出,需要切换“是否归档”查询全部;2.无法区分“需要仓库收货”类的单子,大部分业务同事主要关注这类单子的履约情况
-
-
技术层面:
-
慢SQL多,各种多表关联复杂条件查询导致,索引、SQL已经优化道了瓶颈,经常出现数据库负载被拉高
-
大表多,难在数据库上做DDL,可能会引起核心写库负载升高、主从延迟等问题
- 模型复杂,开发、迭代成本高,查询索引字段散落在多个表中,导致查询性能下降
-
2.目标
业务层面:提升核心查询/导出体验,加强查询性能,优化不合理的查询条件
技术层面:1.减少慢SQL,降低数据库负载,提高系统稳定性;2.降低单表数据量级;3.简化数据模型
3.挑战
提升海量数据、复杂场景下的查询性能!
- 采购订单系统 VS C端销售订单系统复杂度对比:
| 对比项 | 采购订单系统 | C端订单销售系统 |
|---|---|---|
| 分库逻辑 | 使用采购单号分库 | 按用户pin分库分表 |
| 查询场景 | 面向采销、接口人、供应商、仓储运营提供包括采销员、单号、SKU、供应商、部门、配送中心、库房等多场景复杂查询 | 主要是按用户pin进行订单查询 |
| 单据所属人 | 采购单生成后,采销可以进行单据转移 | 订单生成后订单所属人不变 |
| 数据倾斜 | 单一采销或供应商存在大量采购单,并且自动补货会自动创建采购单 | C端一个用户pin下订单数量有限 |
4.方案
思路
优化前
优化后
4.1 降低查询数据量
4.1.1 前期调研
基于历史数据、业务调研分析,采购订单只有8%的订单属于“需要实际送货至京东库房”的范围,也就是拥有完整订单履约流程、业务核心关注时效的。其余订单属于通过客户订单驱动,在采购系统的生命周期只有创建记录
基于以上结论,在与产品达成共识后,提出新的业务领域概念:“入库订单” ,在查询时单独异构这部分订单数据(前期也曾考虑过,直接从写入层面拆分入库订单,但是因为开发成本、改动范围被pass了)。异构这部分数据实际也参考了操作系统、中间件的核心优化思路,缓存访问频次高的热数据
4.1.2 入库订单异构
执行流程
-
“入库”订单数据打标
-
增量订单在创建订单完成时写入;存量订单通过离线表推数
-
需要订单创建模块先完成改造上线,再同步历史,保证数据不丢
- 如果在【数据解析模块】处理binlog时无法及时从JimKV获取到订单标识,会补偿反查数据库并回写JimKV,提升其他表的binlog处理效率
-
-
binlog监听
-
基于公司的【数据订阅】任务,通过消费JMQ实现。其中订阅任务基于订单号进行MQ数据分区,并且在消费端配置不允许消息重试,防止消息时序错乱
- 其中,根据订单号进行各个表的MQ数据分区,第一版设计可能会引起热分区,导致消费速率变慢,基于这个问题识别到热分区主要是由于频繁更新订单明细数据导致(订单(1)->明细(N)),于是将明细相关表基于自身id进行分区,其他订单纬度表还是基于订单号。这样既不影响订单数据更新的先后顺序,也不会造成热分区、还可以保证明细数据的准确性
-
-
数据同步
-
增量数据同步可以采用源库的增量binlog进行解析即可,存量数据通过申请新库/表,进行DTS的存量+增量同步写入,完成binlog生产
- 以上是在上线前的临时链路,上线后需要切换到源库同步binlog的增量订阅任务,此时依赖“位点回拨”+“数据可重入”。位点回拨基于订阅任务的binlog时间戳,数据可重入依赖上文提到的MQ消费有序以及SQL覆盖写
-
-
数据校对
-
以表为纬度,优先统计总数,再随机抽样明细进行比对
- 目前入库订单量为稳定在5000万,全部实时订单量级6.5亿,降低92%
-
4.2 提升复杂查询能力
4.2.1 数据准备
-
考虑到异构“入库”订单到JED,虽然数据查询时效性可以有一定保障,但是在复杂查询能力以及识别“非入库”订单还没有支持
-
其中,“非入库”订单业务对于订单数据时效性要求并不高(1.订单创建源于客户订单;2.没有履约流程;3.无需手动操作订单关键节点)
- 所以,考虑将这部分查询能力转移到ES上
ES数据异构过程
-
首先,同步到ES的数据的由“实时+归档”订单组成,其中合计20亿订单,顺带优化了先前归档ES大索引(所有订单放在同一个索引)的问题,改成基于“月份”存储订单,之所以改成月份是因为根据条件查询分两种:1.一定会有查询时间范围(最多3个月);2.指定单号查询,这种会优先检索单号对应的订单创建时间,再路由到指定索引
-
其次,简化了归档程序流程,历史方案是程序中直接写入【归档JED+归档ES】,现在优化成只写入JED,ES数据通过【数据解析模块】完成,简化归档程序的同时,提高了归档能力的时效性
-
再次,因为ES是存储全量订单,需要支持复杂条件的查询,所以在订单没有物理删除的前提下,【数据解析模块】会过滤所有delete语句,保证全量订单数据的完整性
-
接着,为了提升同步到ES数据的吞吐,在MQ消费端,主要做了两方面优化:1.会根据表和具体操作进行binlog的请求合并;2.降低对于ES内部refresh机制的依赖,将2分钟内更新到ES的数据缓存到JimKV,更新前从缓存中获取
- 最后,上文提到,同步到入库JED,有的表是根据订单号,有的表是根据自身id。那么ES这里,因为NoSQL的设计,和线程并发的问题,为了防止数据错误,只能将所有表数据根据单号路由到相同的MQ分区
4.2.2 查询调度策略设计
优化前,所有的查询请求都会直接落到数据库进行查询,可以高效查询完全取决于用户的筛选条件是否可以精准缩小数据查询范围
优化后,新增动态路由层
-
离线计算T-1的采销/供应商的订单数据倾斜,将数据倾斜情况推送到JimDB集群
- 根据登陆用户、数据延迟要求、查询数据范围,自动调度查询的数据集群,实现高性能的查询请求
查询调度
5.ES主备机制&数据监控
1.主/备ES可以通过DUCC开关,实现动态切换,提升数据可靠性
2.结合公司的业务监控,完成订单数据延迟监控(数据同步模块写入时间-订单创建时间)
3.开启消息队列积压告警
5.1 ES集群主/备机制
1:1ES集群进行互备,应急预案快速切换,保证高可用
5.2 数据监控
6.灰度上线
-
第一步,优先上线数据模块,耗费较多时间的原因:1.整体数据量级以及历史数据复杂度的问题;2.数据同步链路比较长,中间环节多
-
第二步,预发环境验证,流量回放并没有做到长周期的完全自动化,根因:1.项目周期相对紧张;2.新老集群的数据还是有一些区别,回放脚本不够完善
-
第三步,用户功能灰度,主要是借助JDOS的负载均衡策略结合用户erp完成
- 第四部,对外接口灰度,通过控制新代码灰度容器个数,逐步放量
7.成果
平稳切换,无线上问题
| 指标 | 具体提升 |
|---|---|
| 采购列表查询(ms) | 1、TP999:4817 优化到 2872,提升40.37% 2、超管、部门管理员由无法查询超过一周范围的订单,优化为可以在2秒内查询3个月的订单 3、页面删除“是否归档”查询条件,简化业务操作 4、页面新增“是否入库”查询条件,聚焦核心业务数据 |
| 仓储运营列表(ms) | TP999:9009 优化到 6545,提升27.34% |
| 采购统计查询(ms) | TP999:13219 优化到 1546,提升88.3% |
| 慢SQL指标(天纬度) | 1、1s-2s慢SQL数:820->72,降低91% 2、2s-5s慢SQL数:276->26,降低90% 3、5s以上慢SQL数:343->6,降低98% |
8.待办
-
主动监控层面,新增按照天纬度进行数据比对、异常告警的能力,提高问题发现率
-
优化数据模型,对历史无用订单表进行精简,降低开发、运维成本,提升需求迭代效率
-
精简存储集群
-
逐步下线其他非核心业务存储集群,减少外部依赖,提高系统容错度
- 目前全量订单ES集群已经可以支持多场景的外部查询,未来考虑是否可以逐步下线入库订单JED
-
-
识别数据库隐患,基于慢日志监控,重新梳理引入模块,逐步优化,持续降低数据库负载
-
MySQL减负,探索其他优化方案,减少数据量存储,提升数据灵活性。优先从业务层面出发,识别库里进行中的僵尸订单的根因,进行分类,强制结束
- 降级方案,当数据同步或者数据库存在异常时,可以做到秒级无感切换,提升业务可用率
9.写在最后
-
为什么没考虑Doris?因为ES是团队应用相对成熟的中间件,处于学习、开发成本考虑
-
未来入库的JED相关表是否可以下掉,用ES完全替代?目前看可以,当初设计冗余入库JED也是出于对于ES不确定性以及数据延迟的角度考虑,而且历史的一部分查询就落在了异构的全量实时订单JED上。现在,JED官方也不是很推荐非route key的查询。最后,现阶段因为降低了数据量和拆分了业务场景,入库JED的查询性能还是非常不错的
- 因为项目排期、个人能力的因素,在方案设计上会有考虑不周的场景,本期只是优化了最核心的业务、技术痛点,未来还有很大持续优化的空间。中间件的使用并不是可以优化数据库性能的银弹,最核心的还是要结合业务以及系统历史背景,在不断纠结当中寻找balance
【搜索客社区日报】第1949期 (2024-12-11)
https://mp.weixin.qq.com/s/MFoQwcYA8jNVz4FlYSTRkQ
2.向量化引擎中的“小文件合并”
https://mp.weixin.qq.com/s/CgouiTvo1CcB9kiJE8sEUQ
3.Elasticsearch ILM 故障排除:常见问题及修复
https://blog.csdn.net/UbuntuTo ... 42632
4.ES 同义词使用手册(搭梯)
https://medium.com/%40halilbul ... b4041
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/MFoQwcYA8jNVz4FlYSTRkQ
2.向量化引擎中的“小文件合并”
https://mp.weixin.qq.com/s/CgouiTvo1CcB9kiJE8sEUQ
3.Elasticsearch ILM 故障排除:常见问题及修复
https://blog.csdn.net/UbuntuTo ... 42632
4.ES 同义词使用手册(搭梯)
https://medium.com/%40halilbul ... b4041
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1948期 (2024-12-10)
https://medium.com/%40rana.ash ... 69803
2. ES灭霸之为了性能我们直接干掉了90%的分片(需要梯子)
https://medium.com/kudos-engin ... 49fad
3. ES 升级那些事儿(需要梯子)
https://medium.com/%40idankoch ... 34b0d
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40rana.ash ... 69803
2. ES灭霸之为了性能我们直接干掉了90%的分片(需要梯子)
https://medium.com/kudos-engin ... 49fad
3. ES 升级那些事儿(需要梯子)
https://medium.com/%40idankoch ... 34b0d
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1947期 (2024-12-09)
https://mp.weixin.qq.com/s/YIPmEKHsfW5xqYAUSl2_zg
2、拒绝“道德正确”:让大模型写出人味
https://mp.weixin.qq.com/s/4o5ZfQao5ESuqETm-VjSNA
3、微服务篇-深入了解 Elasticsearch 基础概念、Elasticsearch 倒排索引、IK 分词器(拓展词典)
https://blog.csdn.net/Tingfeng ... 15124
4、探索Google Vertex AI向量搜索:构建现代化向量数据库的指南
https://blog.csdn.net/fqhwsdrg ... 09040
5、一个自动驾驶产品经理的ChatGPT方法论:BORE
https://mp.weixin.qq.com/s/AGdTBGn9vQrApZwPrAmxtQ
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/YIPmEKHsfW5xqYAUSl2_zg
2、拒绝“道德正确”:让大模型写出人味
https://mp.weixin.qq.com/s/4o5ZfQao5ESuqETm-VjSNA
3、微服务篇-深入了解 Elasticsearch 基础概念、Elasticsearch 倒排索引、IK 分词器(拓展词典)
https://blog.csdn.net/Tingfeng ... 15124
4、探索Google Vertex AI向量搜索:构建现代化向量数据库的指南
https://blog.csdn.net/fqhwsdrg ... 09040
5、一个自动驾驶产品经理的ChatGPT方法论:BORE
https://mp.weixin.qq.com/s/AGdTBGn9vQrApZwPrAmxtQ
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
极限科技三周年庆典:追求极致,共创未来科技新篇章
2024 年 12 月 3 日,一场盛大的庆典活动在香港 IFS 集团旗下长沙玛珂酒店璀璨启幕,极限科技迎来了其三周年的辉煌庆典。此次庆典不仅是对极限科技过往成就的回顾与庆祝,更是对未来科技梦想的展望并开始新的启航。

庆典现场,极限科技的全体员工、尊贵的合作伙伴以及长期以来给予我们坚定支持的客户欢聚一堂,共同见证了这一重要时刻。

活动伊始,极限科技的创始人曾勇回顾了公司创立至今的点点滴滴,他提到,“极限科技”的名称,源于公司的口号:追求极致,无限可能。这不仅是对公司理念的精准诠释,更有一层深刻的寓意,即公司坚信唯有不断打磨产品、精益求精,才能在激烈的市场竞争中立足并持续前行。

曾勇还回顾了极限科技的成长历程,作为国内为数不多的以搜索技术为核心的技术创业公司,自成立之初,极限科技便确立了“让搜索更简单”的目标,并将简单、易用、极致、创新作为产品哲学的核心。他感慨道,正是有了这样的信念和追求,极限科技才能在短短三年内取得优秀的成绩。

曾勇还表示极限科技的基因中始终与开源紧密相连。极限科技一直致力于为开发者和企业提供优质的开源工具,提升整个技术生态的活力。除了维护国内最流行的分词器 analysis-ik 和 analysis-pinyin,也在不断推动更多高质量开源产品的诞生。
在极限科技成立三周年之际,曾勇宣布以下产品和工具已全面开源:
- INFINI Framework
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Coco AI
以上开源软件都可以在 Github 上面找到: https://github.com/infinilabs

随后,极限科技的联合创始人也发表了讲话,分享了创业的艰辛与成功的喜悦,并对所有员工的辛勤付出和合作伙伴的鼎力支持表达了由衷的感谢。

此外,来自行业内外的合作伙伴们也纷纷上台发言,他们高度评价了极限科技在科技创新领域所取得的卓越成就,并对公司未来的发展寄予了厚望。在圆桌讨论环节,与会嘉宾围绕国产化、AI,出海和全球化等前沿话题展开了深入探讨,分享了各自的观点与见解,为极限科技未来的发展提供了宝贵的思路与建议。

整个庆典活动氛围热烈而欢快,与会者们在轻松愉快的氛围中交流心得、分享经验,共同探讨了科技行业的未来发展趋势与机遇。
极限科技作为一家致力于科技创新的先进性企业,坚守引领搜索数据库技术从近实时迈向实时,推动行业的技术迭代与革命为使命。在未来的日子里,极限科技将继续携手合作伙伴,共同开创科技事业的新篇章,为实现更加美好的明天而不懈努力。
此次三周年庆典不仅是对极限科技过去三年努力的肯定与庆祝,更是对未来发展的美好期许并制定航向。我们相信,在全体员工的共同努力和合作伙伴的鼎力支持下,极限科技必将迎来更加辉煌的明天!
原文:https://infinilabs.cn/blog/2024/INFINILabs-3rd-anniversary-celebration/
2024 年 12 月 3 日,一场盛大的庆典活动在香港 IFS 集团旗下长沙玛珂酒店璀璨启幕,极限科技迎来了其三周年的辉煌庆典。此次庆典不仅是对极限科技过往成就的回顾与庆祝,更是对未来科技梦想的展望并开始新的启航。
庆典现场,极限科技的全体员工、尊贵的合作伙伴以及长期以来给予我们坚定支持的客户欢聚一堂,共同见证了这一重要时刻。
活动伊始,极限科技的创始人曾勇回顾了公司创立至今的点点滴滴,他提到,“极限科技”的名称,源于公司的口号:追求极致,无限可能。这不仅是对公司理念的精准诠释,更有一层深刻的寓意,即公司坚信唯有不断打磨产品、精益求精,才能在激烈的市场竞争中立足并持续前行。
曾勇还回顾了极限科技的成长历程,作为国内为数不多的以搜索技术为核心的技术创业公司,自成立之初,极限科技便确立了“让搜索更简单”的目标,并将简单、易用、极致、创新作为产品哲学的核心。他感慨道,正是有了这样的信念和追求,极限科技才能在短短三年内取得优秀的成绩。
曾勇还表示极限科技的基因中始终与开源紧密相连。极限科技一直致力于为开发者和企业提供优质的开源工具,提升整个技术生态的活力。除了维护国内最流行的分词器 analysis-ik 和 analysis-pinyin,也在不断推动更多高质量开源产品的诞生。
在极限科技成立三周年之际,曾勇宣布以下产品和工具已全面开源:
- INFINI Framework
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Coco AI
以上开源软件都可以在 Github 上面找到: https://github.com/infinilabs
随后,极限科技的联合创始人也发表了讲话,分享了创业的艰辛与成功的喜悦,并对所有员工的辛勤付出和合作伙伴的鼎力支持表达了由衷的感谢。
此外,来自行业内外的合作伙伴们也纷纷上台发言,他们高度评价了极限科技在科技创新领域所取得的卓越成就,并对公司未来的发展寄予了厚望。在圆桌讨论环节,与会嘉宾围绕国产化、AI,出海和全球化等前沿话题展开了深入探讨,分享了各自的观点与见解,为极限科技未来的发展提供了宝贵的思路与建议。
整个庆典活动氛围热烈而欢快,与会者们在轻松愉快的氛围中交流心得、分享经验,共同探讨了科技行业的未来发展趋势与机遇。
极限科技作为一家致力于科技创新的先进性企业,坚守引领搜索数据库技术从近实时迈向实时,推动行业的技术迭代与革命为使命。在未来的日子里,极限科技将继续携手合作伙伴,共同开创科技事业的新篇章,为实现更加美好的明天而不懈努力。
此次三周年庆典不仅是对极限科技过去三年努力的肯定与庆祝,更是对未来发展的美好期许并制定航向。我们相信,在全体员工的共同努力和合作伙伴的鼎力支持下,极限科技必将迎来更加辉煌的明天!
收起阅读 »原文:https://infinilabs.cn/blog/2024/INFINILabs-3rd-anniversary-celebration/
【搜索客社区日报】第1946期 (2024-12-06)
https://infinilabs.cn/blog/202 ... tion/
2、Elasticsearch 到 Elasticsearch 数据迁移同步
https://mp.weixin.qq.com/s/qu-UqlWis-jjtFxkHPKavw
3、Elasticsearch:检索器(Retrievers)介绍
https://my.oschina.net/u/3343882/blog/16600478
4、【老杨玩搜索】11. Easysearch 导入数据 | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV1P8tLe2EqJ/
编辑:Fred
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... tion/
2、Elasticsearch 到 Elasticsearch 数据迁移同步
https://mp.weixin.qq.com/s/qu-UqlWis-jjtFxkHPKavw
3、Elasticsearch:检索器(Retrievers)介绍
https://my.oschina.net/u/3343882/blog/16600478
4、【老杨玩搜索】11. Easysearch 导入数据 | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV1P8tLe2EqJ/
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1945期 (2024-12-05)
https://juejin.cn/post/7441138589116858419
2.哪种 GPU 共享策略适合你?
https://kccncna2024.sched.com/event/1i7ol
3.Elasticsearch 中的热点以及如何使用 AutoOps 解决它们
https://www.elastic.co/search- ... toops
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://juejin.cn/post/7441138589116858419
2.哪种 GPU 共享策略适合你?
https://kccncna2024.sched.com/event/1i7ol
3.Elasticsearch 中的热点以及如何使用 AutoOps 解决它们
https://www.elastic.co/search- ... toops
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
写在极限科技成立三周年之际 - 曾勇(Medcl)
2021 年 12 月 3 日,极限科技正式成立。
不知不觉,从所谓的创业寒冬中出来创业已有三载有余,从最初的几个人到如今的团队壮大,和一群志同道合的伙伴们在一起齐心协力,为共同的理想奋力前行,幸甚至哉。
这一路上,既有艰辛与挑战,也有无数令人欣慰和自豪的瞬间。满怀感恩、感谢、感激,我们因每一位支持者和同行者而倍感荣幸。
初心与理念:打造极致体验的产品哲学
成立之初,我就为公司确立了以下方向:
愿景
用十年时间成为全球排名第一的搜索型数据库厂商。
使命
引领搜索数据库技术从近实时迈向实时,推动行业的技术迭代与革新。
价值观
做用户需要的产品,给客户带来的价值就是我们的价值!

“极限科技”的名称,源于我们的口号:追求极致,无限可能。还有一层寓意,我们坚信,唯有不断打磨产品、精益求精,才能在激烈的市场竞争中立足并持续前行。
作为国内为数不多的以搜索技术为核心的技术创业公司,成立之初,我们便确立了“让搜索更简单”的目标,并将简单、易用、极致、创新作为产品哲学的核心。
基于我们对于客户痛点和行业的理解,我们开发了一系列围绕搜索场景及相关技术的工具与产品,致力于为企业提供更高效、更易用的企业级搜索解决方案。了解我们产品的朋友应该就会感受到我们的产品有什么不同,我们不仅关注功能,同时也关注产品的使用体验,如何让产品更小更轻量级,如何让用户更快上手,如何让操作更符合人体工学。
正是这种对极致体验的不断追求,让极限科技在市场中独树一帜,赢得了用户与行业的高度认可。未来,我们将继续秉持初心,致力于为更多用户带来更加卓越的搜索体验。
里程碑产品与技术突破
总的来说,发布了一些产品,也算是取得了一些不错的进展,在公司成立三周年之际,也简单的给大家作一下汇报和总结。

2021 年 12 月,我们发布了第一个产品叫:极限网关/INFINI Gateway,在极限网关发布的头几个月内就突破了 100 万的下载量,极限网关是一个面向搜索业务场景的网关,完全从零自研,为解决沉淀了多年来我们给客户服务过程中遇到的各种痛点而成,我们做了非常多的创新,比如我们自带浮动 IP 能力,网关双节点高可用变得非常简单,又比如我们独创的在网关层进行 Bulk 请求的无缝分拆合并,业界唯一,在大分片场景为我们某个客户提供了 200 倍的索引重建速度提升,收效明显。又比如我们首创的基于网关来进行无缝迁移和无缝重建等等,还有很多非常多场景化的功能,在此就不一一细述了。

2022 年 7 月,我们又发布了一个新产品:INFINI Console,完全从零自研,是一个面向搜索基础设施的多集群管控平台,支持同时纳管不同的搜索引擎,主要是 Elasticsearch、OpenSearch,以及我们自己后面推出的 Easysearch,她的主要特点是可以跨版本和跨引擎管理,让多集群的管理非常简单,能同时做到不同引擎不同版本可以无缝管理的,目前市面上也就只有我们的这个产品。我们提供的多 Tab 页开发工具使用起来非常方便,监控粒度指标是最全的,可以细化到分片级别的各项指标,我们的探针资源利用率低,客户在线上稳定运行两年了,内存也才 20 几 MB,CPU 更是 1%以内,告警能力也是非常灵活。社区用户反馈也是非常不错。

2023 年 5 月,后面随着业务的发展和客户的需求,我们分叉了开源的 Elasticsearch,并维护发行了自己的分支版本,取名为 INFINI Easysearch,修复完善了原生版本的不少 Bug 和内核缺陷,补齐了很多企业级必需的功能,并做了大量的性能优化,以普通 NGINX 日志数据为例,相比原生版本,我们提升了超过 70% 的索引性能,却只需要三分之一的磁盘存储需求,降本增效明显。
2023 年 7 月,Easysearch 率先通过可信数据库相关测试,荣获中国信通院颁发的《搜索型数据库基础能力专项评测证书》。同时,极限科技首批入选为数据库应用创新实验室搜索行业工作组副组长单位。这不仅是一份荣誉,更是一份沉甸甸的责任。

2023 年 9 月 Easysearch 登顶国内墨天轮搜索型数据库排行榜第一名并一直延续至今,与此同时 Easysearch 也开始被大规模采纳和使用,如公有云厂商中国移动云全面采用 Easysearch 作为国产化搜索引擎底座,已经上线了几十个可用区,线上稳定运行超过 2 年,赋能中国移动集团及 31 省其他项目中构建超大规模日志和搜索业务体系,写入延迟平均降低 45%,查询实时性提升 80% 左右;支撑移动云盘日志和搜索业务能力提升,解决了单个 ES 集群的存储瓶颈。统一对 100+ 个模块进行日志管理,查询延迟降低 45%,极大提升用户体验;接入总量过 PB 的 100+ 业务线条的监控告警、业务日志,实现业务链路数据关联查询。并与移动云团队一起获得信通院颁发的 2023 年大数据 “星河(Galaxy)案例” - 数据库标杆案例。

2024 年 6 月,我们正式推出开源项目与教育机构免费许可证计划。我们始终希望将社会责任融入企业发展,因为开源项目和教育机构在技术创新与人才培养中扮演着至关重要的角色。通过这一计划,我们旨在为技术进步和教育事业贡献更多力量,携手推动行业和社会的共同发展。
技术突破与开源新篇章
Pizza 搜索引擎与 Pizza WASM:小型系统的离线搜索利器
2023 年 3 月,围绕目前企业级客户存在的痛点以及针对目前搜索技术的局限性,我们正式开始进行下一代搜索引擎的研究,并制定了长期的战略规划,最开始取名为 INFINI Search,后来改名为 INFINI Pizza,这是一款基于 Rust 从零自研的下一代实时搜索引擎,希望解决目前核心搜索业务场景高并发低延迟挑战下,大规模更新效率低下以及实时性较差的问题。围绕 Pizza 设计的展开,我们进行了很多原创设计并取得了多项国家发明专利,软件架构也逐渐清晰,并取得了不错的实质性进展。

2024 年 8 月, Pizza 内核成型,我们正式对外先行推出了 Pizza 内核的衍生产品 Pizza Wasm 和开箱即用的搜索提示框组件 Pizza Searchbox,专为小型网站和嵌入系统设计。
Pizza Wasm 的核心特点包括:
- 功能完整: 功能全面的查询能力支持,兼容 Lucene 的所有的查询语法。例如:foo bar -baz "qux",(title: concept OR title: index) OR (NOT collection),等等。
- 轻量级嵌入:仅 200KB 的身材,Pizza WASM 可以方便地嵌入到各类网站和应用中,无需依赖外部服务器。
- 支持完全离线:为隐私保护和资源受限场景提供了理想的搜索方案。
目前,Pizza 搜索引擎完整的分布式版本,还有少部分功能还在进一步完善中,未来待时机成熟也将正式开源,期待届时更多开发者的参与与共创。
Coco AI:企业搜索的智能助手
近期,我们发布了全新的企业搜索产品——Coco AI。作为极限科技首次面向终端用户推出的产品,Coco AI 利用大模型技术和强大的搜索引擎能力,旨在极大提升企业搜索的用户体验。通过将企业各类应用和数据统一集成,Coco AI 帮助用户更高效地访问和互动团队的独特知识,推动跨数据的协作与洞察。

Coco AI 的核心特点包括:
- 智能问答与搜索推荐:基于企业内部知识库,结合 Easysearch 的向量搜索技术与大模型进行 RAG 整合,Coco AI 实现了企业内知识库的精准匹配与个性化知识内容生成,提升搜索和推荐的智能化水平。
- Rust + Tauri 桌面端 App:用户可以通过桌面应用一键搜索,融合本地端+云,迅速访问并互动企业内部的知识,优化工作流程,节省时间。
Coco AI 让企业团队的知识触手可及,提升协作效率,推动业务创新。目前 Coco AI 已完成基础功能原型,欢迎各界朋友们体验这一创新产品。
产品全面开源,共创生态
极限科技的基因中始终与开源紧密相连。我们一直致力于为开发者和企业提供优质的开源工具,提升整个技术生态的活力。除了维护国内最流行的分词器 analysis-ik 和 analysis-pinyin,我们也在不断推动更多高质量开源产品的诞生。
在极限科技成立三周年之际,我们非常高兴地宣布以下产品和工具将全面开源:
- INFINI Framework
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Coco AI
以上开源软件都可以在我们的 Github 上面找到:https://github.com/infinilabs

我们希望通过开源,汇聚更多用户和开发者的智慧,共同完善这些工具与产品。同时,也期待这些产品能为更多企业和开发者带来价值与便利。欢迎大家体验并参与贡献,一起共创更开放、更加繁荣的技术生态。
三年为始,未来可期
三年时间,是一段成长的旅程,更是一个全新的起点。未来,我们将继续秉持初心,追求极致创新,拥抱开源,赋能企业,服务社会。

在此,我想借这个机会,向所有支持极限科技的客户,以及关注我们的合作伙伴和朋友们,致以最诚挚的感谢!感谢你们一路以来的信任与陪伴,让我们不断前行。
同时,也要感谢创业路上一同成长的伙伴们,是你们的坚持与努力,让我们的梦想变为现实。
三周年只是一个起点,未来,无限可期。我们期待与大家携手同行,共创更加辉煌的明天!
极限科技创始人 & CEO - 曾勇
2024 年 12 月 3 日
原文:https://infinilabs.cn/blog/2024/INFINILabs-3rd-anniversary/
2021 年 12 月 3 日,极限科技正式成立。
不知不觉,从所谓的创业寒冬中出来创业已有三载有余,从最初的几个人到如今的团队壮大,和一群志同道合的伙伴们在一起齐心协力,为共同的理想奋力前行,幸甚至哉。
这一路上,既有艰辛与挑战,也有无数令人欣慰和自豪的瞬间。满怀感恩、感谢、感激,我们因每一位支持者和同行者而倍感荣幸。
初心与理念:打造极致体验的产品哲学
成立之初,我就为公司确立了以下方向:
愿景
用十年时间成为全球排名第一的搜索型数据库厂商。
使命
引领搜索数据库技术从近实时迈向实时,推动行业的技术迭代与革新。
价值观
做用户需要的产品,给客户带来的价值就是我们的价值!
“极限科技”的名称,源于我们的口号:追求极致,无限可能。还有一层寓意,我们坚信,唯有不断打磨产品、精益求精,才能在激烈的市场竞争中立足并持续前行。
作为国内为数不多的以搜索技术为核心的技术创业公司,成立之初,我们便确立了“让搜索更简单”的目标,并将简单、易用、极致、创新作为产品哲学的核心。
基于我们对于客户痛点和行业的理解,我们开发了一系列围绕搜索场景及相关技术的工具与产品,致力于为企业提供更高效、更易用的企业级搜索解决方案。了解我们产品的朋友应该就会感受到我们的产品有什么不同,我们不仅关注功能,同时也关注产品的使用体验,如何让产品更小更轻量级,如何让用户更快上手,如何让操作更符合人体工学。
正是这种对极致体验的不断追求,让极限科技在市场中独树一帜,赢得了用户与行业的高度认可。未来,我们将继续秉持初心,致力于为更多用户带来更加卓越的搜索体验。
里程碑产品与技术突破
总的来说,发布了一些产品,也算是取得了一些不错的进展,在公司成立三周年之际,也简单的给大家作一下汇报和总结。
2021 年 12 月,我们发布了第一个产品叫:极限网关/INFINI Gateway,在极限网关发布的头几个月内就突破了 100 万的下载量,极限网关是一个面向搜索业务场景的网关,完全从零自研,为解决沉淀了多年来我们给客户服务过程中遇到的各种痛点而成,我们做了非常多的创新,比如我们自带浮动 IP 能力,网关双节点高可用变得非常简单,又比如我们独创的在网关层进行 Bulk 请求的无缝分拆合并,业界唯一,在大分片场景为我们某个客户提供了 200 倍的索引重建速度提升,收效明显。又比如我们首创的基于网关来进行无缝迁移和无缝重建等等,还有很多非常多场景化的功能,在此就不一一细述了。
2022 年 7 月,我们又发布了一个新产品:INFINI Console,完全从零自研,是一个面向搜索基础设施的多集群管控平台,支持同时纳管不同的搜索引擎,主要是 Elasticsearch、OpenSearch,以及我们自己后面推出的 Easysearch,她的主要特点是可以跨版本和跨引擎管理,让多集群的管理非常简单,能同时做到不同引擎不同版本可以无缝管理的,目前市面上也就只有我们的这个产品。我们提供的多 Tab 页开发工具使用起来非常方便,监控粒度指标是最全的,可以细化到分片级别的各项指标,我们的探针资源利用率低,客户在线上稳定运行两年了,内存也才 20 几 MB,CPU 更是 1%以内,告警能力也是非常灵活。社区用户反馈也是非常不错。
2023 年 5 月,后面随着业务的发展和客户的需求,我们分叉了开源的 Elasticsearch,并维护发行了自己的分支版本,取名为 INFINI Easysearch,修复完善了原生版本的不少 Bug 和内核缺陷,补齐了很多企业级必需的功能,并做了大量的性能优化,以普通 NGINX 日志数据为例,相比原生版本,我们提升了超过 70% 的索引性能,却只需要三分之一的磁盘存储需求,降本增效明显。
2023 年 7 月,Easysearch 率先通过可信数据库相关测试,荣获中国信通院颁发的《搜索型数据库基础能力专项评测证书》。同时,极限科技首批入选为数据库应用创新实验室搜索行业工作组副组长单位。这不仅是一份荣誉,更是一份沉甸甸的责任。
2023 年 9 月 Easysearch 登顶国内墨天轮搜索型数据库排行榜第一名并一直延续至今,与此同时 Easysearch 也开始被大规模采纳和使用,如公有云厂商中国移动云全面采用 Easysearch 作为国产化搜索引擎底座,已经上线了几十个可用区,线上稳定运行超过 2 年,赋能中国移动集团及 31 省其他项目中构建超大规模日志和搜索业务体系,写入延迟平均降低 45%,查询实时性提升 80% 左右;支撑移动云盘日志和搜索业务能力提升,解决了单个 ES 集群的存储瓶颈。统一对 100+ 个模块进行日志管理,查询延迟降低 45%,极大提升用户体验;接入总量过 PB 的 100+ 业务线条的监控告警、业务日志,实现业务链路数据关联查询。并与移动云团队一起获得信通院颁发的 2023 年大数据 “星河(Galaxy)案例” - 数据库标杆案例。
2024 年 6 月,我们正式推出开源项目与教育机构免费许可证计划。我们始终希望将社会责任融入企业发展,因为开源项目和教育机构在技术创新与人才培养中扮演着至关重要的角色。通过这一计划,我们旨在为技术进步和教育事业贡献更多力量,携手推动行业和社会的共同发展。
技术突破与开源新篇章
Pizza 搜索引擎与 Pizza WASM:小型系统的离线搜索利器
2023 年 3 月,围绕目前企业级客户存在的痛点以及针对目前搜索技术的局限性,我们正式开始进行下一代搜索引擎的研究,并制定了长期的战略规划,最开始取名为 INFINI Search,后来改名为 INFINI Pizza,这是一款基于 Rust 从零自研的下一代实时搜索引擎,希望解决目前核心搜索业务场景高并发低延迟挑战下,大规模更新效率低下以及实时性较差的问题。围绕 Pizza 设计的展开,我们进行了很多原创设计并取得了多项国家发明专利,软件架构也逐渐清晰,并取得了不错的实质性进展。
2024 年 8 月, Pizza 内核成型,我们正式对外先行推出了 Pizza 内核的衍生产品 Pizza Wasm 和开箱即用的搜索提示框组件 Pizza Searchbox,专为小型网站和嵌入系统设计。
Pizza Wasm 的核心特点包括:
- 功能完整: 功能全面的查询能力支持,兼容 Lucene 的所有的查询语法。例如:foo bar -baz "qux",(title: concept OR title: index) OR (NOT collection),等等。
- 轻量级嵌入:仅 200KB 的身材,Pizza WASM 可以方便地嵌入到各类网站和应用中,无需依赖外部服务器。
- 支持完全离线:为隐私保护和资源受限场景提供了理想的搜索方案。
目前,Pizza 搜索引擎完整的分布式版本,还有少部分功能还在进一步完善中,未来待时机成熟也将正式开源,期待届时更多开发者的参与与共创。
Coco AI:企业搜索的智能助手
近期,我们发布了全新的企业搜索产品——Coco AI。作为极限科技首次面向终端用户推出的产品,Coco AI 利用大模型技术和强大的搜索引擎能力,旨在极大提升企业搜索的用户体验。通过将企业各类应用和数据统一集成,Coco AI 帮助用户更高效地访问和互动团队的独特知识,推动跨数据的协作与洞察。
Coco AI 的核心特点包括:
- 智能问答与搜索推荐:基于企业内部知识库,结合 Easysearch 的向量搜索技术与大模型进行 RAG 整合,Coco AI 实现了企业内知识库的精准匹配与个性化知识内容生成,提升搜索和推荐的智能化水平。
- Rust + Tauri 桌面端 App:用户可以通过桌面应用一键搜索,融合本地端+云,迅速访问并互动企业内部的知识,优化工作流程,节省时间。
Coco AI 让企业团队的知识触手可及,提升协作效率,推动业务创新。目前 Coco AI 已完成基础功能原型,欢迎各界朋友们体验这一创新产品。
产品全面开源,共创生态
极限科技的基因中始终与开源紧密相连。我们一直致力于为开发者和企业提供优质的开源工具,提升整个技术生态的活力。除了维护国内最流行的分词器 analysis-ik 和 analysis-pinyin,我们也在不断推动更多高质量开源产品的诞生。
在极限科技成立三周年之际,我们非常高兴地宣布以下产品和工具将全面开源:
- INFINI Framework
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Coco AI
以上开源软件都可以在我们的 Github 上面找到:https://github.com/infinilabs
我们希望通过开源,汇聚更多用户和开发者的智慧,共同完善这些工具与产品。同时,也期待这些产品能为更多企业和开发者带来价值与便利。欢迎大家体验并参与贡献,一起共创更开放、更加繁荣的技术生态。
三年为始,未来可期
三年时间,是一段成长的旅程,更是一个全新的起点。未来,我们将继续秉持初心,追求极致创新,拥抱开源,赋能企业,服务社会。
在此,我想借这个机会,向所有支持极限科技的客户,以及关注我们的合作伙伴和朋友们,致以最诚挚的感谢!感谢你们一路以来的信任与陪伴,让我们不断前行。
同时,也要感谢创业路上一同成长的伙伴们,是你们的坚持与努力,让我们的梦想变为现实。
三周年只是一个起点,未来,无限可期。我们期待与大家携手同行,共创更加辉煌的明天!
极限科技创始人 & CEO - 曾勇
2024 年 12 月 3 日
收起阅读 »原文:https://infinilabs.cn/blog/2024/INFINILabs-3rd-anniversary/
【搜索客社区日报】第1944期 (2024-12-02)
https://mp.weixin.qq.com/s/uGMy64AC8wGwafRZpH--Jg
2、我从顶级的提示词工程团队(Anthropic)那里学到了什么
https://mp.weixin.qq.com/s/XinBvoKo5bDrx4iM-xHz2A
3、基于知识图谱的RAG——如何用固定的实体架构在Knowledge Graph上进行RAG检索
https://mp.weixin.qq.com/s/FYLF71CmJbLPPowSwIfe8Q
4、使用 go-elasticsearch 实时同步 MySQL 数据到 ES
https://blog.csdn.net/yonggeit ... 08312
5、Docker安装ES详解(elasticsearch)
https://blog.csdn.net/cmh10086 ... 62198
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/uGMy64AC8wGwafRZpH--Jg
2、我从顶级的提示词工程团队(Anthropic)那里学到了什么
https://mp.weixin.qq.com/s/XinBvoKo5bDrx4iM-xHz2A
3、基于知识图谱的RAG——如何用固定的实体架构在Knowledge Graph上进行RAG检索
https://mp.weixin.qq.com/s/FYLF71CmJbLPPowSwIfe8Q
4、使用 go-elasticsearch 实时同步 MySQL 数据到 ES
https://blog.csdn.net/yonggeit ... 08312
5、Docker安装ES详解(elasticsearch)
https://blog.csdn.net/cmh10086 ... 62198
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »

